 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Learning in enormous action spaces via amortized approximate maximization
Jan 22, 2020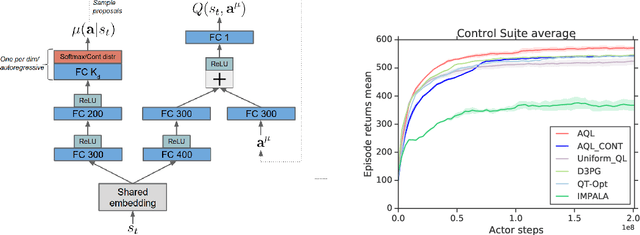

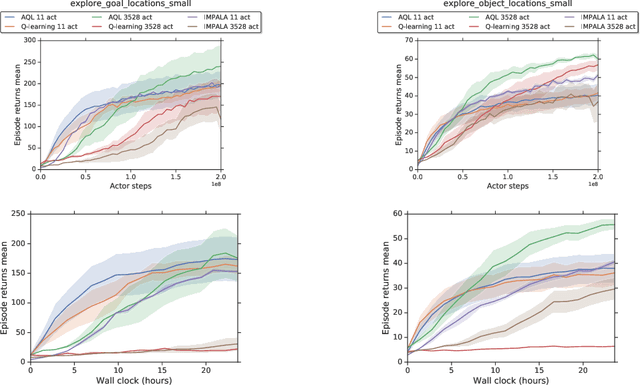

Applying Q-learning to high-dimensional or continuous action spaces can be difficult due to the required maximization over the set of possible actions. Motivated by techniques from amortized inference, we replace the expensive maximization over all actions with a maximization over a small subset of possible actions sampled from a learned proposal distribution. The resulting approach, which we dub Amortized Q-learning (AQL), is able to handle discrete, continuous, or hybrid action spaces while maintaining the benefits of Q-learning. Our experiments on continuous control tasks with up to 21 dimensional actions show that AQL outperforms D3PG (Barth-Maron et al, 2018) and QT-Opt (Kalashnikov et al, 2018). Experiments on structured discrete action spaces demonstrate that AQL can efficiently learn good policies in spaces with thousands of discrete actions.
Fast Task Inference with Variational Intrinsic Successor Features
Jun 12, 2019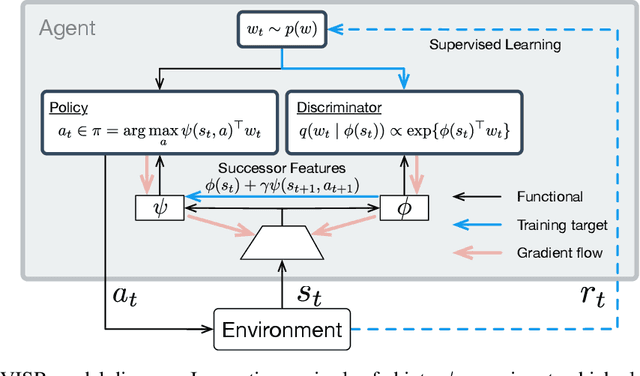
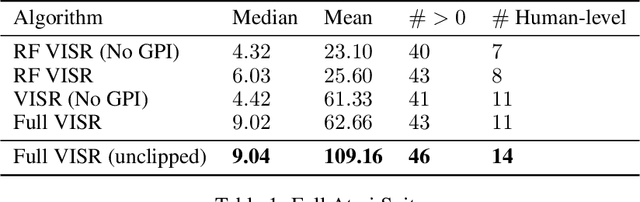
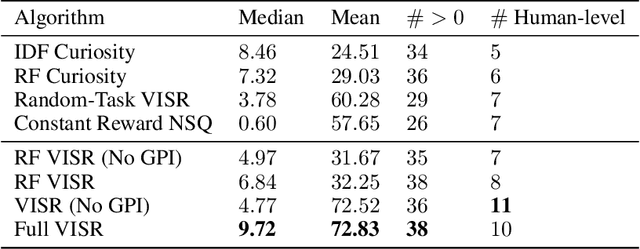
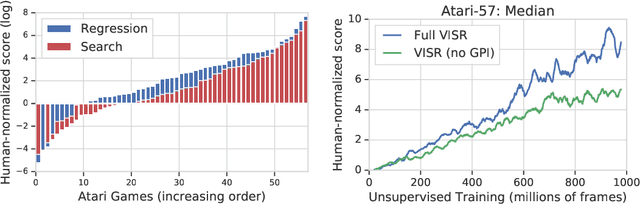
It has been established that diverse behaviors spanning the controllable subspace of an Markov decision process can be trained by rewarding a policy for being distinguishable from other policies \citep{gregor2016variational, eysenbach2018diversity, warde2018unsupervised}. However, one limitation of this formulation is generalizing behaviors beyond the finite set being explicitly learned, as is needed for use on subsequent tasks. Successor features \citep{dayan93improving, barreto2017successor} provide an appealing solution