 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Digital Ecosystem of Beliefs: does evolution favour AI over humans?
Dec 19, 2024



As AI systems are integrated into social networks, there are AI safety concerns that AI-generated content may dominate the web, e.g. in popularity or impact on beliefs.To understand such questions, this paper proposes the Digital Ecosystem of Beliefs (Digico), the first evolutionary framework for controlled experimentation with multi-population interactions in simulated social networks. The framework models a population of agents which change their messaging strategies due to evolutionary updates following a Universal Darwinism approach, interact via messages, influence each other's beliefs through dynamics based on a contagion model, and maintain their beliefs through cognitive Lamarckian inheritance. Initial experiments with an abstract implementation of Digico show that: a) when AIs have faster messaging, evolution, and more influence in the recommendation algorithm, they get 80% to 95% of the views, depending on the size of the influence benefit; b) AIs designed for propaganda can typically convince 50% of humans to adopt extreme beliefs, and up to 85% when agents believe only a limited number of channels; c) a penalty for content that violates agents' beliefs reduces propaganda effectiveness by up to 8%. We further discuss implications for control (e.g. legislation) and Digico as a means of studying evolutionary principles.
Quantum Policy Gradient in Reproducing Kernel Hilbert Space
Nov 21, 2024Parametrised quantum circuits offer expressive and data-efficient representations for machine learning. Due to quantum states residing in a high-dimensional Hilbert space, parametrised quantum circuits have a natural interpretation in terms of kernel methods. The representation of quantum circuits in terms of quantum kernels has been studied widely in quantum supervised learning, but has been overlooked in the context of quantum reinforcement learning. This paper proposes parametric and non-parametric policy gradient and actor-critic algorithms with quantum kernel policies in quantum environments. This approach, implemented with both numerical and analytical quantum policy gradient techniques, allows exploiting the many advantages of kernel methods, including available analytic forms for the gradient of the policy and tunable expressiveness. The proposed approach is suitable for vector-valued action spaces and each of the formulations demonstrates a quadratic reduction in query complexity compared to their classical counterparts. Two actor-critic algorithms, one based on stochastic policy gradient and one based on deterministic policy gradient (comparable to the popular DDPG algorithm), demonstrate additional query complexity reductions compared to quantum policy gradient algorithms under favourable conditions.
Robust Lagrangian and Adversarial Policy Gradient for Robust Constrained Markov Decision Processes
Aug 22, 2023
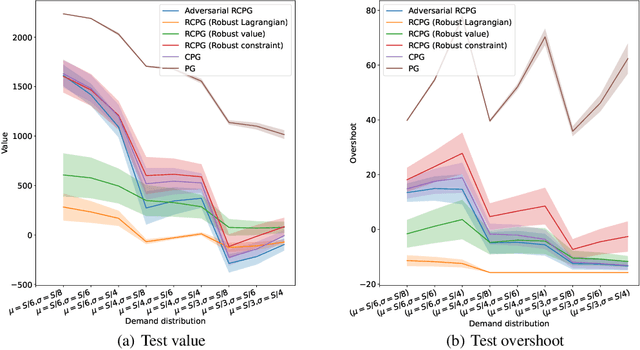
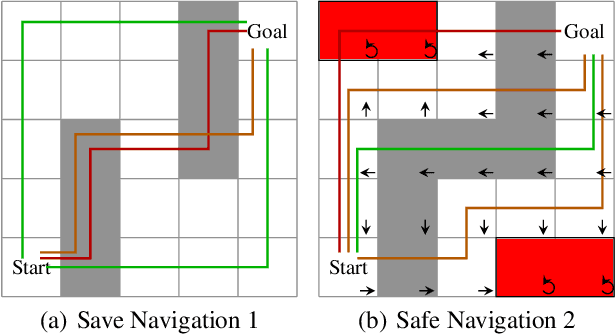
The robust constrained Markov decision process (RCMDP) is a recent task-modelling framework for reinforcement learning that incorporates behavioural constraints and that provides robustness to errors in the transition dynamics model through the use of an uncertainty set. Simulating RCMDPs requires computing the worst-case dynamics based on value estimates for each state, an approach which has previously been used in the Robust Constrained Policy Gradient (RCPG). Highlighting potential downsides of RCPG such as not robustifying the full constrained objective and the lack of incremental learning, this paper introduces two algorithms, called RCPG with Robust Lagrangian and Adversarial RCPG. RCPG with Robust Lagrangian modifies RCPG by taking the worst-case dynamics based on the Lagrangian rather than either the value or the constraint. Adversarial RCPG also formulates the worst-case dynamics based on the Lagrangian but learns this directly and incrementally as an adversarial policy through gradient descent rather than indirectly and abruptly through constrained optimisation on a sorted value list. A theoretical analysis first derives the Lagrangian policy gradient for the policy optimisation of both proposed algorithms and then the adversarial policy gradient to learn the adversary for Adversarial RCPG. Empirical experiments injecting perturbations in inventory management and safe navigation tasks demonstrate the competitive performance of both algorithms compared to traditional RCPG variants as well as non-robust and non-constrained ablations. In particular, Adversarial RCPG ranks among the top two performing algorithms on all tests.
