 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Rebatching for Efficient Early-Exit Inference with DREX
Dec 17, 2025Early-Exit (EE) is a Large Language Model (LLM) architecture that accelerates inference by allowing easier tokens to be generated using only a subset of the model's layers. However, traditional batching frameworks are ill-suited for EE LLMs, as not all requests in a batch may be ready to exit at the same time. Existing solutions either force a uniform decision on the batch, which overlooks EE opportunities, or degrade output quality by forcing premature exits. We propose Dynamic Rebatching, a solution where we dynamically reorganize the batch at each early-exit point. Requests that meet the exit criteria are immediately processed, while those that continue are held in a buffer, re-grouped into a new batch, and forwarded to deeper layers. We introduce DREX, an early-exit inference system that implements Dynamic Rebatching with two key optimizations: 1) a copy-free rebatching buffer that avoids physical data movement, and 2) an EE and SLA-aware scheduler that analytically predicts whether a given rebatching operation will be profitable. DREX also efficiently handles the missing KV cache from skipped layers using memory-efficient state-copying. Our evaluation shows that DREX improves throughput by 2-12% compared to baseline approaches while maintaining output quality. Crucially, DREX completely eliminates involuntary exits, providing a key guarantee for preserving the output quality intended by the EE model.
EgoZero: Robot Learning from Smart Glasses
May 26, 2025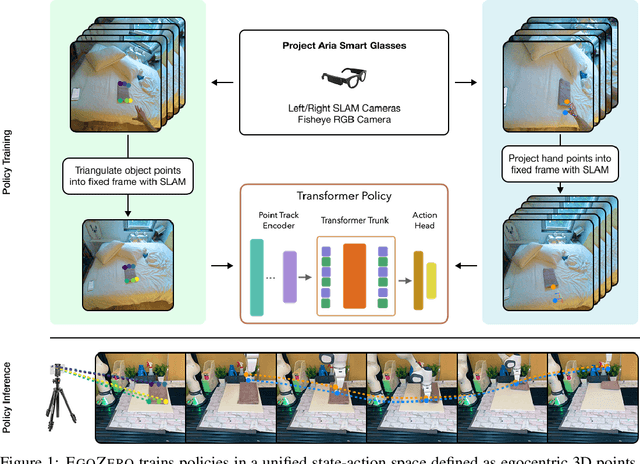
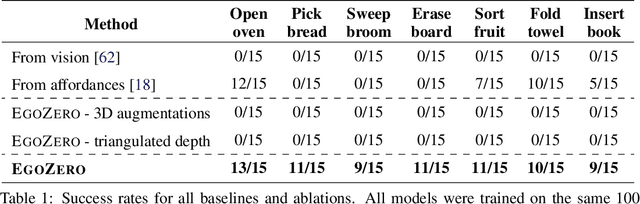

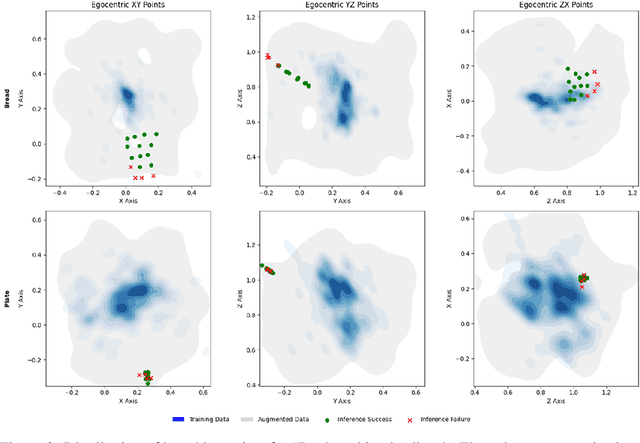
Despite recent progress in general purpose robotics, robot policies still lag far behind basic human capabilities in the real world. Humans interact constantly with the physical world, yet this rich data resource remains largely untapped in robot learning. We propose EgoZero, a minimal system that learns robust manipulation policies from human demonstrations captured with Project Aria smart glasses, $\textbf{and zero robot data}$. EgoZero enables: (1) extraction of complete, robot-executable actions from in-the-wild, egocentric, human demonstrations, (2) compression of human visual observations into morphology-agnostic state representations, and (3) closed-loop policy learning that generalizes morphologically, spatially, and semantically. We deploy EgoZero policies on a gripper Franka Panda robot and demonstrate zero-shot transfer with 70% success rate over 7 manipulation tasks and only 20 minutes of data collection per task. Our results suggest that in-the-wild human data can serve as a scalable foundation for real-world robot learning - paving the way toward a future of abundant, diverse, and naturalistic training data for robots. Code and videos are available at https://egozero-robot.github.io.
