 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrödinger Bridge Flow for Unpaired Data Translation
Sep 14, 2024Mass transport problems arise in many areas of machine learning whereby one wants to compute a map transporting one distribution to another. Generative modeling techniques like Generative Adversarial Networks (GANs) and Denoising Diffusion Models (DDMs) have been successfully adapted to solve such transport problems, resulting in CycleGAN and Bridge Matching respectively. However, these methods do not approximate Optimal Transport (OT) maps, which are known to have desirable properties. Existing techniques approximating OT maps for high-dimensional data-rich problems, such as DDM-based Rectified Flow and Schr\"odinger Bridge procedures, require fully training a DDM-type model at each iteration, or use mini-batch techniques which can introduce significant errors. We propose a novel algorithm to compute the Schr\"odinger Bridge, a dynamic entropy-regularised version of OT, that eliminates the need to train multiple DDM-like models. This algorithm corresponds to a discretisation of a flow of path measures, which we call the Schr\"odinger Bridge Flow, whose only stationary point is the Schr\"odinger Bridge. We demonstrate the performance of our algorithm on a variety of unpaired data translation tasks.
Score Modeling for Simulation-based Inference
Sep 28, 2022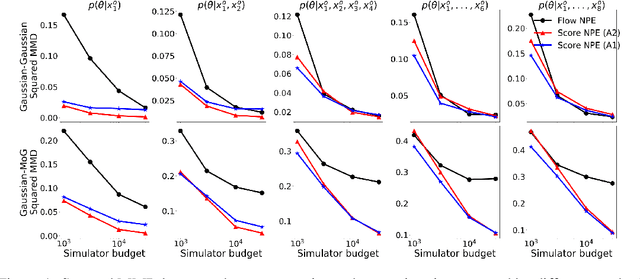
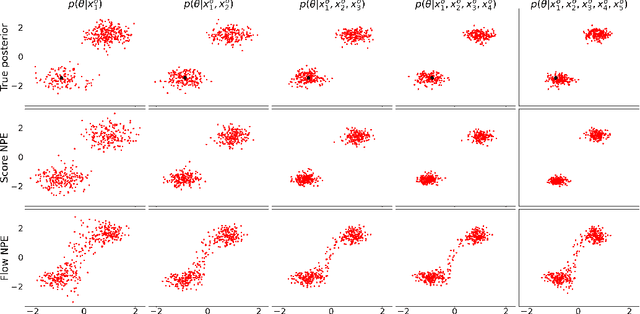
Neural Posterior Estimation methods for simulation-based inference can be ill-suited for dealing with posterior distributions obtained by conditioning on multiple observations, as they may require a large number of simulator calls to yield accurate approximations. Neural Likelihood Estimation methods can naturally handle multiple observations, but require a separate inference step, which may affect their efficiency and performance. We introduce a new method for simulation-based inference that enjoys the benefits of both approaches. We propose to model the scores for the posterior distributions induced by individual observations, and introduce a sampling algorithm that combines the learned scores to approximately sample from the target efficiently.
Unbiased Gradient Estimation with Balanced Assignments for Mixtures of Experts
Sep 24, 2021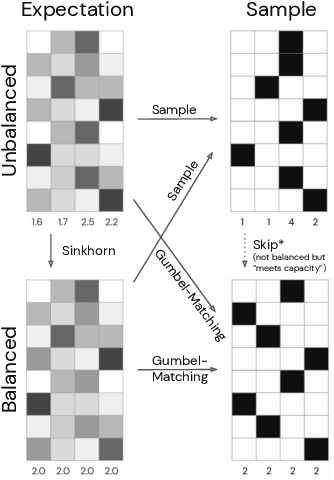
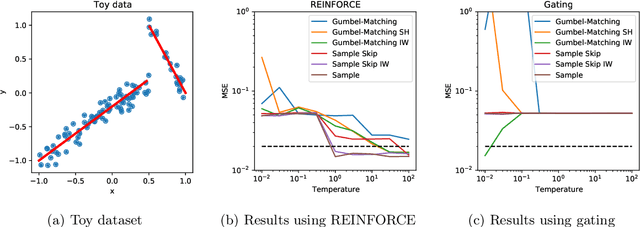
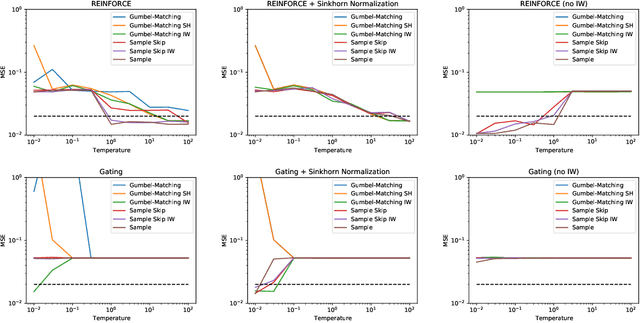
Training large-scale mixture of experts models efficiently on modern hardware requires assigning datapoints in a batch to different experts, each with a limited capacity. Recently proposed assignment procedures lack a probabilistic interpretation and use biased estimators for training. As an alternative, we propose two unbiased estimators based on principled stochastic assignment procedures: one that skips datapoints which exceed expert capacity, and one that samples perfectly balanced assignments using an extension of the Gumbel-Matching distribution [29]. Both estimators are unbiased, as they correct for the used sampling procedure. On a toy experiment, we find the `skip'-estimator is more effective than the balanced sampling one, and both are more robust in solving the task than biased alternatives.
