 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Variance Off-policy Evaluation with State-based Importance Sampling
Paper and Code
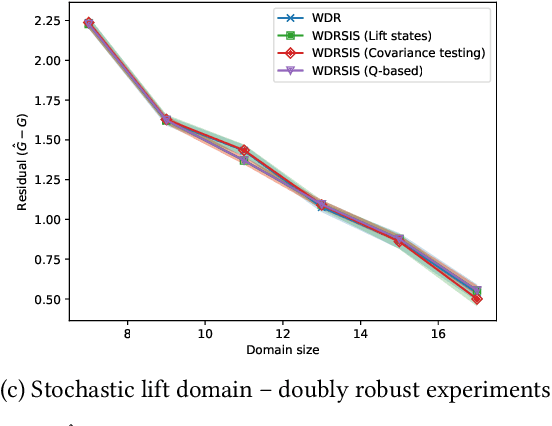
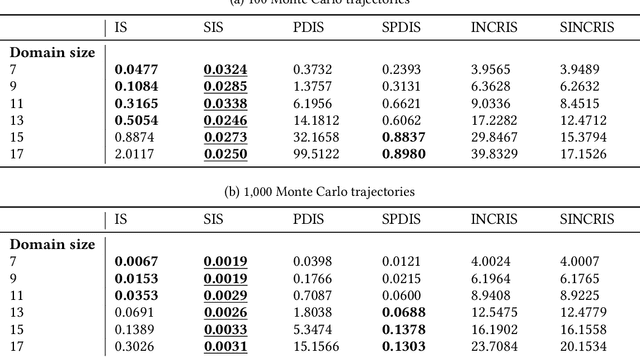
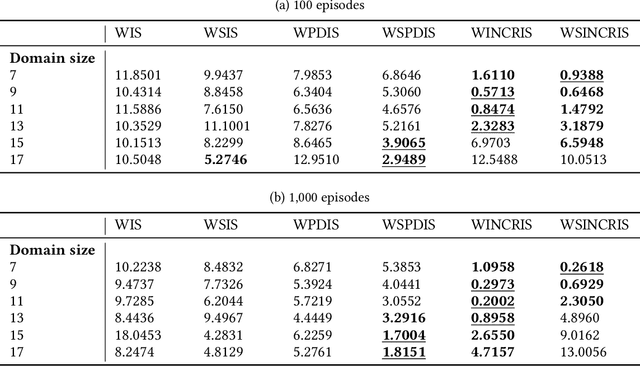
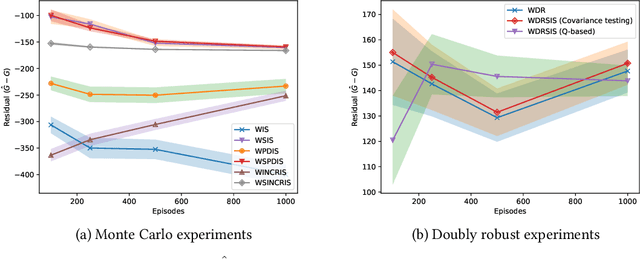
In off-policy reinforcement learning, a behaviour policy performs exploratory interactions with the environment to obtain state-action-reward samples which are then used to learn a target policy that optimises the expected return. This leads to a problem of off-policy evaluation, where one needs to evaluate the target policy from samples collected by the often unrelated behaviour policy. Importance sampling is a traditional statistical technique that is often applied to off-policy evaluation. While importance sampling estimators are unbiased, their variance increases exponentially with the horizon of the decision process due to computing the importance weight as a product of action probability ratios, yielding estimates with low accuracy for domains involving long-term planning. This paper proposes state-based importance sampling (SIS), which drops the action probability ratios of sub-trajectories with "neglible states" -- roughly speaking, those for which the chosen actions have no impact on the return estimate -- from the computation of the importance weight. Theoretical results show that this results in a reduction of the exponent in the variance upper bound as well as improving the mean squared error. An automated search algorithm based on covariance testing is proposed to identify a negligible state set which has minimal MSE when performing state-based importance sampling. Experiments are conducted on a lift domain, which include "lift states" where the action has no impact on the following state and reward. The results demonstrate that using the search algorithm, SIS yields reduced variance and improved accuracy compared to traditional importance sampling, per-decision importance sampling, and incremental importance sampling.