 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy Analysis of Decentralized Gossip Averaging under Varying Threat Models
May 26, 2025Fully decentralized training of machine learning models offers significant advantages in scalability, robustness, and fault tolerance. However, achieving differential privacy (DP) in such settings is challenging due to the absence of a central aggregator and varying trust assumptions among nodes. In this work, we present a novel privacy analysis of decentralized gossip-based averaging algorithms with additive node-level noise, both with and without secure summation over each node's direct neighbors. Our main contribution is a new analytical framework based on a linear systems formulation that accurately characterizes privacy leakage across these scenarios. This framework significantly improves upon prior analyses, for example, reducing the R\'enyi DP parameter growth from $O(T^2)$ to $O(T)$, where $T$ is the number of training rounds. We validate our analysis with numerical results demonstrating superior DP bounds compared to existing approaches. We further illustrate our analysis with a logistic regression experiment on MNIST image classification in a fully decentralized setting, demonstrating utility comparable to central aggregation methods.
Practical Differentially Private Hyperparameter Tuning with Subsampling
Jan 27, 2023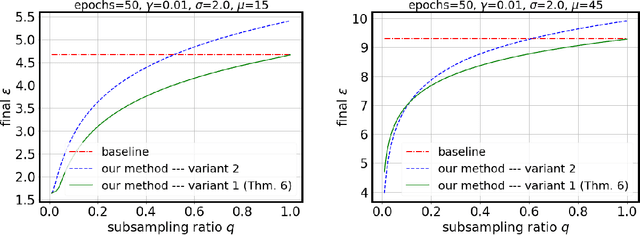

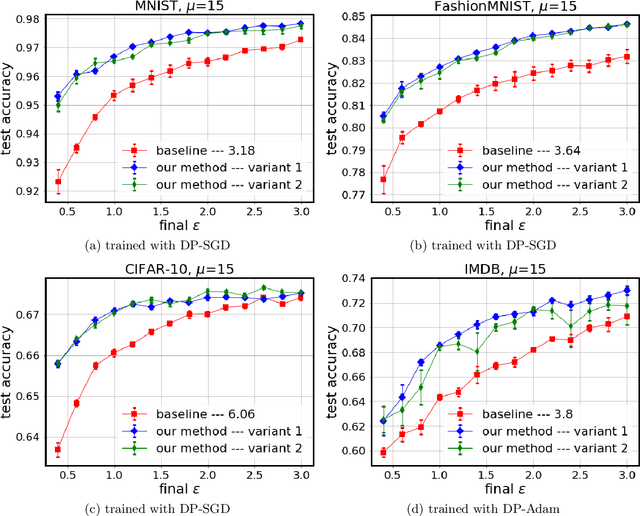

Tuning all the hyperparameters of differentially private (DP) machine learning (ML) algorithms often requires use of sensitive data and this may leak private information via hyperparameter values. Recently, Papernot and Steinke (2022) proposed a certain class of DP hyperparameter tuning algorithms, where the number of random search samples is randomized itself. Commonly, these algorithms still considerably increase the DP privacy parameter $\varepsilon$ over non-tuned DP ML model training and can be computationally heavy as evaluating each hyperparameter candidate requires a new training run. We focus on lowering both the DP bounds and the computational complexity of these methods by using only a random subset of the sensitive data for the hyperparameter tuning and by extrapolating the optimal values from the small dataset to a larger dataset. We provide a R\'enyi differential privacy analysis for the proposed method and experimentally show that it consistently leads to better privacy-utility trade-off than the baseline method by Papernot and Steinke (2022).
