 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More Pesky Hyperparameters: Offline Hyperparameter Tuning for RL
May 18, 2022
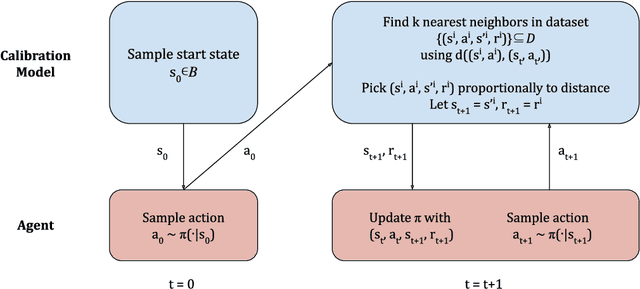
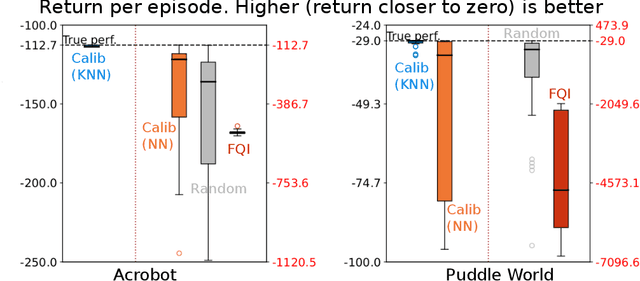
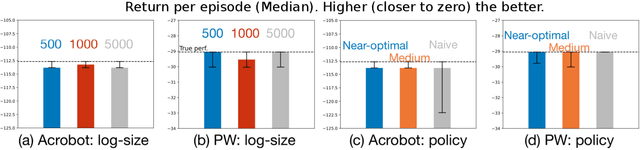
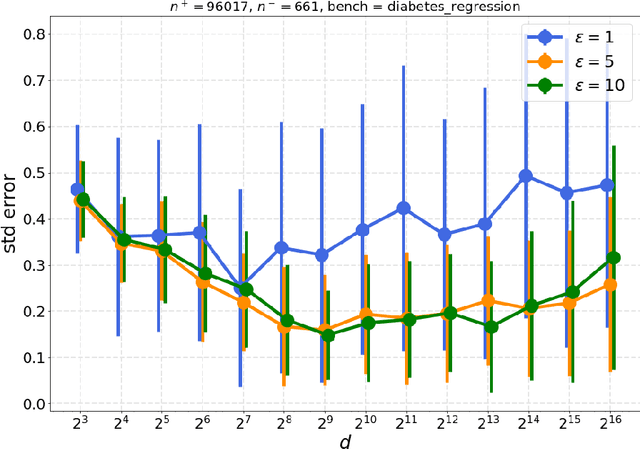
The performance of reinforcement learning (RL) agents is sensitive to the choice of hyperparameters. In real-world settings like robotics or industrial control systems, however, testing different hyperparameter configurations directly on the environment can be financially prohibitive, dangerous, or time consuming. We propose a new approach to tune hyperparameters from offline logs of data, to fully specify the hyperparameters for an RL agent that learns online in the real world. The approach is conceptually simple: we first learn a model of the environment from the offline data, which we call a calibration model, and then simulate learning in the calibration model to identify promising hyperparameters. We identify several criteria to make this strategy effective, and develop an approach that satisfies these criteria. We empirically investigate the method in a variety of settings to identify when it is effective and when it fails.
MPC-Friendly Commitments for Publicly Verifiable Covert Security
Sep 15, 2021



We address the problem of efficiently verifying a commitment in a two-party computation. This addresses the scenario where a party P1 commits to a value $x$ to be used in a subsequent secure computation with another party P2 that wants to receive assurance that P1 did not cheat, i.e. that $x$ was indeed the value inputted into the secure computation. Our constructions operate in the publicly verifiable covert (PVC) security model, which is a relaxation of the malicious model of MPC appropriate in settings where P1 faces a reputational harm if caught cheating. We introduce the notion of PVC commitment scheme and indexed hash functions to build commitments schemes tailored to the PVC framework, and propose constructions for both arithmetic and Boolean circuits that result in very efficient circuits. From a practical standpoint, our constructions for Boolean circuits are $60\times$ faster to evaluate securely, and use $36\times$ less communication than baseline methods based on hashing. Moreover, we show that our constructions are tight in terms of required non-linear operations, by proving lower bounds on the nonlinear gate count of commitment verification circuits. Finally, we present a technique to amplify the security properties our constructions that allows to efficiently recover malicious guarantees with statistical security.
