 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriver Profiling and Bayesian Workload Estimation Using Naturalistic Peripheral Detection Study Data
Mar 26, 2023



Monitoring drivers' mental workload facilitates initiating and maintaining safe interactions with in-vehicle information systems, and thus delivers adaptive human machine interaction with reduced impact on the primary task of driving. In this paper, we tackle the problem of workload estimation from driving performance data. First, we present a novel on-road study for collecting subjective workload data via a modified peripheral detection task in naturalistic settings. Key environmental factors that induce a high mental workload are identified via video analysis, e.g. junctions and behaviour of vehicle in front. Second, a supervised learning framework using state-of-the-art time series classifiers (e.g. convolutional neural network and transform techniques) is introduced to profile drivers based on the average workload they experience during a journey. A Bayesian filtering approach is then proposed for sequentially estimating, in (near) real-time, the driver's instantaneous workload. This computationally efficient and flexible method can be easily personalised to a driver (e.g. incorporate their inferred average workload profile), adapted to driving/environmental contexts (e.g. road type) and extended with data streams from new sources. The efficacy of the presented profiling and instantaneous workload estimation approaches are demonstrated using the on-road study data, showing $F_{1}$ scores of up to 92% and 81%, respectively.
Asymptotically Unbiased Off-Policy Policy Evaluation when Reusing Old Data in Nonstationary Environments
Feb 23, 2023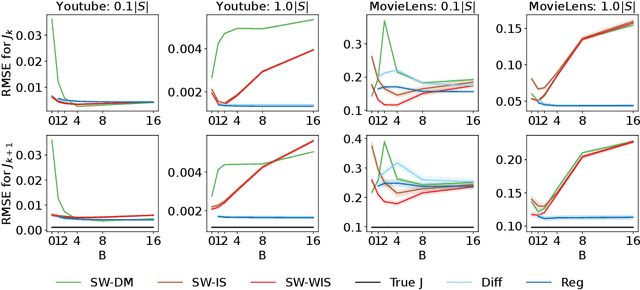
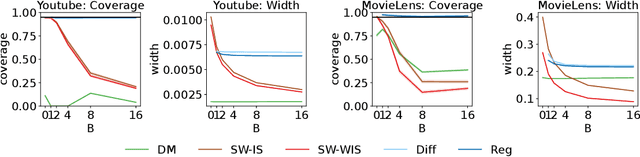
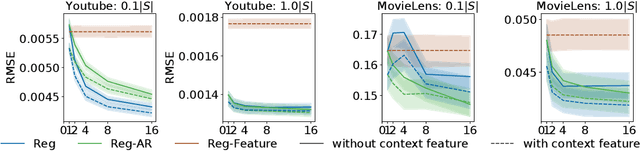
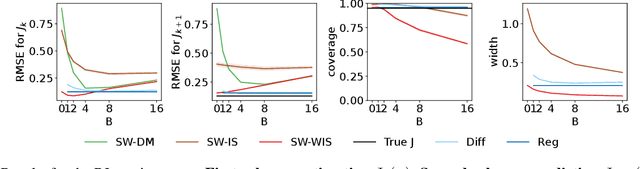
In this work, we consider the off-policy policy evaluation problem for contextual bandits and finite horizon reinforcement learning in the nonstationary setting. Reusing old data is critical for policy evaluation, but existing estimators that reuse old data introduce large bias such that we can not obtain a valid confidence interval. Inspired from a related field called survey sampling, we introduce a variant of the doubly robust (DR) estimator, called the regression-assisted DR estimator, that can incorporate the past data without introducing a large bias. The estimator unifies several existing off-policy policy evaluation methods and improves on them with the use of auxiliary information and a regression approach. We prove that the new estimator is asymptotically unbiased, and provide a consistent variance estimator to a construct a large sample confidence interval. Finally, we empirically show that the new estimator improves estimation for the current and future policy values, and provides a tight and valid interval estimation in several nonstationary recommendation environments.