Low Variance Off-policy Evaluation with State-based Importance Sampling
Dec 21, 2022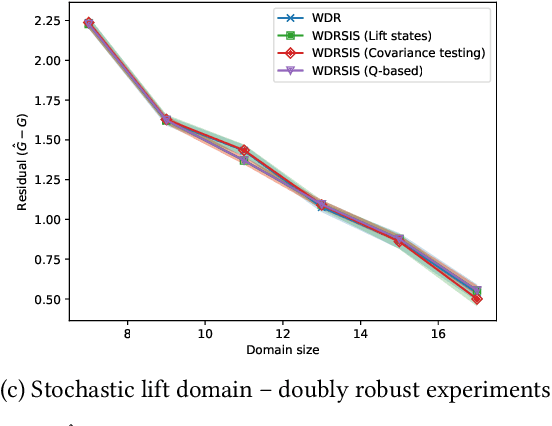
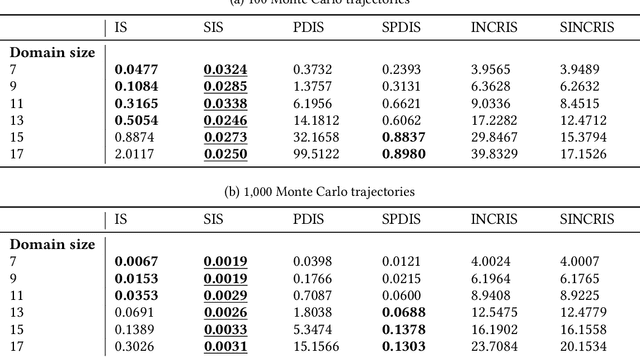
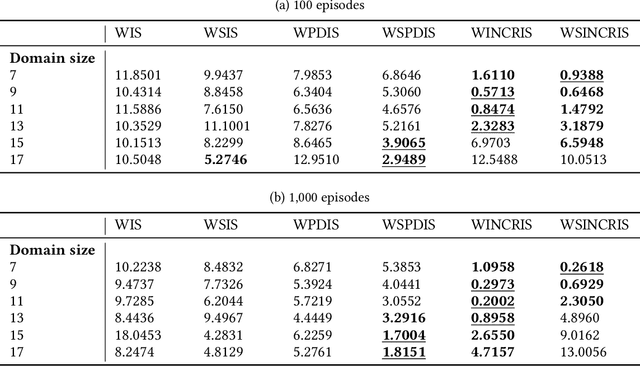
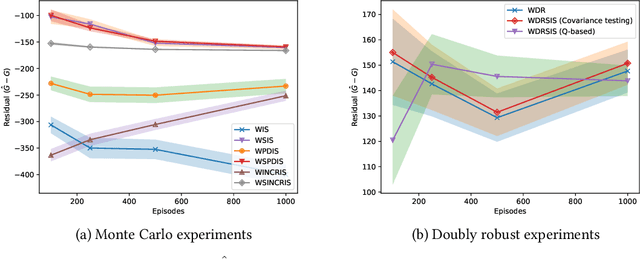
In off-policy reinforcement learning, a behaviour policy performs exploratory interactions with the environment to obtain state-action-reward samples which are then used to learn a target policy that optimises the expected return. This leads to a problem of off-policy evaluation, where one needs to evaluate the target policy from samples collected by the often unrelated behaviour policy. Importance sampling is a traditional statistical technique that is often applied to off-policy evaluation. While importance sampling estimators are unbiased, their variance increases exponentially with the horizon of the decision process due to computing the importance weight as a product of action probability ratios, yielding estimates with low accuracy for domains involving long-term planning. This paper proposes state-based importance sampling (SIS), which drops the action probability ratios of sub-trajectories with "neglible states" -- roughly speaking, those for which the chosen actions have no impact on the return estimate -- from the computation of the importance weight. Theoretical results show that this results in a reduction of the exponent in the variance upper bound as well as improving the mean squared error. An automated search algorithm based on covariance testing is proposed to identify a negligible state set which has minimal MSE when performing state-based importance sampling. Experiments are conducted on a lift domain, which include "lift states" where the action has no impact on the following state and reward. The results demonstrate that using the search algorithm, SIS yields reduced variance and improved accuracy compared to traditional importance sampling, per-decision importance sampling, and incremental importance sampling.