Integrating Novelty Detection Capabilities with MSL Mastcam Operations to Enhance Data Analysis
Mar 23, 2021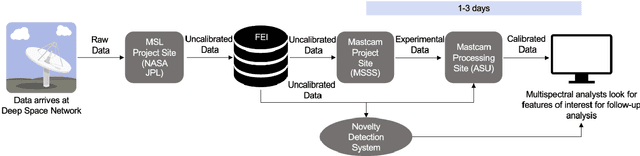



While innovations in scientific instrumentation have pushed the boundaries of Mars rover mission capabilities, the increase in data complexity has pressured Mars Science Laboratory (MSL) and future Mars rover operations staff to quickly analyze complex data sets to meet progressively shorter tactical and strategic planning timelines. MSLWEB is an internal data tracking tool used by operations staff to perform first pass analysis on MSL image sequences, a series of products taken by the Mast camera, Mastcam. Mastcam's multiband multispectral image sequences require more complex analysis compared to standard 3-band RGB images. Typically, these are analyzed using traditional methods to identify unique features within the sequence. Given the short time frame of tactical planning in which downlinked images might need to be analyzed (within 5-10 hours before the next uplink), there exists a need to triage analysis time to focus on the most important sequences and parts of a sequence. We address this need by creating products for MSLWEB that use novelty detection to help operations staff identify unusual data that might be diagnostic of new or atypical compositions or mineralogies detected within an imaging scene. This was achieved in two ways: 1) by creating products for each sequence to identify novel regions in the image, and 2) by assigning multispectral sequences a sortable novelty score. These new products provide colorized heat maps of inferred novelty that operations staff can use to rapidly review downlinked data and focus their efforts on analyzing potentially new kinds of diagnostic multispectral signatures. This approach has the potential to guide scientists to new discoveries by quickly drawing their attention to often subtle variations not detectable with simple color composites.
Private Protocols for U-Statistics in the Local Model and Beyond
Oct 09, 2019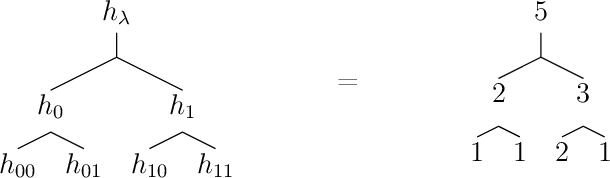

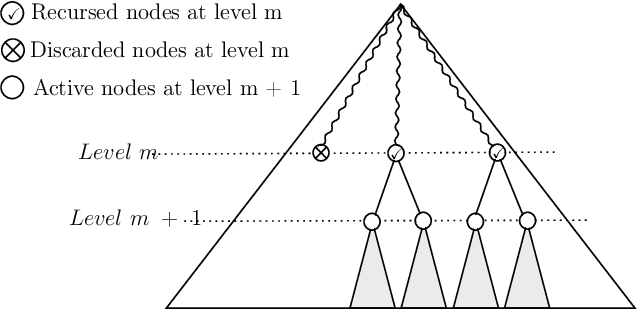
In this paper, we study the problem of computing $U$-statistics of degree $2$, i.e., quantities that come in the form of averages over pairs of data points, in the local model of differential privacy (LDP). The class of $U$-statistics covers many statistical estimates of interest, including Gini mean difference, Kendall's tau coefficient and Area under the ROC Curve (AUC), as well as empirical risk measures for machine learning problems such as ranking, clustering and metric learning. We first introduce an LDP protocol based on quantizing the data into bins and applying randomized response, which guarantees an $\epsilon$-LDP estimate with a Mean Squared Error (MSE) of $O(1/\sqrt{n}\epsilon)$ under regularity assumptions on the $U$-statistic or the data distribution. We then propose a specialized protocol for AUC based on a novel use of hierarchical histograms that achieves MSE of $O(\alpha^3/n\epsilon^2)$ for arbitrary data distribution. We also show that 2-party secure computation allows to design a protocol with MSE of $O(1/n\epsilon^2)$, without any assumption on the kernel function or data distribution and with total communication linear in the number of users $n$. Finally, we evaluate the performance of our protocols through experiments on synthetic and real datasets.
