 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Gibbs free energies via isobaric-isothermal flows
May 22, 2023We present a machine-learning model based on normalizing flows that is trained to sample from the isobaric-isothermal (NPT) ensemble. In our approach, we approximate the joint distribution of a fully-flexible triclinic simulation box and particle coordinates to achieve a desired internal pressure. We test our model on monatomic water in the cubic and hexagonal ice phases and find excellent agreement of Gibbs free energies and other observables compared with established baselines.
Equivariant MuZero
Feb 09, 2023


Deep reinforcement learning repeatedly succeeds in closed, well-defined domains such as games (Chess, Go, StarCraft). The next frontier is real-world scenarios, where setups are numerous and varied. For this, agents need to learn the underlying rules governing the environment, so as to robustly generalise to conditions that differ from those they were trained on. Model-based reinforcement learning algorithms, such as the highly successful MuZero, aim to accomplish this by learning a world model. However, leveraging a world model has not consistently shown greater generalisation capabilities compared to model-free alternatives. In this work, we propose improving the data efficiency and generalisation capabilities of MuZero by explicitly incorporating the symmetries of the environment in its world-model architecture. We prove that, so long as the neural networks used by MuZero are equivariant to a particular symmetry group acting on the environment, the entirety of MuZero's action-selection algorithm will also be equivariant to that group. We evaluate Equivariant MuZero on procedurally-generated MiniPacman and on Chaser from the ProcGen suite: training on a set of mazes, and then testing on unseen rotated versions, demonstrating the benefits of equivariance. Further, we verify that our performance improvements hold even when only some of the components of Equivariant MuZero obey strict equivariance, which highlights the robustness of our construction.
Score Modeling for Simulation-based Inference
Sep 28, 2022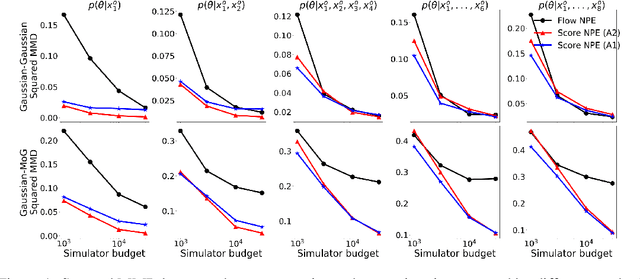
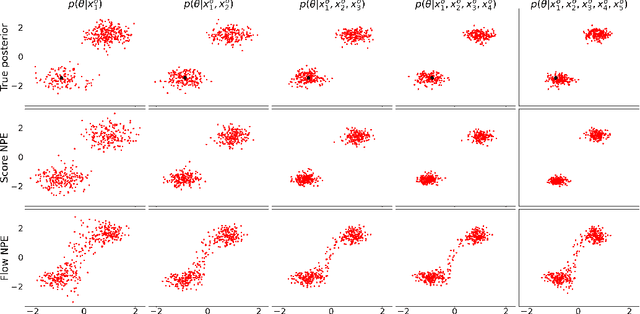
Neural Posterior Estimation methods for simulation-based inference can be ill-suited for dealing with posterior distributions obtained by conditioning on multiple observations, as they may require a large number of simulator calls to yield accurate approximations. Neural Likelihood Estimation methods can naturally handle multiple observations, but require a separate inference step, which may affect their efficiency and performance. We introduce a new method for simulation-based inference that enjoys the benefits of both approaches. We propose to model the scores for the posterior distributions induced by individual observations, and introduce a sampling algorithm that combines the learned scores to approximately sample from the target efficiently.