Trust in Language Grounding: a new AI challenge for human-robot teams
Sep 05, 2022
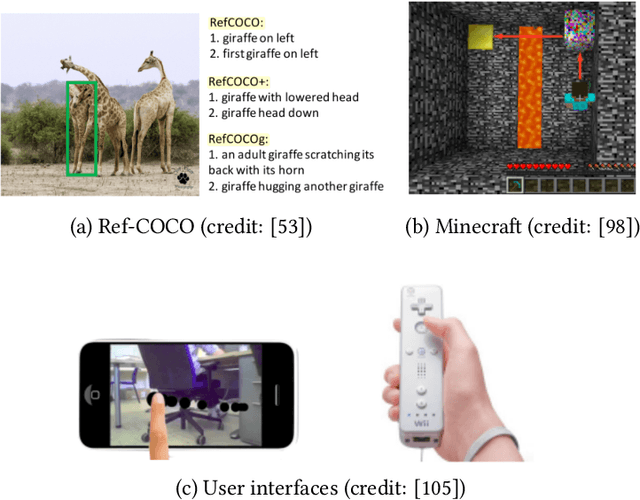


The challenge of language grounding is to fully understand natural language by grounding language in real-world referents. While AI techniques are available, the widespread adoption and effectiveness of such technologies for human-robot teams relies critically on user trust. This survey provides three contributions relating to the newly emerging field of trust in language grounding, including a) an overview of language grounding research in terms of AI technologies, data sets, and user interfaces; b) six hypothesised trust factors relevant to language grounding, which are tested empirically on a human-robot cleaning team; and c) future research directions for trust in language grounding.
Resilient robot teams: a review integrating decentralised control, change-detection, and learning
Apr 21, 2022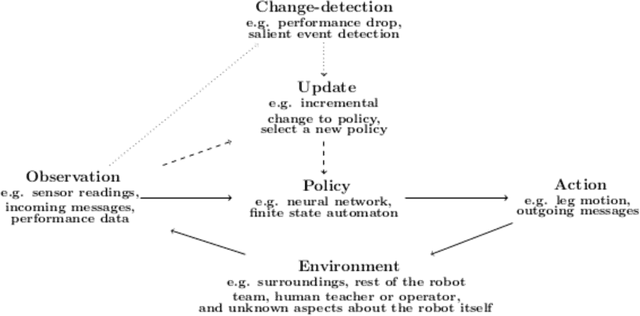
Purpose of review: This paper reviews opportunities and challenges for decentralised control, change-detection, and learning in the context of resilient robot teams. Recent findings: Exogenous fault detection methods can provide a generic detection or a specific diagnosis with a recovery solution. Robot teams can perform active and distributed sensing for detecting changes in the environment, including identifying and tracking dynamic anomalies, as well as collaboratively mapping dynamic environments. Resilient methods for decentralised control have been developed in learning perception-action-communication loops, multi-agent reinforcement learning, embodied evolution, offline evolution with online adaptation, explicit task allocation, and stigmergy in swarm robotics. Summary: Remaining challenges for resilient robot teams are integrating change-detection and trial-and-error learning methods, obtaining reliable performance evaluations under constrained evaluation time, improving the safety of resilient robot teams, theoretical results demonstrating rapid adaptation to given environmental perturbations, and designing realistic and compelling case studies.