Differentially Private Summation with Multi-Message Shuffling
Jun 24, 2019In recent work, Cheu et al. (Eurocrypt 2019) proposed a protocol for $n$-party real summation in the shuffle model of differential privacy with $O_{\epsilon, \delta}(1)$ error and $\Theta(\epsilon\sqrt{n})$ one-bit messages per party. In contrast, every local model protocol for real summation must incur error $\Omega(1/\sqrt{n})$, and there exist protocols matching this lower bound which require just one bit of communication per party. Whether this gap in number of messages is necessary was left open by Cheu et al. In this note we show a protocol with $O(1/\epsilon)$ error and $O(\log(n/\delta))$ messages of size $O(\log(n))$ per party. This protocol is based on the work of Ishai et al.\ (FOCS 2006) showing how to implement distributed summation from secure shuffling, and the observation that this allows simulating the Laplace mechanism in the shuffle model.
The Privacy Blanket of the Shuffle Model
Mar 07, 2019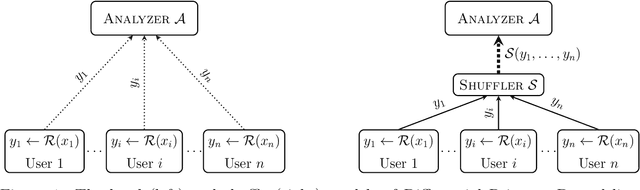
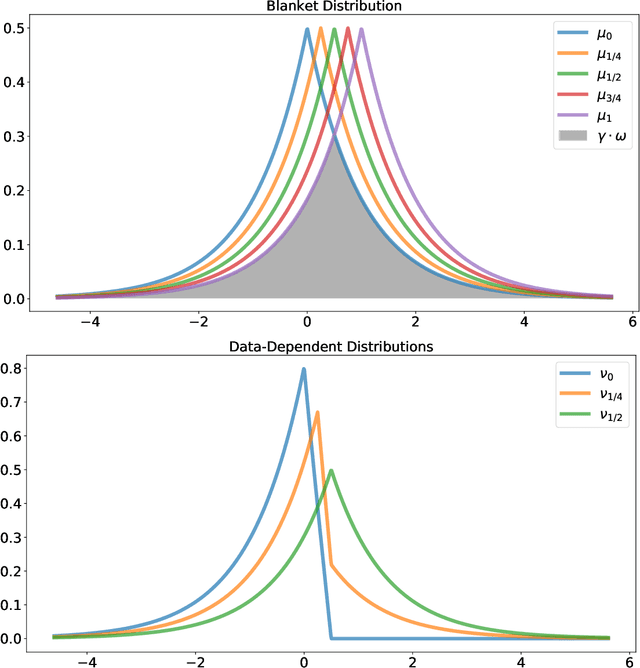
This work studies differential privacy in the context of the recently proposed shuffle model. Unlike in the local model, where the server collecting privatized data from users can track back an input to a specific user, in the shuffle model users submit their privatized inputs to a server anonymously. This setup yields a trust model which sits in between the classical curator and local models for differential privacy. The shuffle model is the core idea in the Encode, Shuffle, Analyze (ESA) model introduced by Bittau et al. (SOPS 2017). Recent work by Cheu et al. (Forthcoming, EUROCRYPT 2019) analyzes the differential privacy properties of the shuffle model and shows that in some cases shuffled protocols provide strictly better accuracy than local protocols. Additionally, Erlignsson et al. (SODA 2019) provide a privacy amplification bound quantifying the level of curator differential privacy achieved by the shuffle model in terms of the local differential privacy of the randomizer used by each user. In this context, we make three contributions. First, we provide an optimal single message protocol for summation of real numbers in the shuffle model. Our protocol is very simple and has better accuracy and communication than the protocols for this same problem proposed by Cheu et al. Optimality of this protocol follows from our second contribution, a new lower bound for the accuracy of private protocols for summation of real numbers in the shuffle model. The third contribution is a new amplification bound for analyzing the privacy of protocols in the shuffle model in terms of the privacy provided by the corresponding local randomizer. Our amplification bound generalizes the results by Erlingsson et al. to a wider range of parameters, and provides a whole family of methods to analyze privacy amplification in the shuffle model.