Locally Differentially Private Bayesian Inference
Oct 27, 2021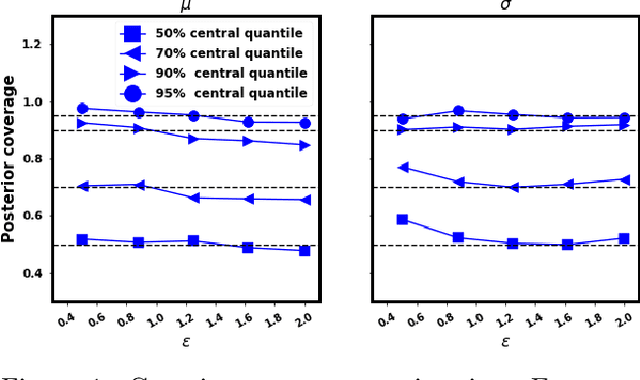
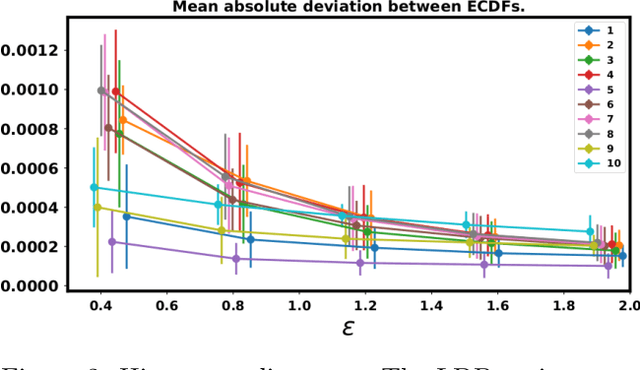
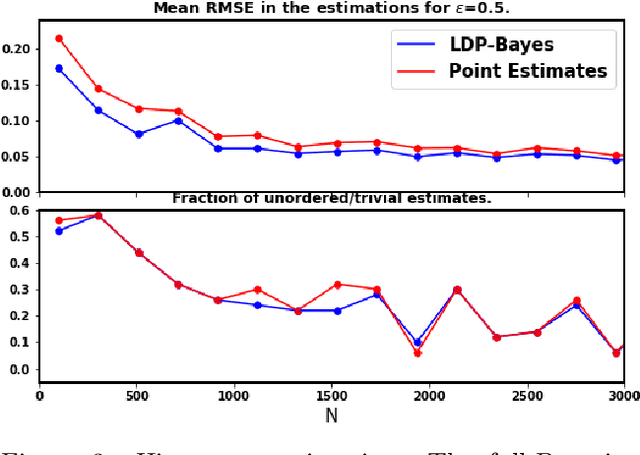
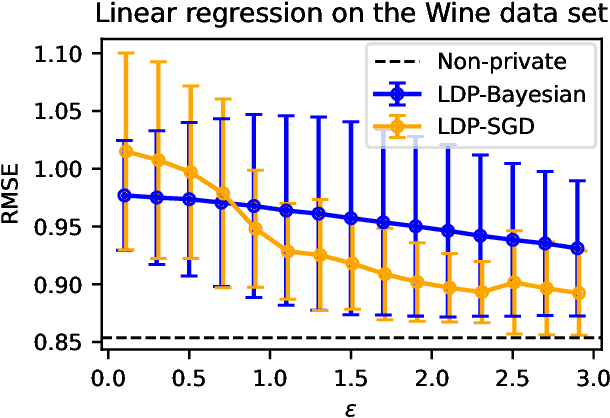
In recent years, local differential privacy (LDP) has emerged as a technique of choice for privacy-preserving data collection in several scenarios when the aggregator is not trustworthy. LDP provides client-side privacy by adding noise at the user's end. Thus, clients need not rely on the trustworthiness of the aggregator. In this work, we provide a noise-aware probabilistic modeling framework, which allows Bayesian inference to take into account the noise added for privacy under LDP, conditioned on locally perturbed observations. Stronger privacy protection (compared to the central model) provided by LDP protocols comes at a much harsher privacy-utility trade-off. Our framework tackles several computational and statistical challenges posed by LDP for accurate uncertainty quantification under Bayesian settings. We demonstrate the efficacy of our framework in parameter estimation for univariate and multi-variate distributions as well as logistic and linear regression.
