 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of the Gumbel-max Trick and its Extensions for Discrete Stochasticity in Machine Learning
Oct 04, 2021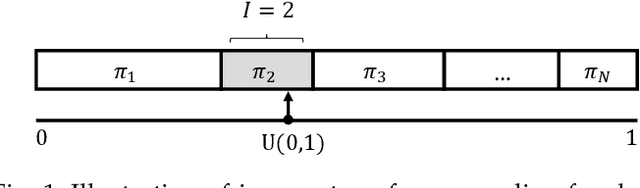
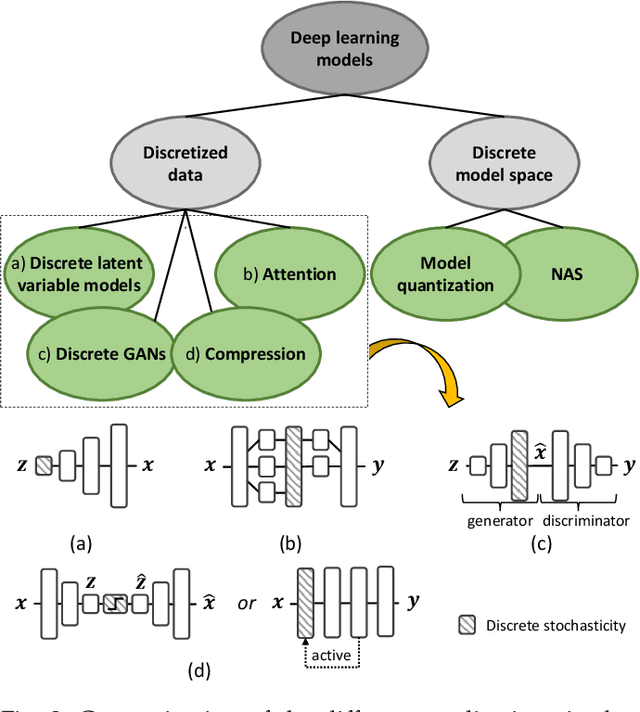
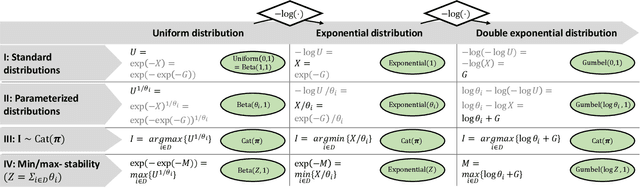
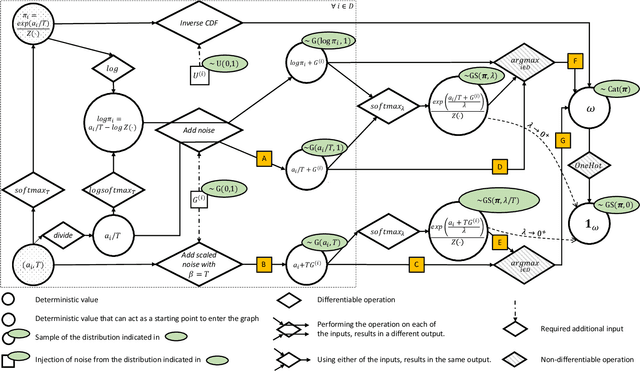
The Gumbel-max trick is a method to draw a sample from a categorical distribution, given by its unnormalized (log-)probabilities. Over the past years, the machine learning community has proposed several extensions of this trick to facilitate, e.g., drawing multiple samples, sampling from structured domains, or gradient estimation for error backpropagation in neural network optimization. The goal of this survey article is to present background about the Gumbel-max trick, and to provide a structured overview of its extensions to ease algorithm selection. Moreover, it presents a comprehensive outline of (machine learning) literature in which Gumbel-based algorithms have been leveraged, reviews commonly-made design choices, and sketches a future perspective.