Coupled Gradient Estimators for Discrete Latent Variables
Jun 15, 2021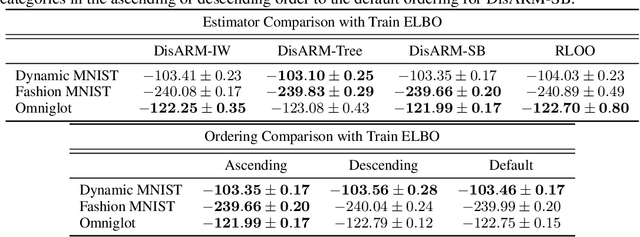
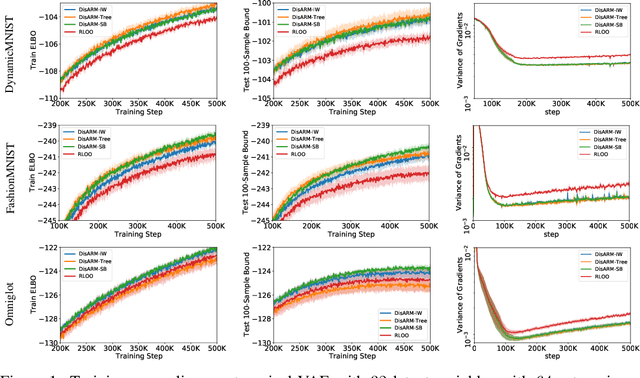
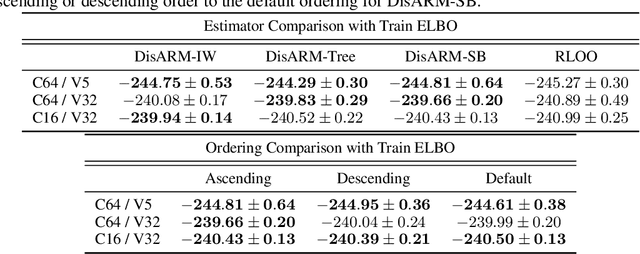
Training models with discrete latent variables is challenging due to the high variance of unbiased gradient estimators. While low-variance reparameterization gradients of a continuous relaxation can provide an effective solution, a continuous relaxation is not always available or tractable. Dong et al. (2020) and Yin et al. (2020) introduced a performant estimator that does not rely on continuous relaxations; however, it is limited to binary random variables. We introduce a novel derivation of their estimator based on importance sampling and statistical couplings, which we extend to the categorical setting. Motivated by the construction of a stick-breaking coupling, we introduce gradient estimators based on reparameterizing categorical variables as sequences of binary variables and Rao-Blackwellization. In systematic experiments, we show that our proposed categorical gradient estimators provide state-of-the-art performance, whereas even with additional Rao-Blackwellization, previous estimators (Yin et al., 2019) underperform a simpler REINFORCE with a leave-one-out-baseline estimator (Kool et al., 2019).