A Generalist Neural Algorithmic Learner
Sep 22, 2022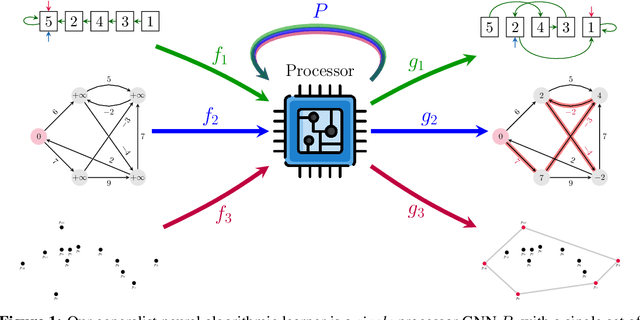
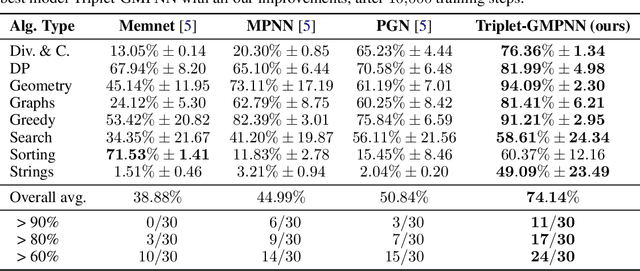
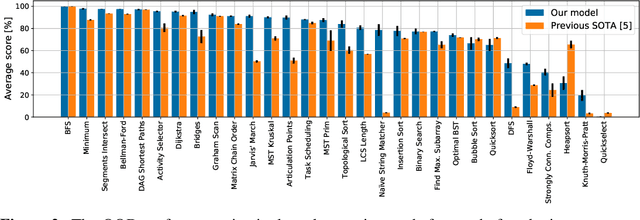
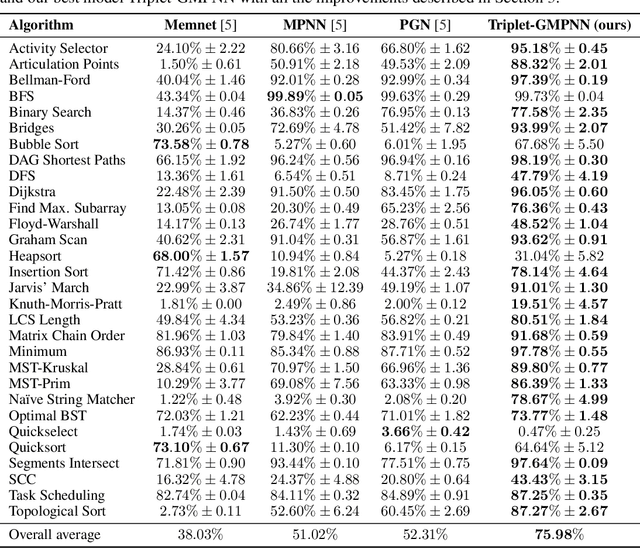
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner -- a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
Normalizing flows for atomic solids
Nov 16, 2021
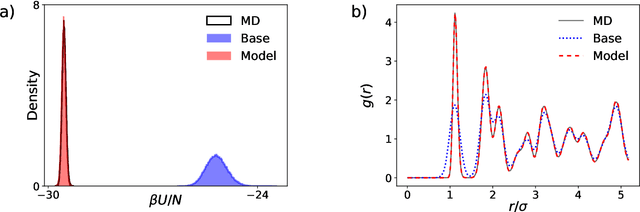
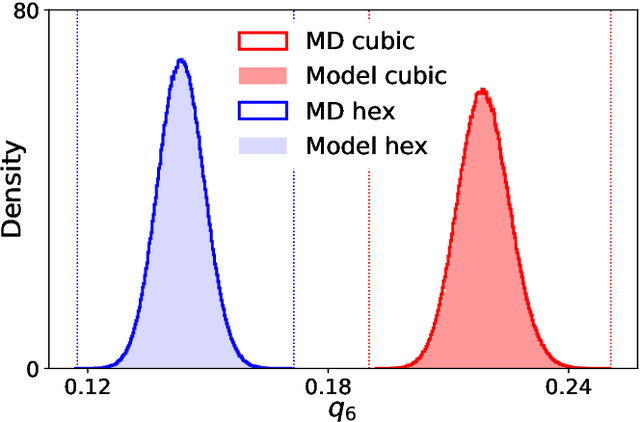
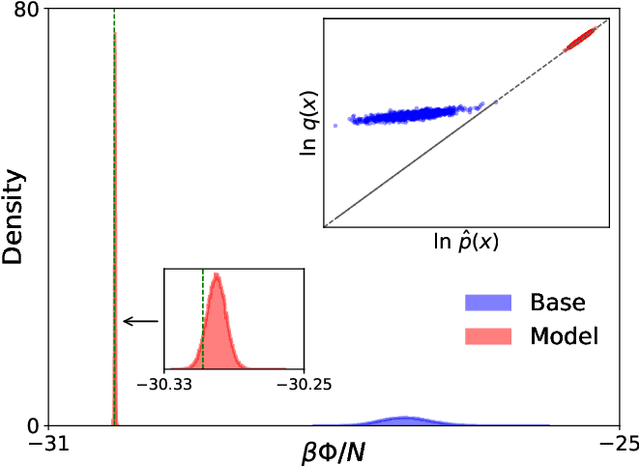
We present a machine-learning approach, based on normalizing flows, for modelling atomic solids. Our model transforms an analytically tractable base distribution into the target solid without requiring ground-truth samples for training. We report Helmholtz free energy estimates for cubic and hexagonal ice modelled as monatomic water as well as for a truncated and shifted Lennard-Jones system, and find them to be in excellent agreement with literature values and with estimates from established baseline methods. We further investigate structural properties and show that the model samples are nearly indistinguishable from the ones obtained with molecular dynamics. Our results thus demonstrate that normalizing flows can provide high-quality samples and free energy estimates of solids, without the need for multi-staging or for imposing restrictions on the crystal geometry.