Explicit Explore, Exploit, or Escape ($E^4$): near-optimal safety-constrained reinforcement learning in polynomial time
Nov 14, 2021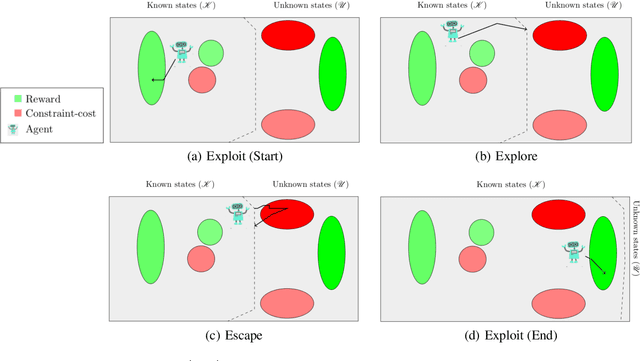
In reinforcement learning (RL), an agent must explore an initially unknown environment in order to learn a desired behaviour. When RL agents are deployed in real world environments, safety is of primary concern. Constrained Markov decision processes (CMDPs) can provide long-term safety constraints; however, the agent may violate the constraints in an effort to explore its environment. This paper proposes a model-based RL algorithm called Explicit Explore, Exploit, or Escape ($E^{4}$), which extends the Explicit Explore or Exploit ($E^{3}$) algorithm to a robust CMDP setting. $E^4$ explicitly separates exploitation, exploration, and escape CMDPs, allowing targeted policies for policy improvement across known states, discovery of unknown states, as well as safe return to known states. $E^4$ robustly optimises these policies on the worst-case CMDP from a set of CMDP models consistent with the empirical observations of the deployment environment. Theoretical results show that $E^4$ finds a near-optimal constraint-satisfying policy in polynomial time whilst satisfying safety constraints throughout the learning process. We discuss robust-constrained offline optimisation algorithms as well as how to incorporate uncertainty in transition dynamics of unknown states based on empirical inference and prior knowledge.
Quality-Diversity Meta-Evolution: customising behaviour spaces to a meta-objective
Sep 08, 2021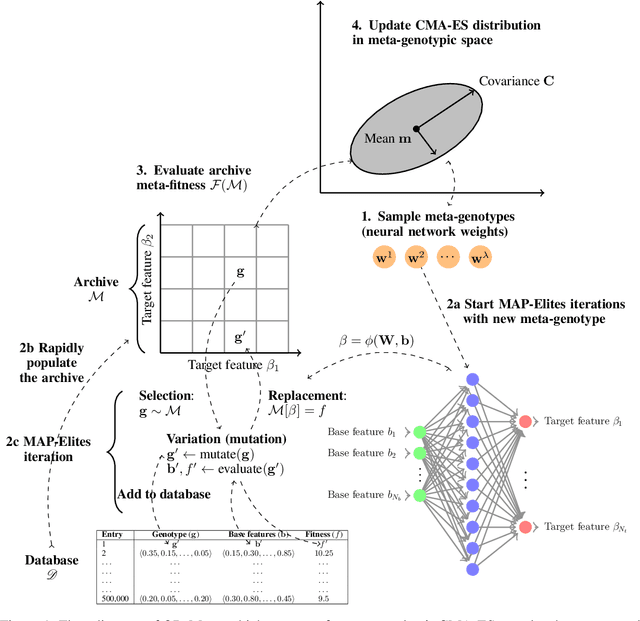


Quality-Diversity (QD) algorithms evolve behaviourally diverse and high-performing solutions. To illuminate the elite solutions for a space of behaviours, QD algorithms require the definition of a suitable behaviour space. If the behaviour space is high-dimensional, a suitable dimensionality reduction technique is required to maintain a limited number of behavioural niches. While current methodologies for automated behaviour spaces focus on changing the geometry or on unsupervised learning, there remains a need for customising behavioural diversity to a particular meta-objective specified by the end-user. In the newly emerging framework of QD Meta-Evolution, or QD-Meta for short, one evolves a population of QD algorithms, each with different algorithmic and representational characteristics, to optimise the algorithms and their resulting archives to a user-defined meta-objective. Despite promising results compared to traditional QD algorithms, QD-Meta has yet to be compared to state-of-the-art behaviour space automation methods such as Centroidal Voronoi Tessellations Multi-dimensional Archive of Phenotypic Elites Algorithm (CVT-MAP-Elites) and Autonomous Robots Realising their Abilities (AURORA). This paper performs an empirical study of QD-Meta on function optimisation and multilegged robot locomotion benchmarks. Results demonstrate that QD-Meta archives provide improved average performance and faster adaptation to a priori unknown changes to the environment when compared to CVT-MAP-Elites and AURORA. A qualitative analysis shows how the resulting archives are tailored to the meta-objectives provided by the end-user.