Differentially Private Bayesian Inference for Generalized Linear Models
Nov 09, 2020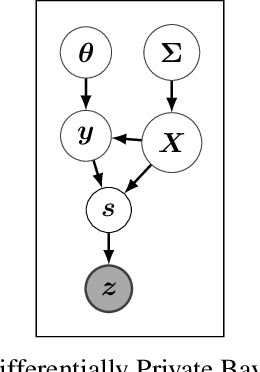
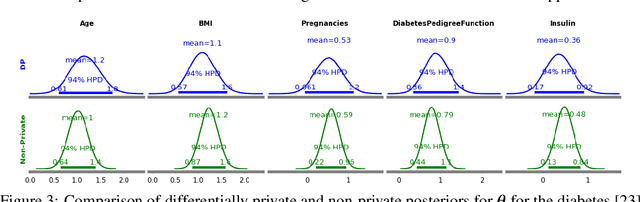
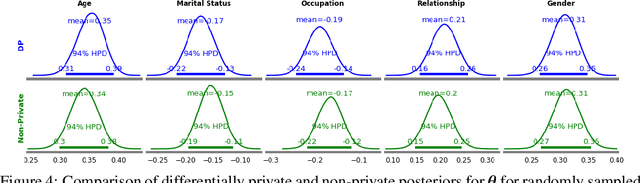
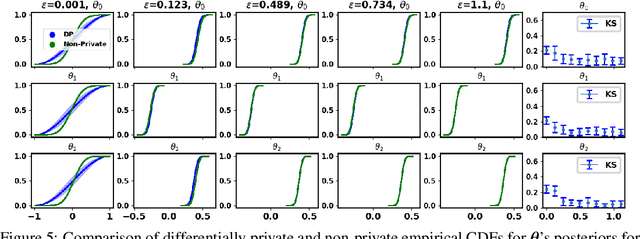
The framework of differential privacy (DP) upper bounds the information disclosure risk involved in using sensitive datasets for statistical analysis. A DP mechanism typically operates by adding carefully calibrated noise to the data release procedure. Generalized linear models (GLMs) are among the most widely used arms in data analyst's repertoire. In this work, with logistic and Poisson regression as running examples, we propose a generic noise-aware Bayesian framework to quantify the parameter uncertainty for a GLM at hand, given noisy sufficient statistics. We perform a tight privacy analysis and experimentally demonstrate that the posteriors obtained from our model, while adhering to strong privacy guarantees, are similar to the non-private posteriors.
Representation Matters: Improving Perception and Exploration for Robotics
Nov 03, 2020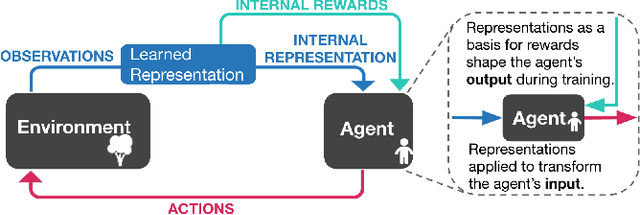
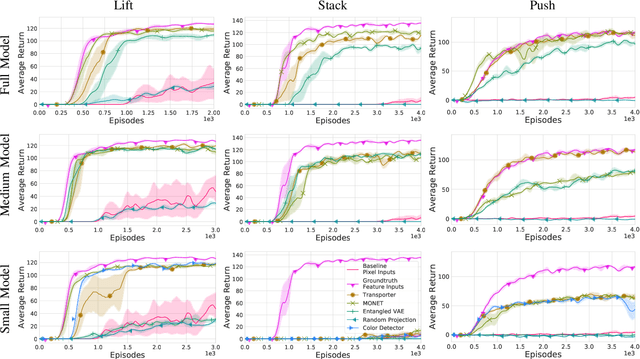

Projecting high-dimensional environment observations into lower-dimensional structured representations can considerably improve data-efficiency for reinforcement learning in domains with limited data such as robotics. Can a single generally useful representation be found? In order to answer this question, it is important to understand how the representation will be used by the agent and what properties such a 'good' representation should have. In this paper we systematically evaluate a number of common learnt and hand-engineered representations in the context of three robotics tasks: lifting, stacking and pushing of 3D blocks. The representations are evaluated in two use-cases: as input to the agent, or as a source of auxiliary tasks. Furthermore, the value of each representation is evaluated in terms of three properties: dimensionality, observability and disentanglement. We can significantly improve performance in both use-cases and demonstrate that some representations can perform commensurate to simulator states as agent inputs. Finally, our results challenge common intuitions by demonstrating that: 1) dimensionality strongly matters for task generation, but is negligible for inputs, 2) observability of task-relevant aspects mostly affects the input representation use-case, and 3) disentanglement leads to better auxiliary tasks, but has only limited benefits for input representations. This work serves as a step towards a more systematic understanding of what makes a 'good' representation for control in robotics, enabling practitioners to make more informed choices for developing new learned or hand-engineered representations.