The Lipschitz Constant of Self-Attention
Jun 08, 2020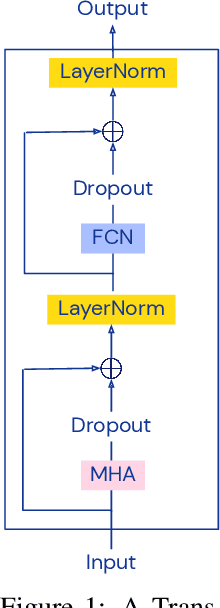
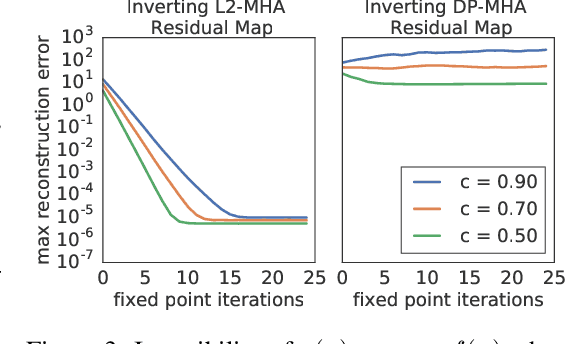
Lipschitz constants of neural networks have been explored in various contexts in deep learning, such as provable adversarial robustness, estimating Wasserstein distance, stabilising training of GANs, and formulating invertible neural networks. Such works have focused on bounding the Lipschitz constant of fully connected or convolutional networks, composed of linear maps and pointwise non-linearities. In this paper, we investigate the Lipschitz constant of self-attention, a non-linear neural network module widely used in sequence modelling. We prove that the standard dot-product self-attention is not Lipschitz, and propose an alternative L2 self-attention that is Lipschitz. We derive an upper bound on the Lipschitz constant of L2 self-attention and provide empirical evidence for its asymptotic tightness. To demonstrate the practical relevance of the theory, we formulate invertible self-attention and use it in a Transformer-based architecture for a character-level language modelling task.
