 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Gradient Estimation with Balanced Assignments for Mixtures of Experts
Paper and Code
Sep 24, 2021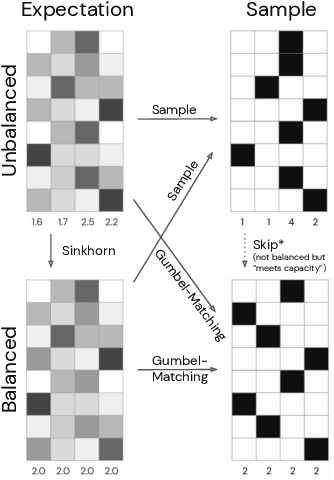
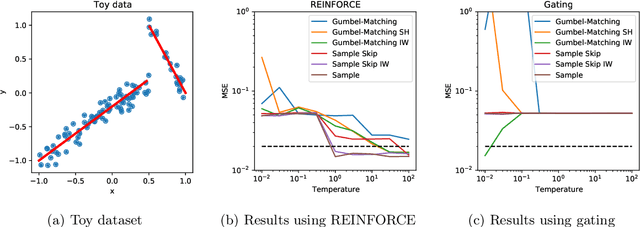
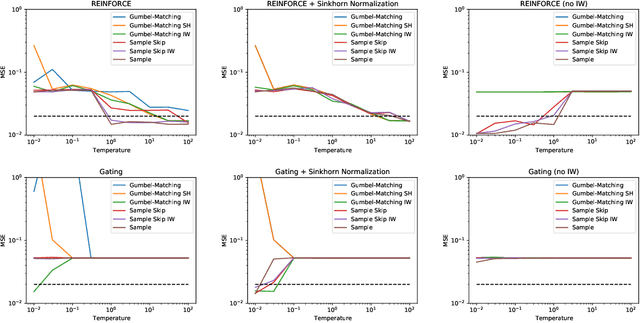
Training large-scale mixture of experts models efficiently on modern hardware requires assigning datapoints in a batch to different experts, each with a limited capacity. Recently proposed assignment procedures lack a probabilistic interpretation and use biased estimators for training. As an alternative, we propose two unbiased estimators based on principled stochastic assignment procedures: one that skips datapoints which exceed expert capacity, and one that samples perfectly balanced assignments using an extension of the Gumbel-Matching distribution [29]. Both estimators are unbiased, as they correct for the used sampling procedure. On a toy experiment, we find the `skip'-estimator is more effective than the balanced sampling one, and both are more robust in solving the task than biased alternatives.