Private Protocols for U-Statistics in the Local Model and Beyond
Oct 09, 2019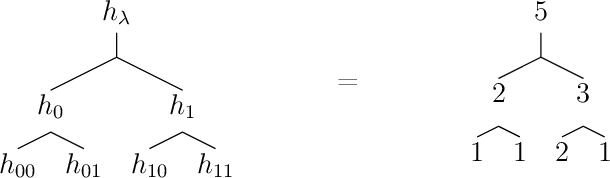

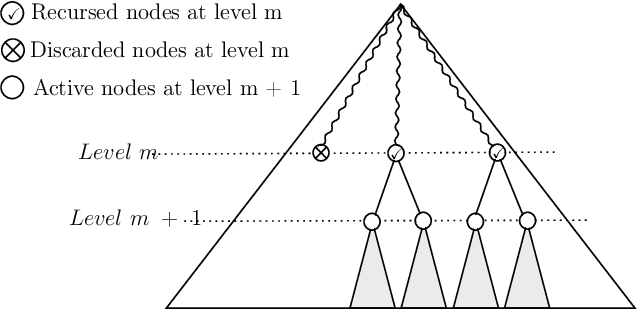
In this paper, we study the problem of computing $U$-statistics of degree $2$, i.e., quantities that come in the form of averages over pairs of data points, in the local model of differential privacy (LDP). The class of $U$-statistics covers many statistical estimates of interest, including Gini mean difference, Kendall's tau coefficient and Area under the ROC Curve (AUC), as well as empirical risk measures for machine learning problems such as ranking, clustering and metric learning. We first introduce an LDP protocol based on quantizing the data into bins and applying randomized response, which guarantees an $\epsilon$-LDP estimate with a Mean Squared Error (MSE) of $O(1/\sqrt{n}\epsilon)$ under regularity assumptions on the $U$-statistic or the data distribution. We then propose a specialized protocol for AUC based on a novel use of hierarchical histograms that achieves MSE of $O(\alpha^3/n\epsilon^2)$ for arbitrary data distribution. We also show that 2-party secure computation allows to design a protocol with MSE of $O(1/n\epsilon^2)$, without any assumption on the kernel function or data distribution and with total communication linear in the number of users $n$. Finally, we evaluate the performance of our protocols through experiments on synthetic and real datasets.
Unsupervised Doodling and Painting with Improved SPIRAL
Oct 02, 2019
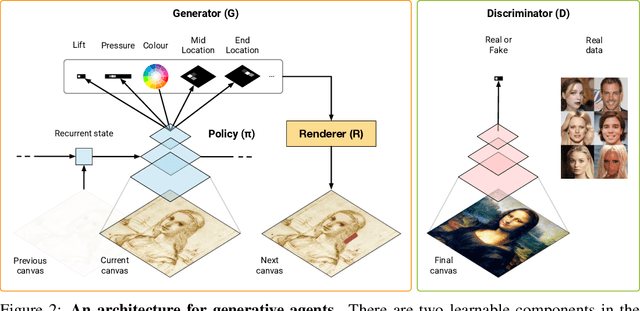


We investigate using reinforcement learning agents as generative models of images (extending arXiv:1804.01118). A generative agent controls a simulated painting environment, and is trained with rewards provided by a discriminator network simultaneously trained to assess the realism of the agent's samples, either unconditional or reconstructions. Compared to prior work, we make a number of improvements to the architectures of the agents and discriminators that lead to intriguing and at times surprising results. We find that when sufficiently constrained, generative agents can learn to produce images with a degree of visual abstraction, despite having only ever seen real photographs (no human brush strokes). And given enough time with the painting environment, they can produce images with considerable realism. These results show that, under the right circumstances, some aspects of human drawing can emerge from simulated embodiment, without the need for external supervision, imitation or social cues. Finally, we note the framework's potential for use in creative applications.