Unbiased Gradient Estimation with Balanced Assignments for Mixtures of Experts
Sep 24, 2021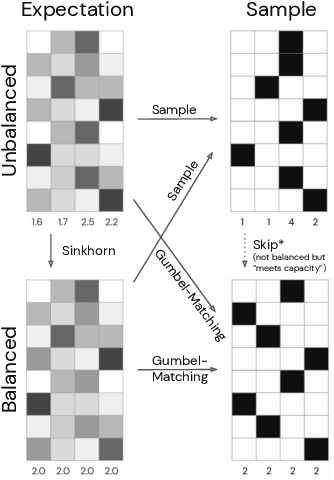
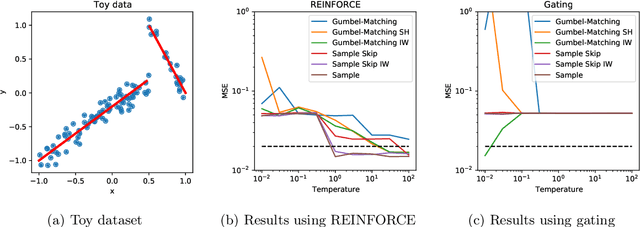
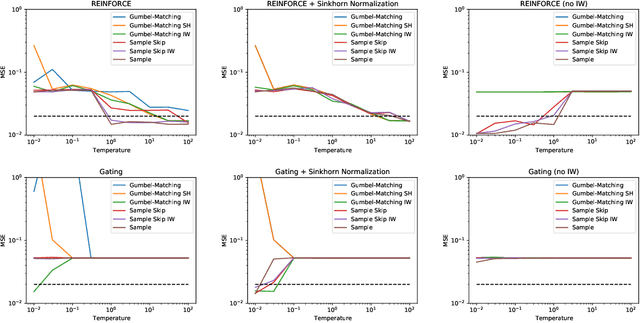
Training large-scale mixture of experts models efficiently on modern hardware requires assigning datapoints in a batch to different experts, each with a limited capacity. Recently proposed assignment procedures lack a probabilistic interpretation and use biased estimators for training. As an alternative, we propose two unbiased estimators based on principled stochastic assignment procedures: one that skips datapoints which exceed expert capacity, and one that samples perfectly balanced assignments using an extension of the Gumbel-Matching distribution [29]. Both estimators are unbiased, as they correct for the used sampling procedure. On a toy experiment, we find the `skip'-estimator is more effective than the balanced sampling one, and both are more robust in solving the task than biased alternatives.
Deep Policy Dynamic Programming for Vehicle Routing Problems
Feb 23, 2021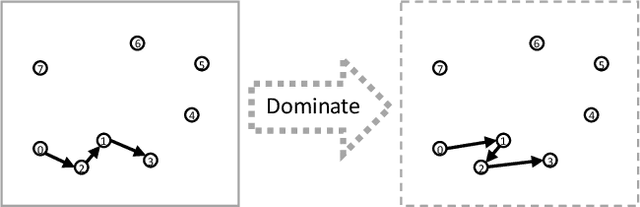
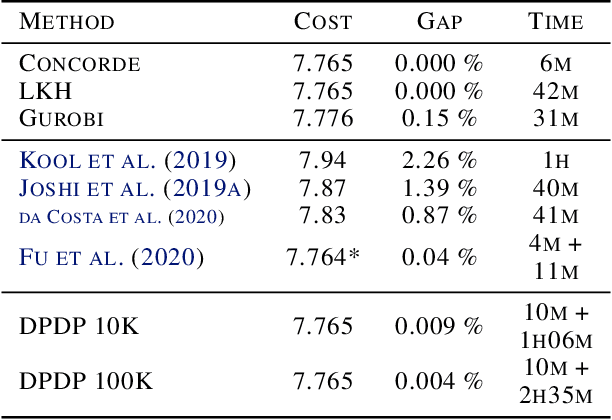
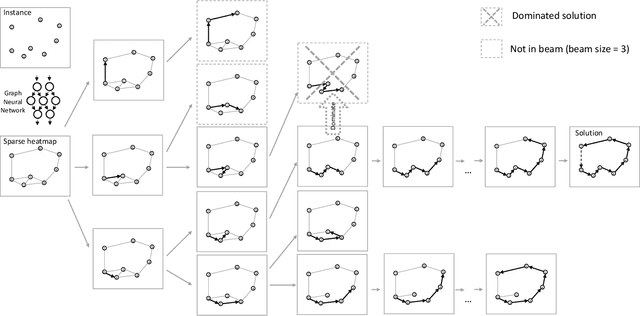
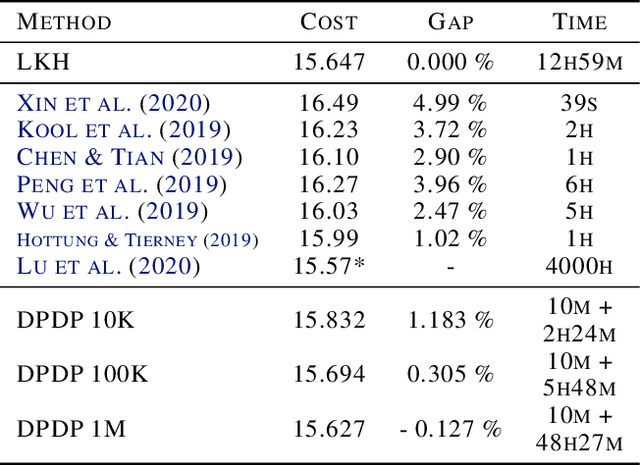
Routing problems are a class of combinatorial problems with many practical applications. Recently, end-to-end deep learning methods have been proposed to learn approximate solution heuristics for such problems. In contrast, classical dynamic programming (DP) algorithms can find optimal solutions, but scale badly with the problem size. We propose Deep Policy