Generalized Doubly Reparameterized Gradient Estimators
Jan 26, 2021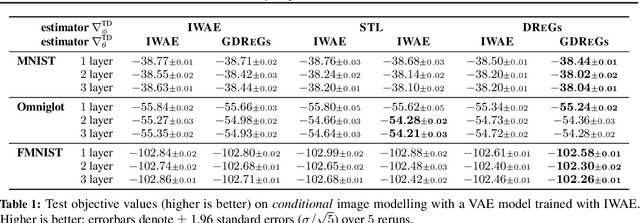



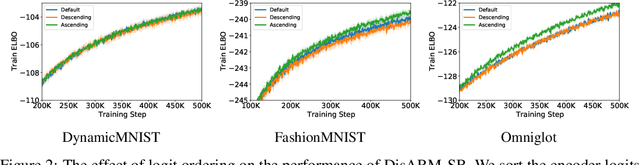
Efficient low-variance gradient estimation enabled by the reparameterization trick (RT) has been essential to the success of variational autoencoders. Doubly-reparameterized gradients (DReGs) improve on the RT for multi-sample variational bounds by applying reparameterization a second time for an additional reduction in variance. Here, we develop two generalizations of the DReGs estimator and show that they can be used to train conditional and hierarchical VAEs on image modelling tasks more effectively. We first extend the estimator to hierarchical models with several stochastic layers by showing how to treat additional score function terms due to the hierarchical variational posterior. We then generalize DReGs to score functions of arbitrary distributions instead of just those of the sampling distribution, which makes the estimator applicable to the parameters of the prior in addition to those of the posterior.
DisARM: An Antithetic Gradient Estimator for Binary Latent Variables
Jun 18, 2020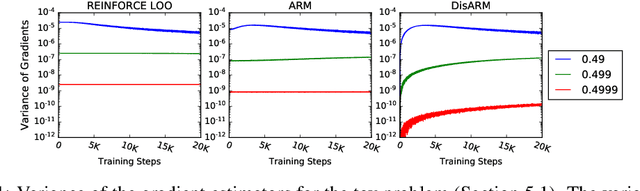
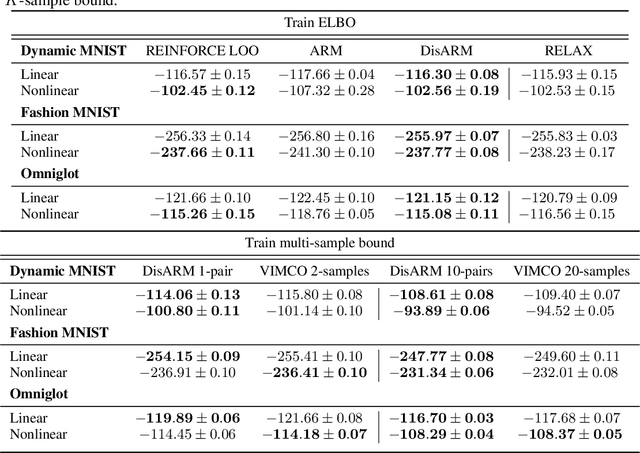
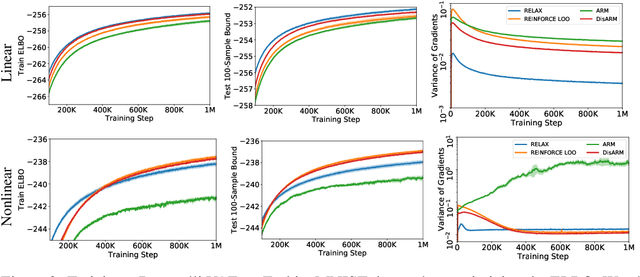
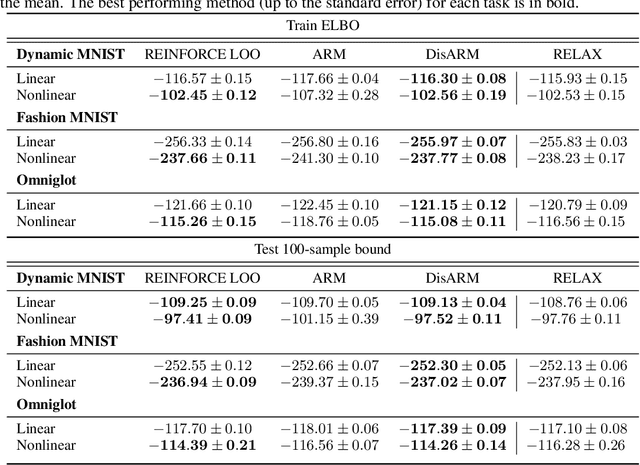
Training models with discrete latent variables is challenging due to the difficulty of estimating the gradients accurately. Much of the recent progress has been achieved by taking advantage of continuous relaxations of the system, which are not always available or even possible. The Augment-REINFORCE-Merge (ARM) estimator provides an alternative that, instead of relaxation, uses continuous augmentation. Applying antithetic sampling over the augmenting variables yields a relatively low-variance and unbiased estimator applicable to any model with binary latent variables. However, while antithetic sampling reduces variance, the augmentation process increases variance. We show that ARM can be improved by analytically integrating out the randomness introduced by the augmentation process, guaranteeing substantial variance reduction. Our estimator, \emph{DisARM}, is simple to implement and has the same computational cost as ARM. We evaluate DisARM on several generative modeling benchmarks and show that it consistently outperforms ARM and a strong independent sample baseline in terms of both variance and log-likelihood. Furthermore, we propose a local version of DisARM designed for optimizing the multi-sample variational bound, and show that it outperforms VIMCO, the current state-of-the-art method.
