 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Solves Your TSP, Approximately
Paper and Code
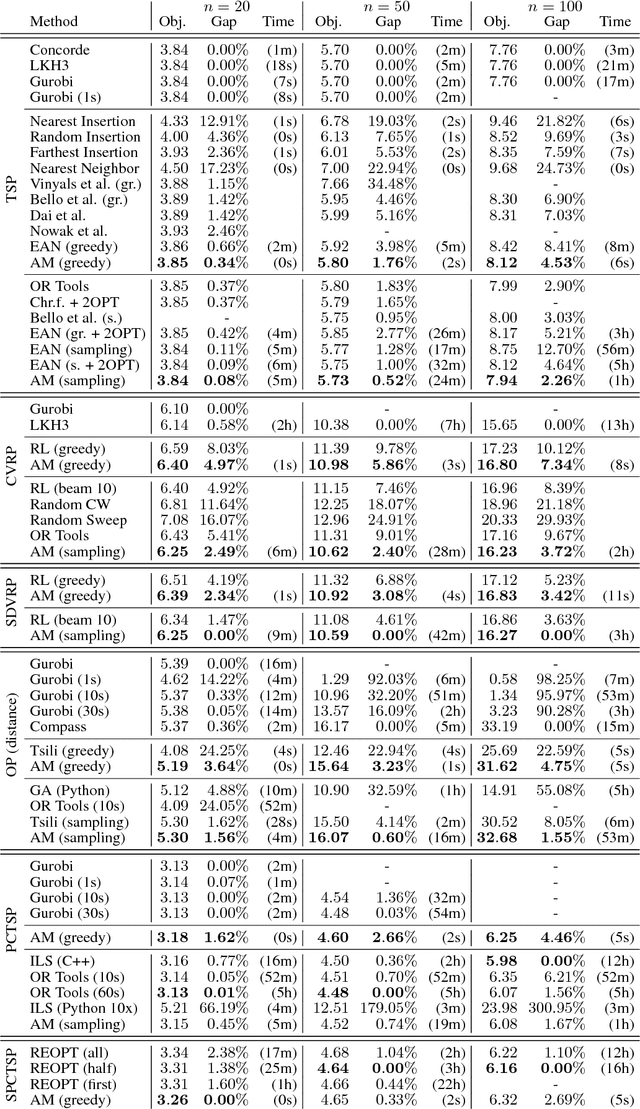
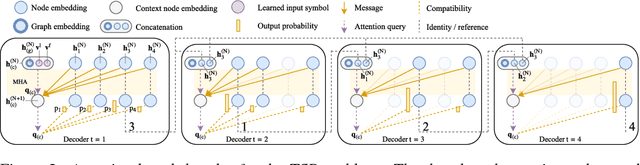
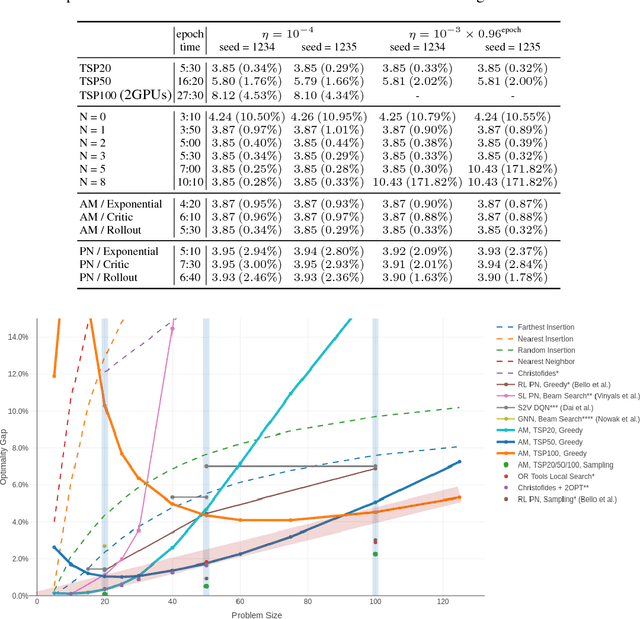
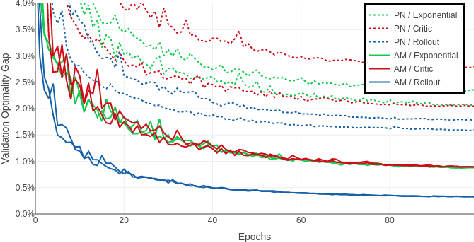
The development of efficient (heuristic) algorithms for practical combinatorial optimization problems is costly, so we want to automatically learn them instead. We show the feasibility of this approach on the important Travelling Salesman Problem (TSP). We learn a heuristic algorithm that uses a Neural Network policy to construct a tour. As an alternative to the Pointer Network, our model is based entirely on (graph) attention layers and is invariant to the input order of the nodes. We train the model efficiently using REINFORCE with a simple and robust baseline based on a deterministic (greedy) rollout of the best policy so far. We significantly improve over results from previous works that consider learned heuristics for the TSP, reducing the optimality gap for a single tour construction from 1.51% to 0.32% for instances with 20 nodes, from 4.59% to 1.71% for 50 nodes and from 6.89% to 4.43% for 100 nodes. Additionally, we improve over a recent Reinforcement Learning framework for two variants of the Vehicle Routing Problem (VRP).