Targeted free energy estimation via learned mappings
Feb 12, 2020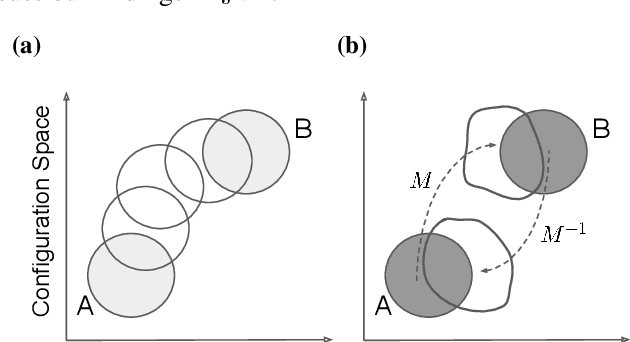
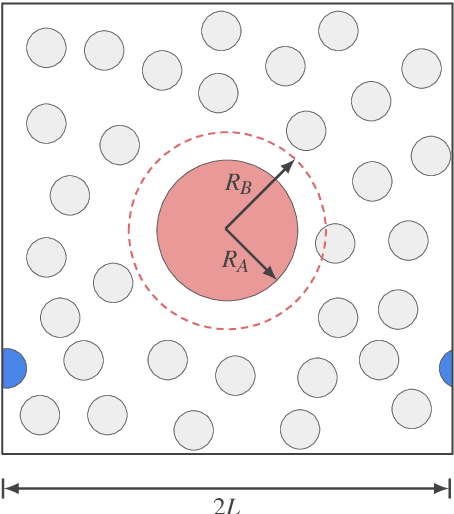
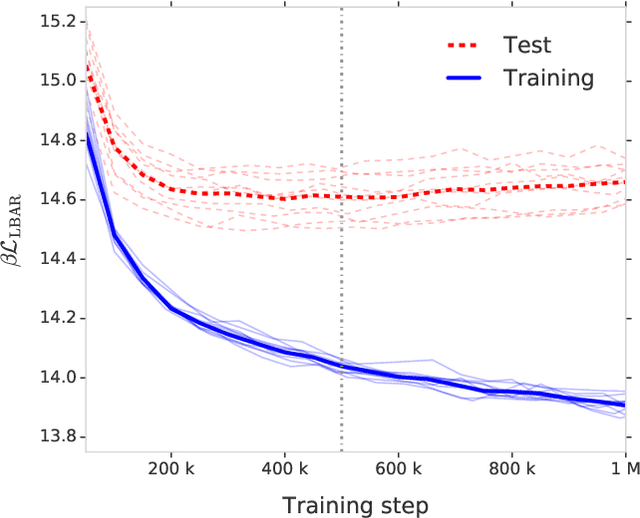
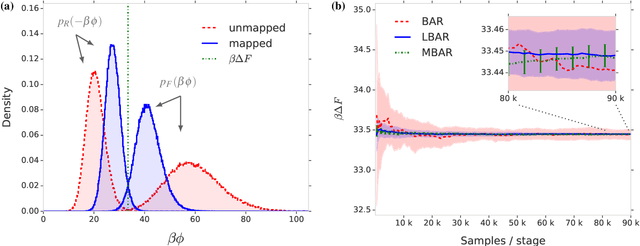
Free energy perturbation (FEP) was proposed by Zwanzig more than six decades ago as a method to estimate free energy differences, and has since inspired a huge body of related methods that use it as an integral building block. Being an importance sampling based estimator, however, FEP suffers from a severe limitation: the requirement of sufficient overlap between distributions. One strategy to mitigate this problem, called Targeted Free Energy Perturbation, uses a high-dimensional mapping in configuration space to increase overlap of the underlying distributions. Despite its potential, this method has attracted only limited attention due to the formidable challenge of formulating a tractable mapping. Here, we cast Targeted FEP as a machine learning (ML) problem in which the mapping is parameterized as a neural network that is optimized so as to increase overlap. We test our method on a fully-periodic solvation system, with a model that respects the inherent permutational and periodic symmetries of the problem. We demonstrate that our method leads to a substantial variance reduction in free energy estimates when compared against baselines.