Dynamic Programming (DPDP), which aims to combine the strengths of learned neural heuristics with those of DP algorithms. DPDP prioritizes and restricts the DP state space using a policy derived from a deep neural network, which is trained to predict edges from example solutions. We evaluate our framework on the travelling salesman problem (TSP) and the vehicle routing problem (VRP) and show that the neural policy improves the performance of (restricted) DP algorithms, making them competitive to strong alternatives such as LKH, while also outperforming other `neural approaches' for solving TSPs and VRPs with 100 nodes.
Estimating Gradients for Discrete Random Variables by Sampling without Replacement
Feb 14, 2020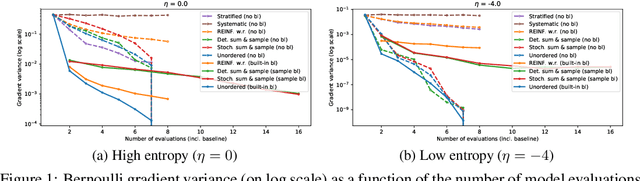
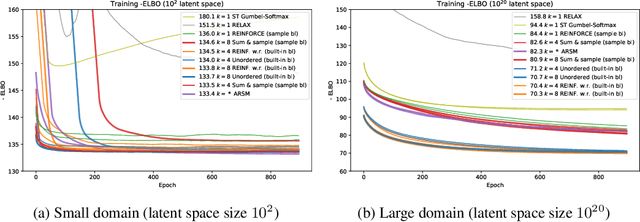
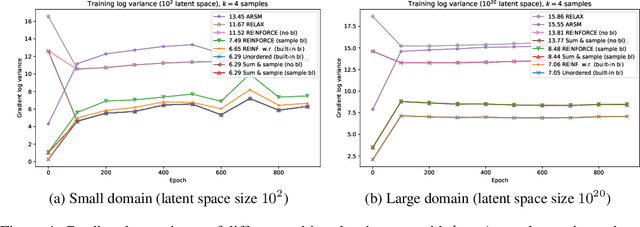
We derive an unbiased estimator for expectations over discrete random variables based on sampling without replacement, which reduces variance as it avoids duplicate samples. We show that our estimator can be derived as the Rao-Blackwellization of three different estimators. Combining our estimator with REINFORCE, we obtain a policy gradient estimator and we reduce its variance using a built-in control variate which is obtained without additional model evaluations. The resulting estimator is closely related to other gradient estimators. Experiments with a toy problem, a categorical Variational Auto-Encoder and a structured prediction problem show that our estimator is the only estimator that is consistently among the best estimators in both high and low entropy settings.
Stochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement
Mar 14, 2019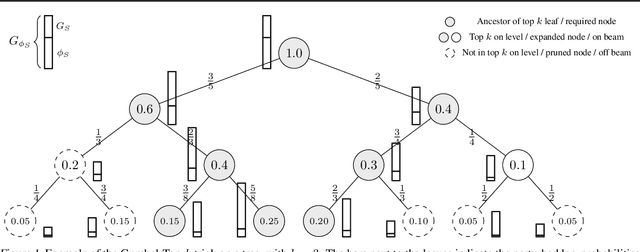
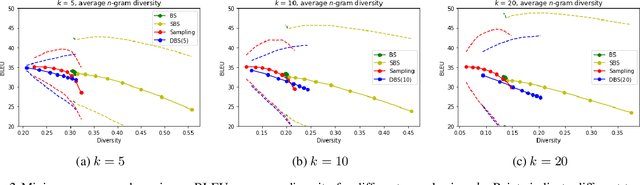
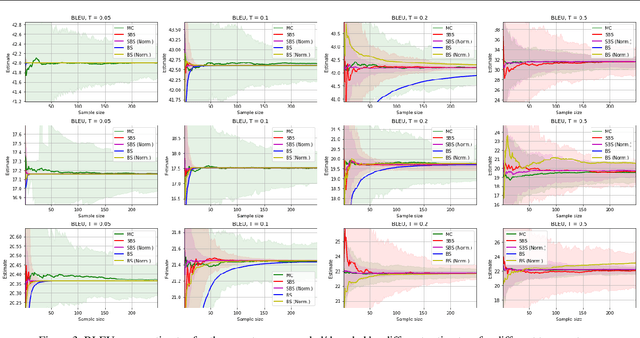
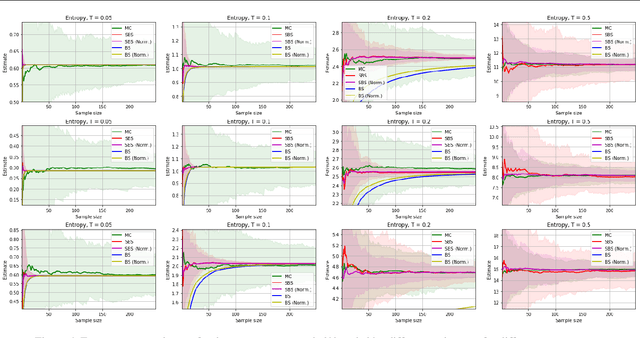
The well-known Gumbel-Max trick for sampling from a categorical distribution can be extended to sample $k$ elements without replacement. We show how to implicitly apply this 'Gumbel-Top-$k$' trick on a factorized distribution over sequences, allowing to draw exact samples without replacement using a Stochastic Beam Search. Even for exponentially large domains, the number of model evaluations grows only linear in $k$ and the maximum sampled sequence length. The algorithm creates a theoretical connection between sampling and (deterministic) beam search and can be used as a principled intermediate alternative. In a translation task, the proposed method compares favourably against alternatives to obtain diverse yet good quality translations. We show that sequences sampled without replacement can be used to construct low-variance estimators for expected sentence-level BLEU score and model entropy.
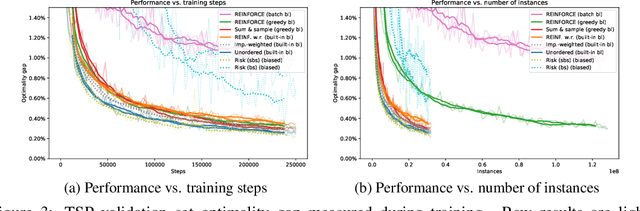
Attention Solves Your TSP, Approximately