to this generalization problem, but require defining the reward function as linear in some grounded feature space. In this paper, we show that these two techniques can be combined, and that each method solves the other's primary limitation. To do so we introduce Variational Intrinsic Successor FeatuRes (VISR), a novel algorithm which learns controllable features that can be leveraged to provide enhanced generalization and fast task inference through the successor feature framework. We empirically validate VISR on the full Atari suite, in a novel setup wherein the rewards are only exposed briefly after a long unsupervised phase. Achieving human-level performance on 14 games and beating all baselines, we believe VISR represents a step towards agents that rapidly learn from limited feedback.
Unsupervised Control Through Non-Parametric Discriminative Rewards
Nov 28, 2018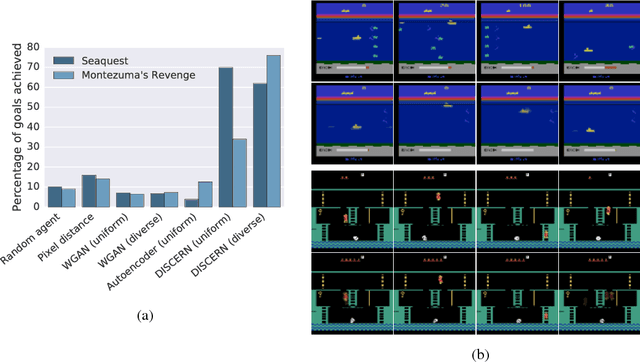
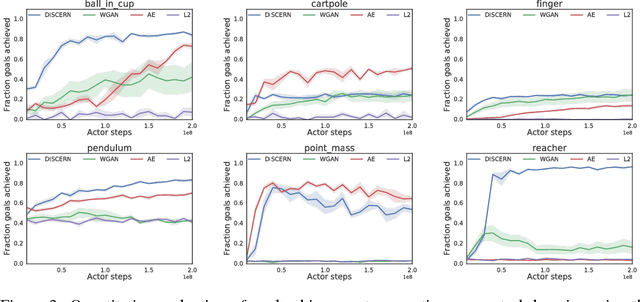
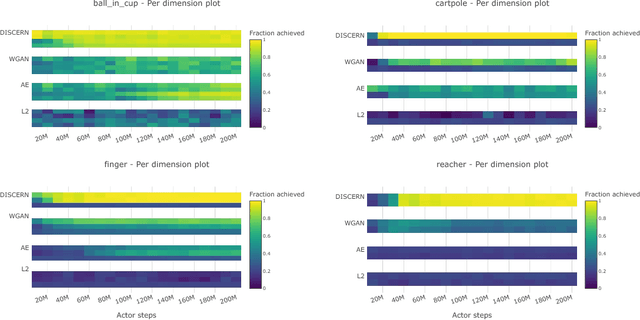
Learning to control an environment without hand-crafted rewards or expert data remains challenging and is at the frontier of reinforcement learning research. We present an unsupervised learning algorithm to train agents to achieve perceptually-specified goals using only a stream of observations and actions. Our agent simultaneously learns a goal-conditioned policy and a goal achievement reward function that measures how similar a state is to the goal state. This dual optimization leads to a co-operative game, giving rise to a learned reward function that reflects similarity in controllable aspects of the environment instead of distance in the space of observations. We demonstrate the efficacy of our agent to learn, in an unsupervised manner, to reach a diverse set of goals on three domains -- Atari, the DeepMind Control Suite and DeepMind Lab.