The Lipschitz Constant of Self-Attention
Jun 08, 2020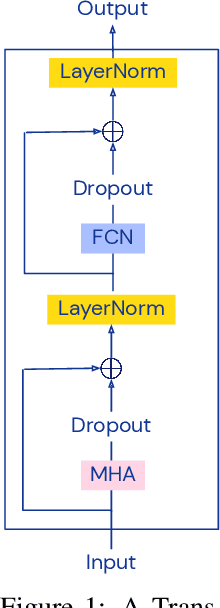
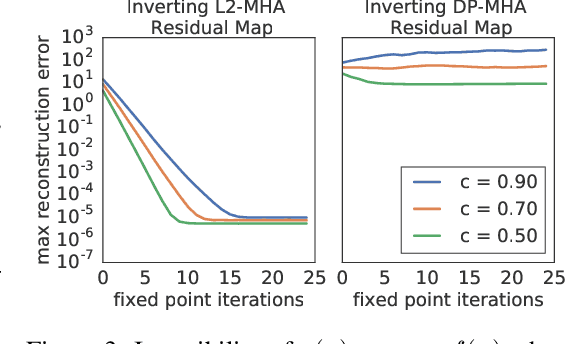
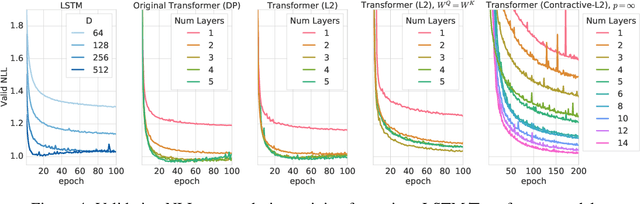
Lipschitz constants of neural networks have been explored in various contexts in deep learning, such as provable adversarial robustness, estimating Wasserstein distance, stabilising training of GANs, and formulating invertible neural networks. Such works have focused on bounding the Lipschitz constant of fully connected or convolutional networks, composed of linear maps and pointwise non-linearities. In this paper, we investigate the Lipschitz constant of self-attention, a non-linear neural network module widely used in sequence modelling. We prove that the standard dot-product self-attention is not Lipschitz, and propose an alternative L2 self-attention that is Lipschitz. We derive an upper bound on the Lipschitz constant of L2 self-attention and provide empirical evidence for its asymptotic tightness. To demonstrate the practical relevance of the theory, we formulate invertible self-attention and use it in a Transformer-based architecture for a character-level language modelling task.
Q-Learning in enormous action spaces via amortized approximate maximization
Jan 22, 2020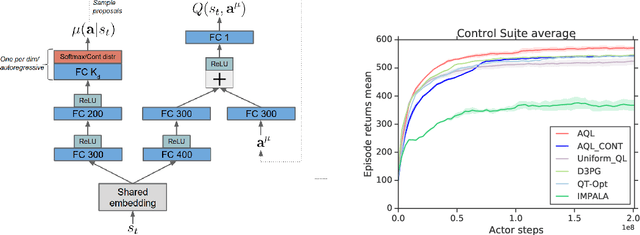

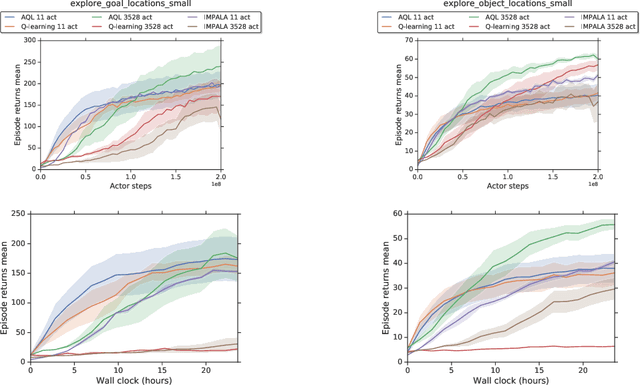

Applying Q-learning to high-dimensional or continuous action spaces can be difficult due to the required maximization over the set of possible actions. Motivated by techniques from amortized inference, we replace the expensive maximization over all actions with a maximization over a small subset of possible actions sampled from a learned proposal distribution. The resulting approach, which we dub Amortized Q-learning (AQL), is able to handle discrete, continuous, or hybrid action spaces while maintaining the benefits of Q-learning. Our experiments on continuous control tasks with up to 21 dimensional actions show that AQL outperforms D3PG (Barth-Maron et al, 2018) and QT-Opt (Kalashnikov et al, 2018). Experiments on structured discrete action spaces demonstrate that AQL can efficiently learn good policies in spaces with thousands of discrete actions.