Carbon Connect: An Ecosystem for Sustainable Computing
May 22, 2024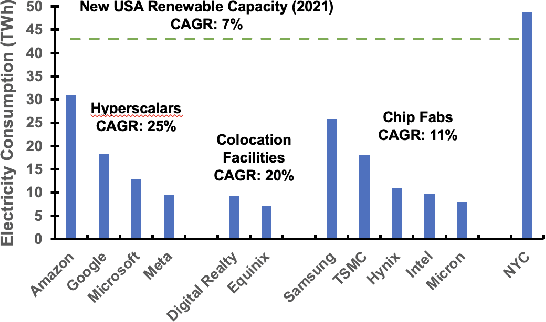
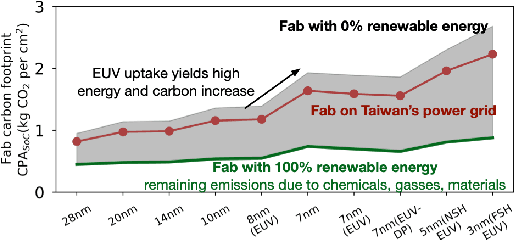
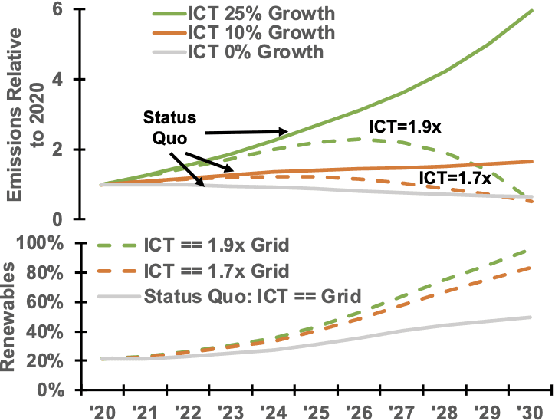
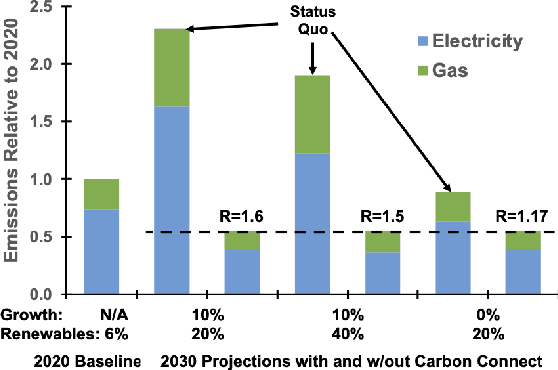
Computing is at a moment of profound opportunity. Emerging applications -- such as capable artificial intelligence, immersive virtual realities, and pervasive sensor systems -- drive unprecedented demand for computer. Despite recent advances toward net zero carbon emissions, the computing industry's gross energy usage continues to rise at an alarming rate, outpacing the growth of new energy installations and renewable energy deployments. A shift towards sustainability is needed to spark a transformation in how computer systems are manufactured, allocated, and consumed. Carbon Connect envisions coordinated research thrusts that produce design and management strategies for sustainable, next-generation computer systems. These strategies must flatten and then reverse growth trajectories for computing power and carbon for society's most rapidly growing applications such as artificial intelligence and virtual spaces. We will require accurate models for carbon accounting in computing technology. For embodied carbon, we must re-think conventional design strategies -- over-provisioned monolithic servers, frequent hardware refresh cycles, custom silicon -- and adopt life-cycle design strategies that more effectively reduce, reuse and recycle hardware at scale. For operational carbon, we must not only embrace renewable energy but also design systems to use that energy more efficiently. Finally, new hardware design and management strategies must be cognizant of economic policy and regulatory landscape, aligning private initiatives with societal goals. Many of these broader goals will require computer scientists to develop deep, enduring collaborations with researchers in economics, law, and industrial ecology to spark change in broader practice.