Unsupervised Learning of Object Keypoints for Perception and Control
Jun 19, 2019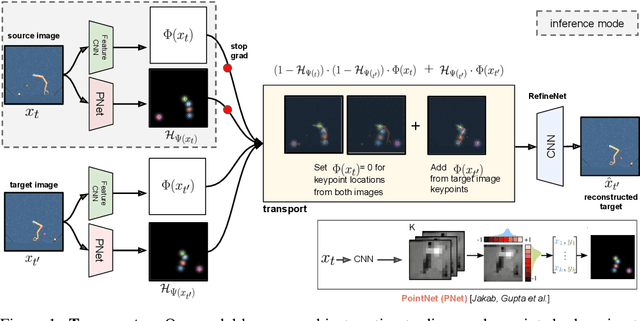

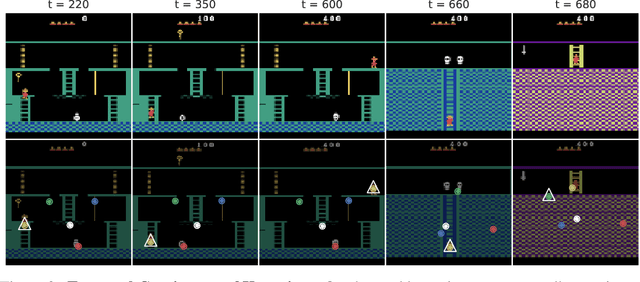
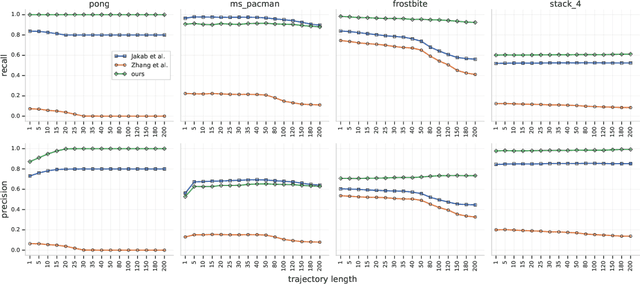
The study of object representations in computer vision has primarily focused on developing representations that are useful for image classification, object detection, or semantic segmentation as downstream tasks. In this work we aim to learn object representations that are useful for control and reinforcement learning (RL). To this end, we introduce Transporter, a neural network architecture for discovering concise geometric object representations in terms of keypoints or image-space coordinates. Our method learns from raw video frames in a fully unsupervised manner, by transporting learnt image features between video frames using a keypoint bottleneck. The discovered keypoints track objects and object parts across long time-horizons more accurately than recent similar methods. Furthermore, consistent long-term tracking enables two notable results in control domains -- (1) using the keypoint co-ordinates and corresponding image features as inputs enables highly sample-efficient reinforcement learning; (2) learning to explore by controlling keypoint locations drastically reduces the search space, enabling deep exploration (leading to states unreachable through random action exploration) without any extrinsic rewards.
Generating Diverse Programs with Instruction Conditioned Reinforced Adversarial Learning
Dec 03, 2018

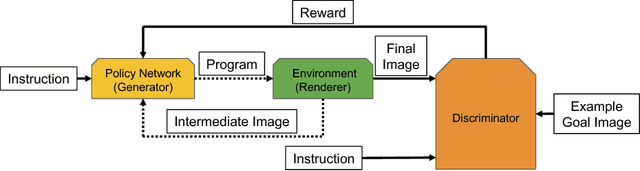
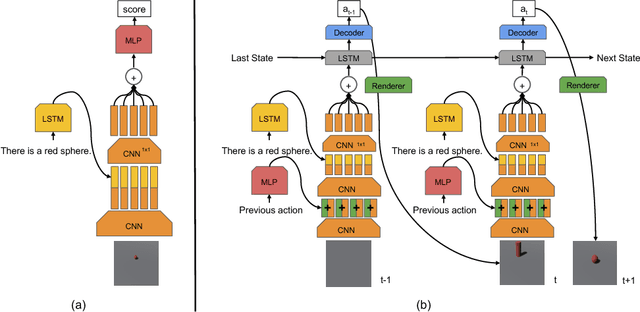
Advances in Deep Reinforcement Learning have led to agents that perform well across a variety of sensory-motor domains. In this work, we study the setting in which an agent must learn to generate programs for diverse scenes conditioned on a given symbolic instruction. Final goals are specified to our agent via images of the scenes. A symbolic instruction consistent with the goal images is used as the conditioning input for our policies. Since a single instruction corresponds to a diverse set of different but still consistent end-goal images, the agent needs to learn to generate a distribution over programs given an instruction. We demonstrate that with simple changes to the reinforced adversarial learning objective, we can learn instruction conditioned policies to achieve the corresponding diverse set of goals. Most importantly, our agent's stochastic policy is shown to more accurately capture the diversity in the goal distribution than a fixed pixel-based reward function baseline. We demonstrate the efficacy of our approach on two domains: (1) drawing MNIST digits with a paint software conditioned on instructions and (2) constructing scenes in a 3D editor that satisfies a certain instruction.