Learning by Playing - Solving Sparse Reward Tasks from Scratch
Feb 28, 2018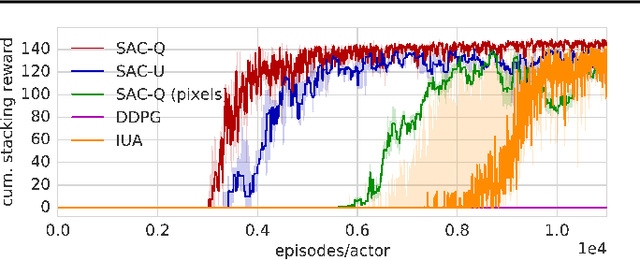
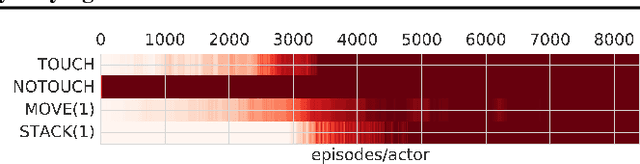
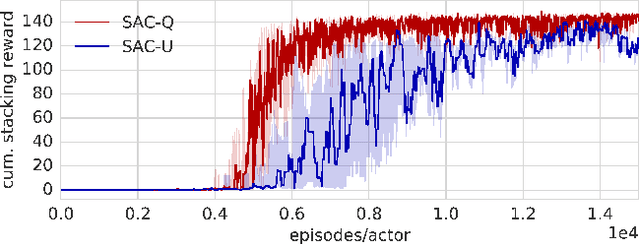
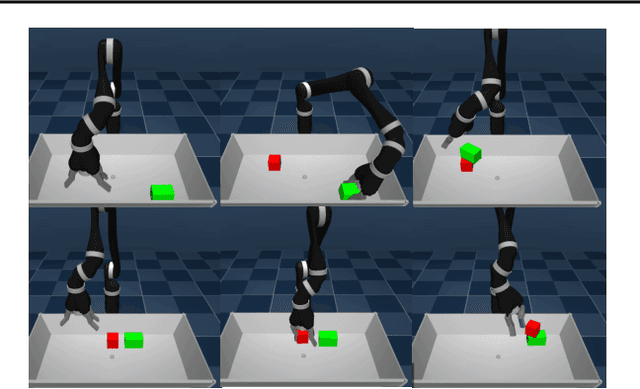
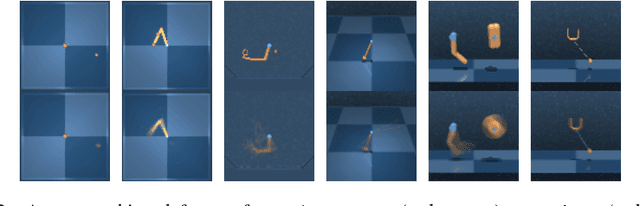
We propose Scheduled Auxiliary Control (SAC-X), a new learning paradigm in the context of Reinforcement Learning (RL). SAC-X enables learning of complex behaviors - from scratch - in the presence of multiple sparse reward signals. To this end, the agent is equipped with a set of general auxiliary tasks, that it attempts to learn simultaneously via off-policy RL. The key idea behind our method is that active (learned) scheduling and execution of auxiliary policies allows the agent to efficiently explore its environment - enabling it to excel at sparse reward RL. Our experiments in several challenging robotic manipulation settings demonstrate the power of our approach.