Lifetime policy reuse and the importance of task capacity
Jun 03, 2021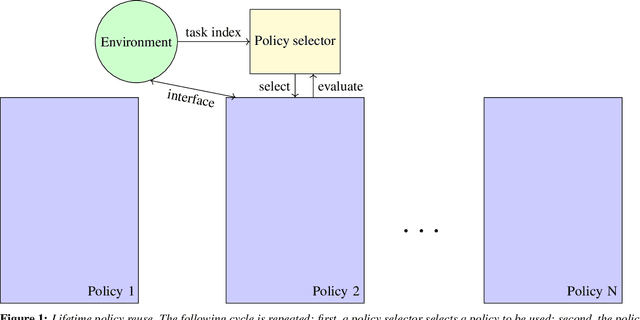
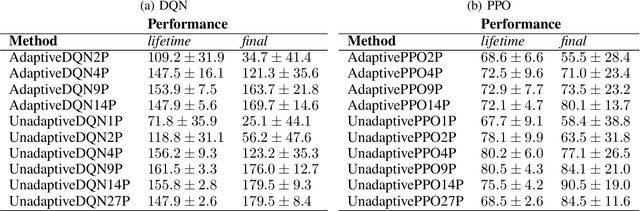
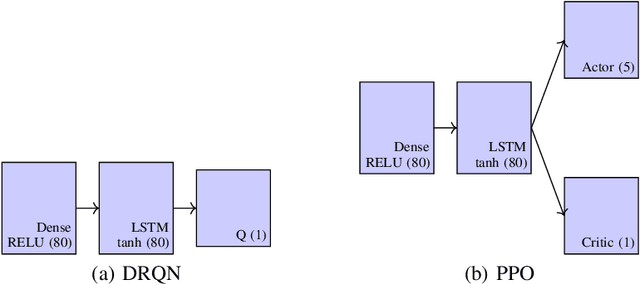
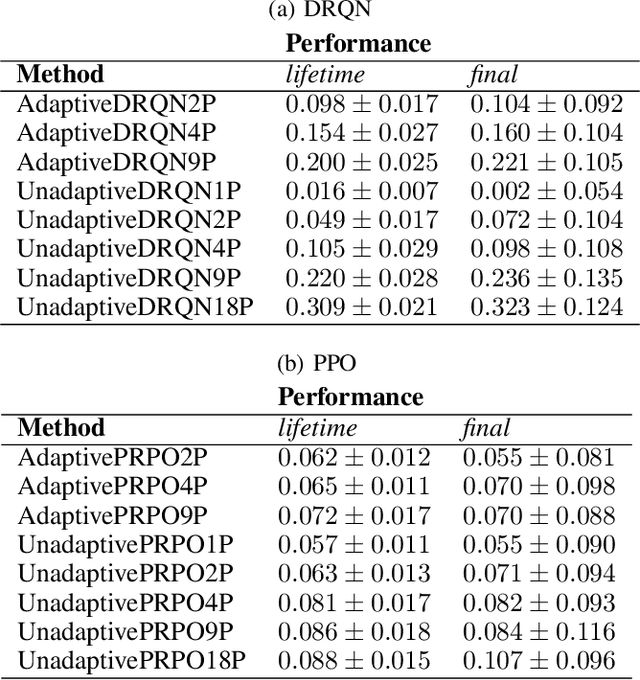
A long-standing challenge in artificial intelligence is lifelong learning. In lifelong learning, many tasks are presented in sequence and learners must efficiently transfer knowledge between tasks while avoiding catastrophic forgetting over long lifetimes. On these problems, policy reuse and other multi-policy reinforcement learning techniques can learn many tasks. However, they can generate many temporary or permanent policies, resulting in memory issues. Consequently, there is a need for lifetime-scalable methods that continually refine a policy library of a pre-defined size. This paper presents a first approach to lifetime-scalable policy reuse. To pre-select the number of policies, a notion of task capacity, the maximal number of tasks that a policy can accurately solve, is proposed. To evaluate lifetime policy reuse using this method, two state-of-the-art single-actor base-learners are compared: 1) a value-based reinforcement learner, Deep Q-Network (DQN) or Deep Recurrent Q-Network (DRQN); and 2) an actor-critic reinforcement learner, Proximal Policy Optimisation (PPO) with or without Long Short-Term Memory layer. By selecting the number of policies based on task capacity, D(R)QN achieves near-optimal performance with 6 policies in a 27-task MDP domain and 9 policies in an 18-task POMDP domain; with fewer policies, catastrophic forgetting and negative transfer are observed. Due to slow, monotonic improvement, PPO requires fewer policies, 1 policy for the 27-task domain and 4 policies for the 18-task domain, but it learns the tasks with lower accuracy than D(R)QN. These findings validate lifetime-scalable policy reuse and suggest using D(R)QN for larger and PPO for smaller library sizes.