Switching the Loss Reduces the Cost in Batch Reinforcement Learning
Mar 12, 2024
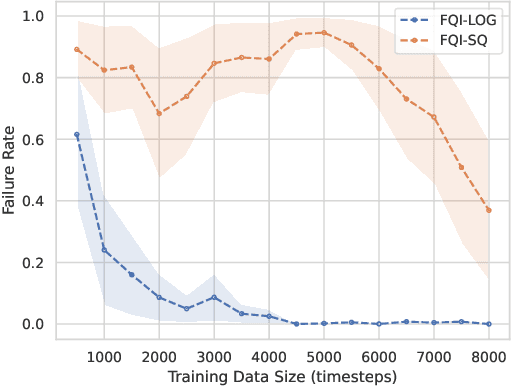
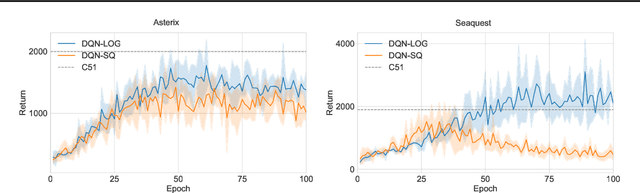
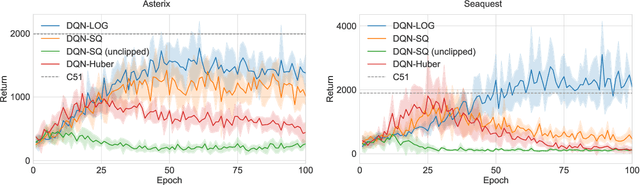
We propose training fitted Q-iteration with log-loss (FQI-LOG) for batch reinforcement learning (RL). We show that the number of samples needed to learn a near-optimal policy with FQI-LOG scales with the accumulated cost of the optimal policy, which is zero in problems where acting optimally achieves the goal and incurs no cost. In doing so, we provide a general framework for proving $\textit{small-cost}$ bounds, i.e. bounds that scale with the optimal achievable cost, in batch RL. Moreover, we empirically verify that FQI-LOG uses fewer samples than FQI trained with squared loss on problems where the optimal policy reliably achieves the goal.
Under the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.
When is Offline Policy Selection Sample Efficient for Reinforcement Learning?
Dec 04, 2023



Offline reinforcement learning algorithms often require careful hyperparameter tuning. Consequently, before deployment, we need to select amongst a set of candidate policies. As yet, however, there is little understanding about the fundamental limits of this offline policy selection (OPS) problem. In this work we aim to provide clarity on when sample efficient OPS is possible, primarily by connecting OPS to off-policy policy evaluation (OPE) and Bellman error (BE) estimation. We first show a hardness result, that in the worst case, OPS is just as hard as OPE, by proving a reduction of OPE to OPS. As a result, no OPS method can be more sample efficient than OPE in the worst case. We then propose a BE method for OPS, called Identifiable BE Selection (IBES), that has a straightforward method for selecting its own hyperparameters. We highlight that using IBES for OPS generally has more requirements than OPE methods, but if satisfied, can be more sample efficient. We conclude with an empirical study comparing OPE and IBES, and by showing the difficulty of OPS on an offline Atari benchmark dataset.
Measuring and Mitigating Interference in Reinforcement Learning
Jul 10, 2023



Catastrophic interference is common in many network-based learning systems, and many proposals exist for mitigating it. Before overcoming interference we must understand it better. In this work, we provide a definition and novel measure of interference for value-based reinforcement learning methods such as Fitted Q-Iteration and DQN. We systematically evaluate our measure of interference, showing that it correlates with instability in control performance, across a variety of network architectures. Our new interference measure allows us to ask novel scientific questions about commonly used deep learning architectures and study learning algorithms which mitigate interference. Lastly, we outline a class of algorithms which we call online-aware that are designed to mitigate interference, and show they do reduce interference according to our measure and that they improve stability and performance in several classic control environments.