Unsupervised Control Through Non-Parametric Discriminative Rewards
Nov 28, 2018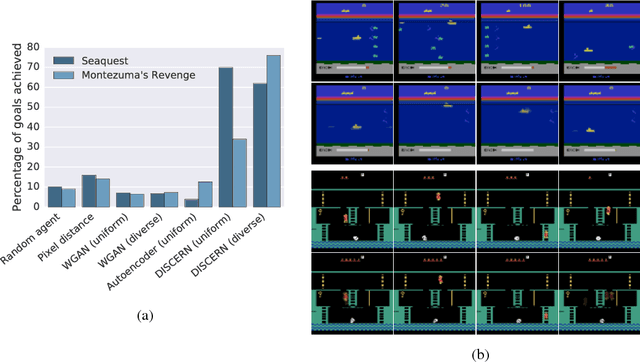
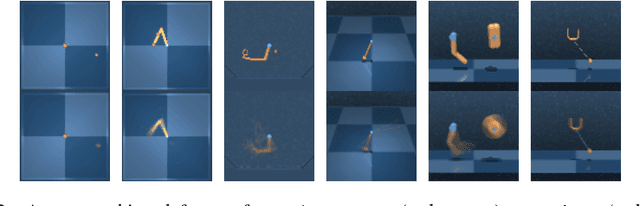
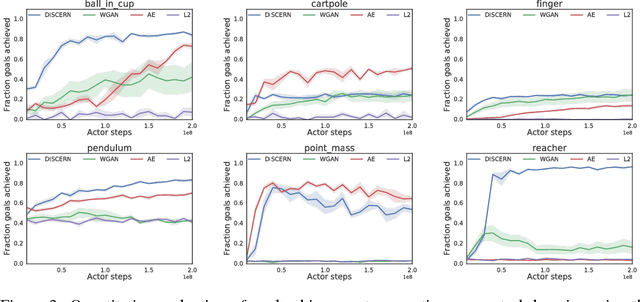
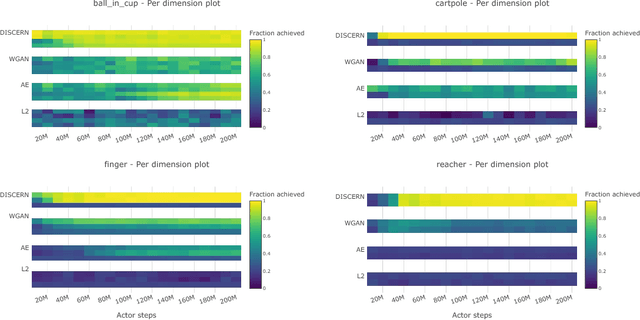
Learning to control an environment without hand-crafted rewards or expert data remains challenging and is at the frontier of reinforcement learning research. We present an unsupervised learning algorithm to train agents to achieve perceptually-specified goals using only a stream of observations and actions. Our agent simultaneously learns a goal-conditioned policy and a goal achievement reward function that measures how similar a state is to the goal state. This dual optimization leads to a co-operative game, giving rise to a learned reward function that reflects similarity in controllable aspects of the environment instead of distance in the space of observations. We demonstrate the efficacy of our agent to learn, in an unsupervised manner, to reach a diverse set of goals on three domains -- Atari, the DeepMind Control Suite and DeepMind Lab.