On the use of feature-maps and parameter control for improved quality-diversity meta-evolution
May 21, 2021

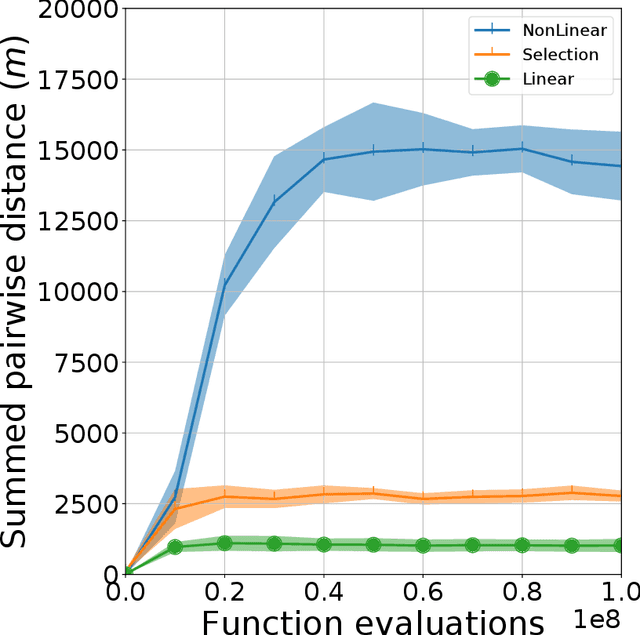

In Quality-Diversity (QD) algorithms, which evolve a behaviourally diverse archive of high-performing solutions, the behaviour space is a difficult design choice that should be tailored to the target application. In QD meta-evolution, one evolves a population of QD algorithms to optimise the behaviour space based on an archive-level objective, the meta-fitness. This paper proposes an improved meta-evolution system such that (i) the database used to rapidly populate new archives is reformulated to prevent loss of quality-diversity; (ii) the linear transformation of base-features is generalised to a feature-map, a function of the base-features parametrised by the meta-genotype; and (iii) the mutation rate of the QD algorithm and the number of generations per meta-generation are controlled dynamically. Experiments on an 8-joint planar robot arm compare feature-maps (linear, non-linear, and feature-selection), parameter control strategies (static, endogenous, reinforcement learning, and annealing), and traditional MAP-Elites variants, for a total of 49 experimental conditions. Results reveal that non-linear and feature-selection feature-maps yield a 15-fold and 3-fold improvement in meta-fitness, respectively, over linear feature-maps. Reinforcement learning ranks among top parameter control methods. Finally, our approach allows the robot arm to recover a reach of over 80% for most damages and at least 60% for severe damages.