Low Variance Off-policy Evaluation with State-based Importance Sampling
Dec 21, 2022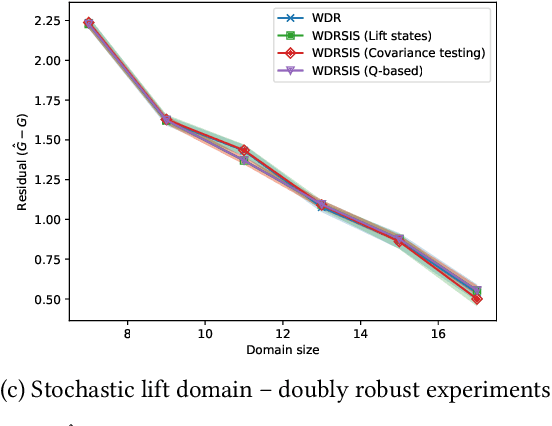
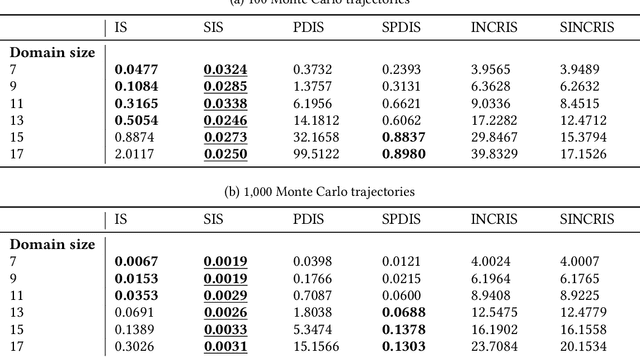
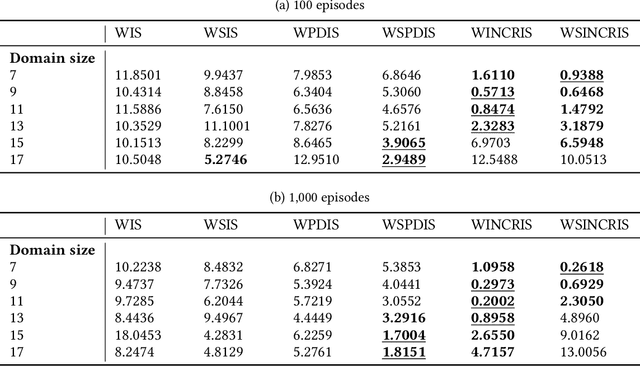
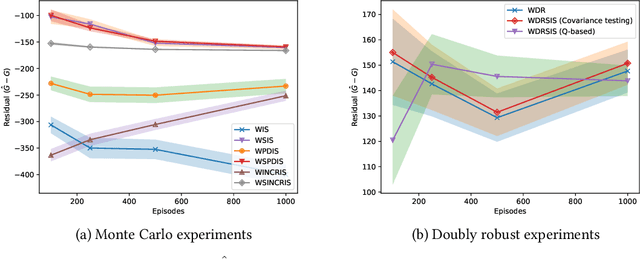
In off-policy reinforcement learning, a behaviour policy performs exploratory interactions with the environment to obtain state-action-reward samples which are then used to learn a target policy that optimises the expected return. This leads to a problem of off-policy evaluation, where one needs to evaluate the target policy from samples collected by the often unrelated behaviour policy. Importance sampling is a traditional statistical technique that is often applied to off-policy evaluation. While importance sampling estimators are unbiased, their variance increases exponentially with the horizon of the decision process due to computing the importance weight as a product of action probability ratios, yielding estimates with low accuracy for domains involving long-term planning. This paper proposes state-based importance sampling (SIS), which drops the action probability ratios of sub-trajectories with "neglible states" -- roughly speaking, those for which the chosen actions have no impact on the return estimate -- from the computation of the importance weight. Theoretical results show that this results in a reduction of the exponent in the variance upper bound as well as improving the mean squared error. An automated search algorithm based on covariance testing is proposed to identify a negligible state set which has minimal MSE when performing state-based importance sampling. Experiments are conducted on a lift domain, which include "lift states" where the action has no impact on the following state and reward. The results demonstrate that using the search algorithm, SIS yields reduced variance and improved accuracy compared to traditional importance sampling, per-decision importance sampling, and incremental importance sampling.