Sparse Orthogonal Variational Inference for Gaussian Processes
Oct 24, 2019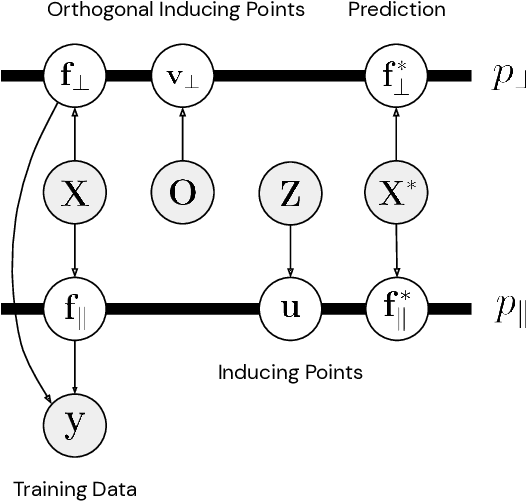


We introduce a new interpretation of sparse variational approximations for Gaussian processes using inducing points which can lead to more scalable algorithms than previous methods. It is based on decomposing a Gaussian process as a sum of two independent processes: one in the subspace spanned by the inducing basis and the other in the orthogonal complement to this subspace. We show that this formulation recovers existing approximations and at the same time allows to obtain tighter lower bounds on the marginal likelihood and new stochastic variational inference algorithms. We demonstrate the efficiency of these algorithms in several Gaussian process models ranging from standard regression to multi-class classification using (deep) convolutional Gaussian processes and report state-of-the-art results on CIFAR-10 with purely GP-based models.
Monte Carlo Gradient Estimation in Machine Learning
Jun 25, 2019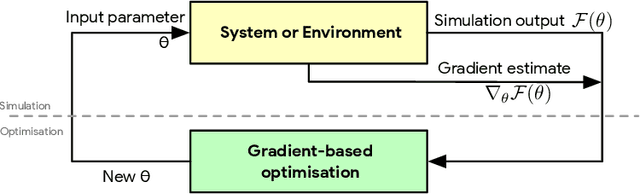

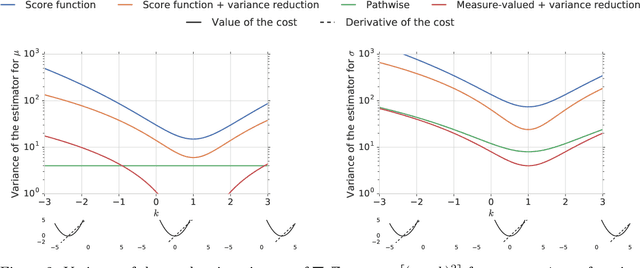
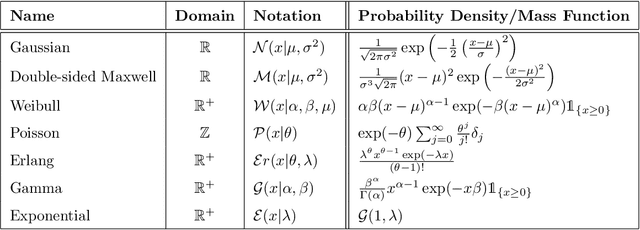
This paper is a broad and accessible survey of the methods we have at our disposal for Monte Carlo gradient estimation in machine learning and across the statistical sciences: the problem of computing the gradient of an expectation of a function with respect to parameters defining the distribution that is integrated; the problem of sensitivity analysis. In machine learning research, this gradient problem lies at the core of many learning problems, in supervised, unsupervised and reinforcement learning. We will generally seek to rewrite such gradients in a form that allows for Monte Carlo estimation, allowing them to be easily and efficiently used and analysed. We explore three strategies--the pathwise, score function, and measure-valued gradient estimators--exploring their historical developments, derivation, and underlying assumptions. We describe their use in other fields, show how they are related and can be combined, and expand on their possible generalisations. Wherever Monte Carlo gradient estimators have been derived and deployed in the past, important advances have followed. A deeper and more widely-held understanding of this problem will lead to further advances, and it is these advances that we wish to support.