Asymptotically Unbiased Off-Policy Policy Evaluation when Reusing Old Data in Nonstationary Environments
Feb 23, 2023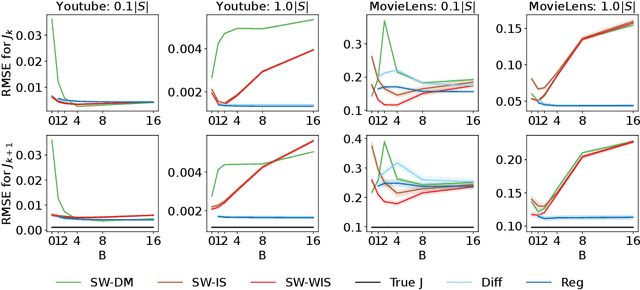
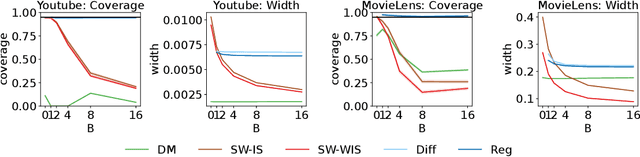
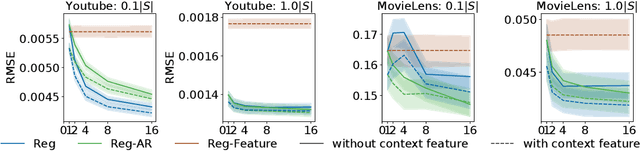
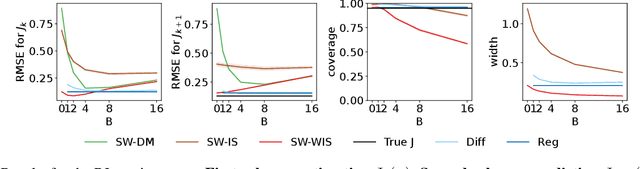
In this work, we consider the off-policy policy evaluation problem for contextual bandits and finite horizon reinforcement learning in the nonstationary setting. Reusing old data is critical for policy evaluation, but existing estimators that reuse old data introduce large bias such that we can not obtain a valid confidence interval. Inspired from a related field called survey sampling, we introduce a variant of the doubly robust (DR) estimator, called the regression-assisted DR estimator, that can incorporate the past data without introducing a large bias. The estimator unifies several existing off-policy policy evaluation methods and improves on them with the use of auxiliary information and a regression approach. We prove that the new estimator is asymptotically unbiased, and provide a consistent variance estimator to a construct a large sample confidence interval. Finally, we empirically show that the new estimator improves estimation for the current and future policy values, and provides a tight and valid interval estimation in several nonstationary recommendation environments.
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
Feb 22, 2023Model parallelism is conventionally viewed as a method to scale a single large deep learning model beyond the memory limits of a single device. In this paper, we demonstrate that model parallelism can be additionally used for the statistical multiplexing of multiple devices when serving multiple models, even when a single model can fit into a single device. Our work reveals a fundamental trade-off between the overhead introduced by model parallelism and the opportunity to exploit statistical multiplexing to reduce serving latency in the presence of bursty workloads. We explore the new trade-off space and present a novel serving system, AlpaServe, that determines an efficient strategy for placing and parallelizing collections of large deep learning models across a distributed cluster. Evaluation results on production workloads show that AlpaServe can process requests at up to 10x higher rates or 6x more burstiness while staying within latency constraints for more than 99% of requests.
No More Pesky Hyperparameters: Offline Hyperparameter Tuning for RL
May 18, 2022
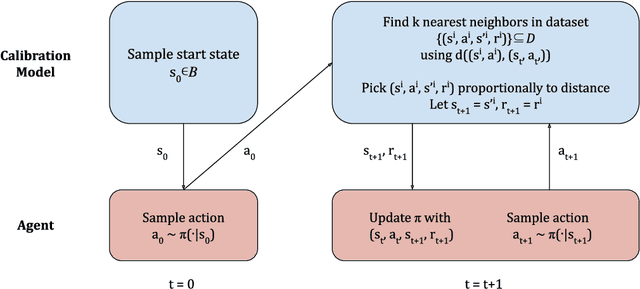
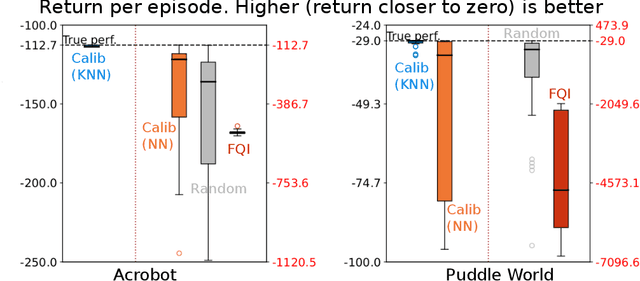
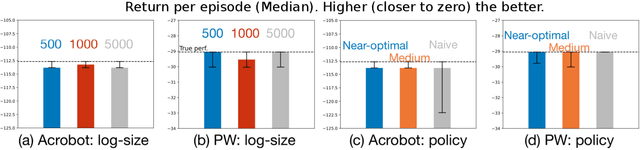
The performance of reinforcement learning (RL) agents is sensitive to the choice of hyperparameters. In real-world settings like robotics or industrial control systems, however, testing different hyperparameter configurations directly on the environment can be financially prohibitive, dangerous, or time consuming. We propose a new approach to tune hyperparameters from offline logs of data, to fully specify the hyperparameters for an RL agent that learns online in the real world. The approach is conceptually simple: we first learn a model of the environment from the offline data, which we call a calibration model, and then simulate learning in the calibration model to identify promising hyperparameters. We identify several criteria to make this strategy effective, and develop an approach that satisfies these criteria. We empirically investigate the method in a variety of settings to identify when it is effective and when it fails.