Proximal Reinforcement Learning: A New Theory of Sequential Decision Making in Primal-Dual Spaces
May 26, 2014
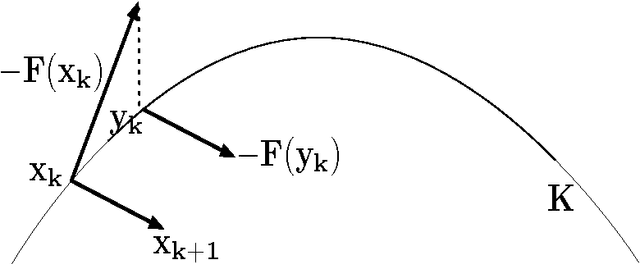
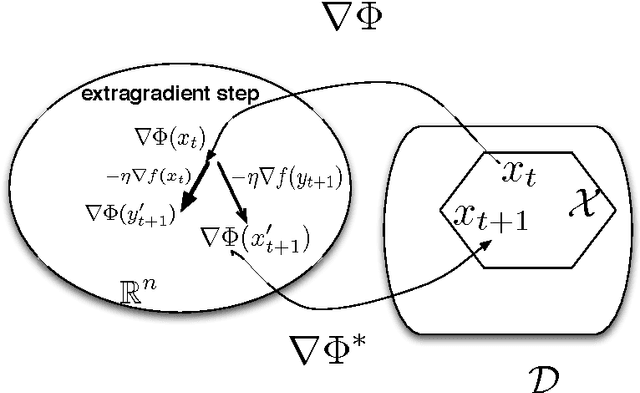
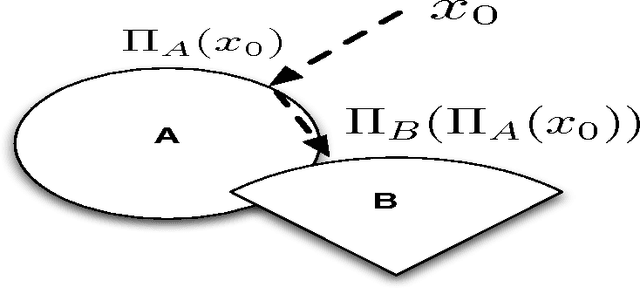
In this paper, we set forth a new vision of reinforcement learning developed by us over the past few years, one that yields mathematically rigorous solutions to longstanding important questions that have remained unresolved: (i) how to design reliable, convergent, and robust reinforcement learning algorithms (ii) how to guarantee that reinforcement learning satisfies pre-specified "safety" guarantees, and remains in a stable region of the parameter space (iii) how to design "off-policy" temporal difference learning algorithms in a reliable and stable manner, and finally (iv) how to integrate the study of reinforcement learning into the rich theory of stochastic optimization. In this paper, we provide detailed answers to all these questions using the powerful framework of proximal operators. The key idea that emerges is the use of primal dual spaces connected through the use of a Legendre transform. This allows temporal difference updates to occur in dual spaces, allowing a variety of important technical advantages. The Legendre transform elegantly generalizes past algorithms for solving reinforcement learning problems, such as natural gradient methods, which we show relate closely to the previously unconnected framework of mirror descent methods. Equally importantly, proximal operator theory enables the systematic development of operator splitting methods that show how to safely and reliably decompose complex products of gradients that occur in recent variants of gradient-based temporal difference learning. This key technical innovation makes it possible to finally design "true" stochastic gradient methods for reinforcement learning. Finally, Legendre transforms enable a variety of other benefits, including modeling sparsity and domain geometry. Our work builds extensively on recent work on the convergence of saddle-point algorithms, and on the theory of monotone operators.