On Contrastive Learning for Likelihood-free Inference
Feb 10, 2020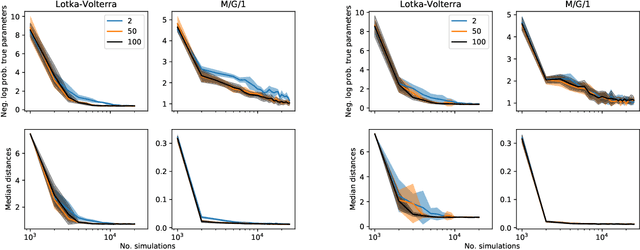
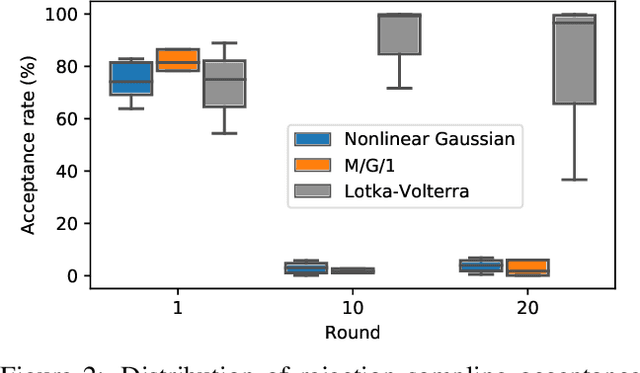
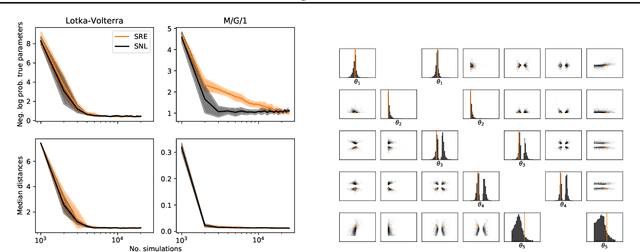
Likelihood-free methods perform parameter inference in stochastic simulator models where evaluating the likelihood is intractable but sampling synthetic data is possible. One class of methods for this likelihood-free problem uses a classifier to distinguish between pairs of parameter-observation samples generated using the simulator and pairs sampled from some reference distribution, which implicitly learns a density ratio proportional to the likelihood. Another popular class of methods fits a conditional distribution to the parameter posterior directly, and a particular recent variant allows for the use of flexible neural density estimators for this task. In this work, we show that both of these approaches can be unified under a general contrastive learning scheme, and clarify how they should be run and compared.
Causally Correct Partial Models for Reinforcement Learning
Feb 07, 2020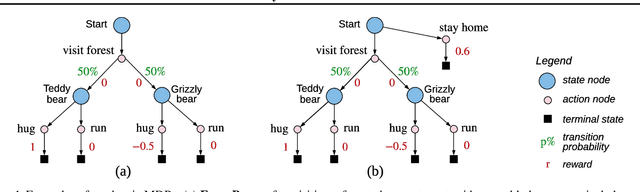


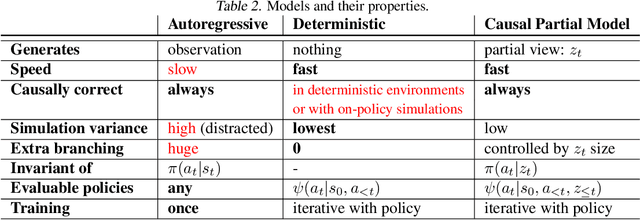
In reinforcement learning, we can learn a model of future observations and rewards, and use it to plan the agent's next actions. However, jointly modeling future observations can be computationally expensive or even intractable if the observations are high-dimensional (e.g. images). For this reason, previous works have considered partial models, which model only part of the observation. In this paper, we show that partial models can be causally incorrect: they are confounded by the observations they don't model, and can therefore lead to incorrect planning. To address this, we introduce a general family of partial models that are provably causally correct, yet remain fast because they do not need to fully model future observations.