Jun 22, 2018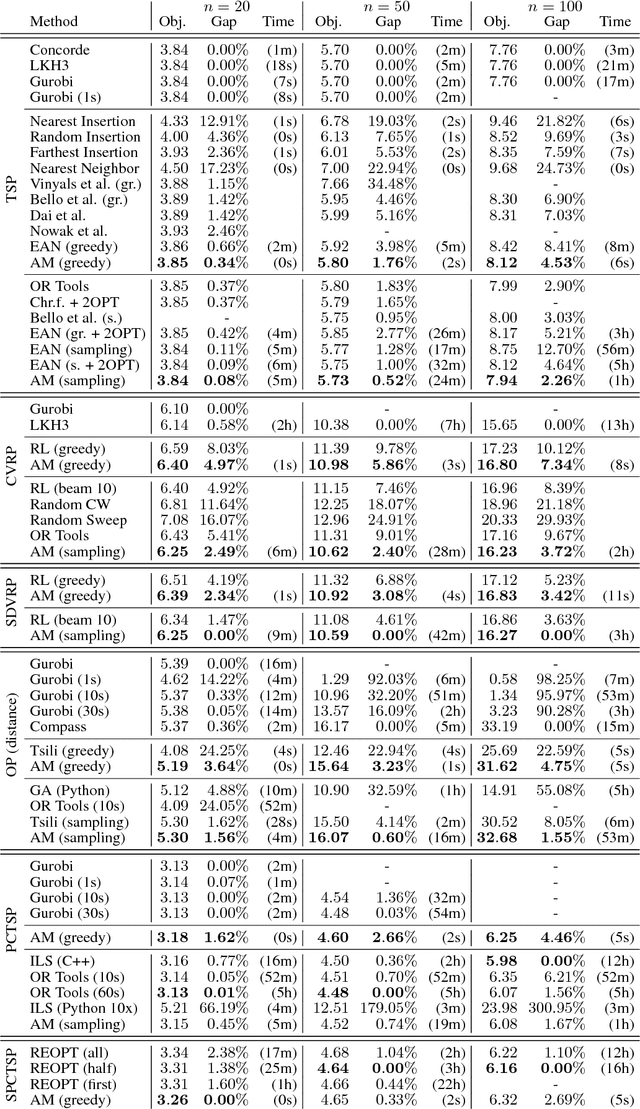
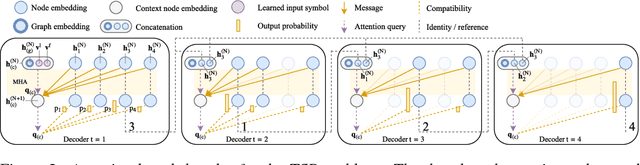
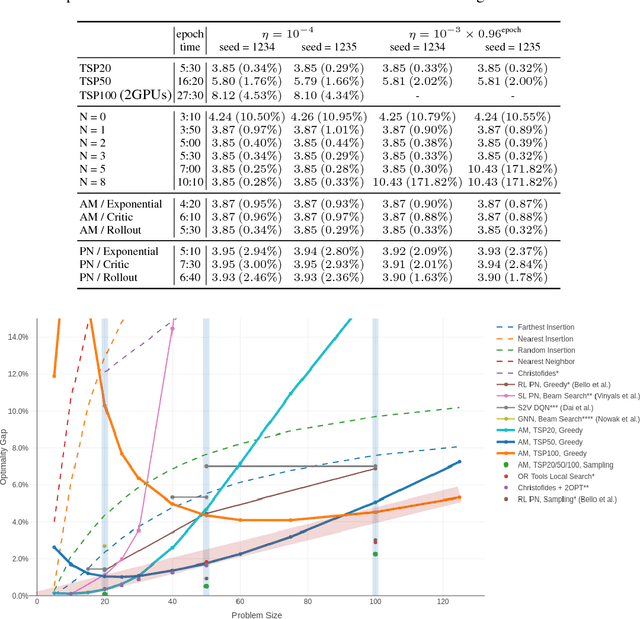
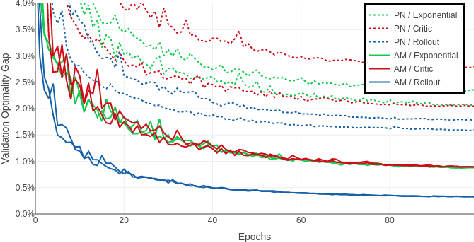
The development of efficient (heuristic) algorithms for practical combinatorial optimization problems is costly, so we want to automatically learn them instead. We show the feasibility of this approach on the important Travelling Salesman Problem (TSP). We learn a heuristic algorithm that uses a Neural Network policy to construct a tour. As an alternative to the Pointer Network, our model is based entirely on (graph) attention layers and is invariant to the input order of the nodes. We train the model efficiently using REINFORCE with a simple and robust baseline based on a deterministic (greedy) rollout of the best policy so far. We significantly improve over results from previous works that consider learned heuristics for the TSP, reducing the optimality gap for a single tour construction from 1.51% to 0.32% for instances with 20 nodes, from 4.59% to 1.71% for 50 nodes and from 6.89% to 4.43% for 100 nodes. Additionally, we improve over a recent Reinforcement Learning framework for two variants of the Vehicle Routing Problem (VRP).