 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Computation Graphs
Jun 22, 2023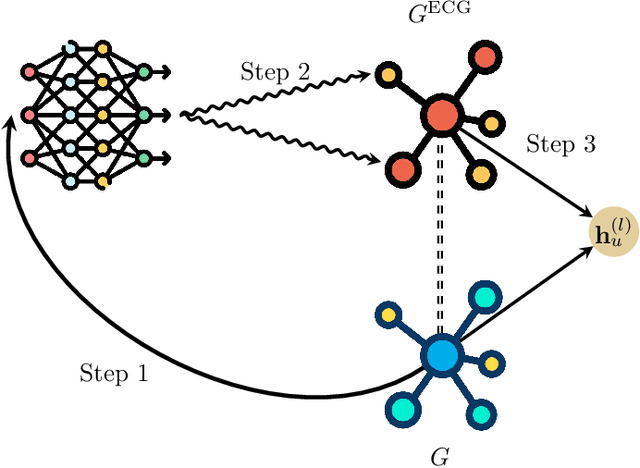
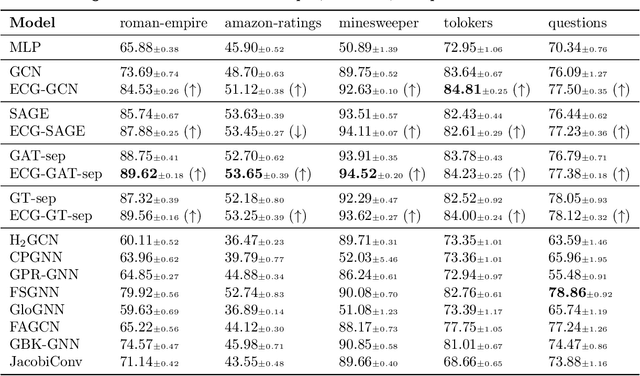
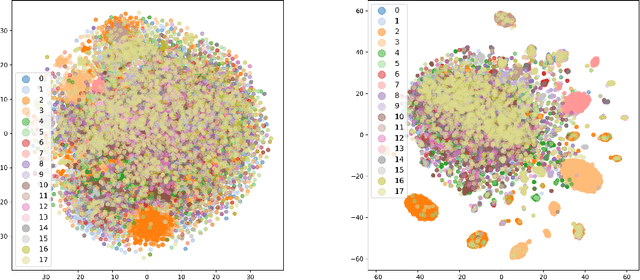
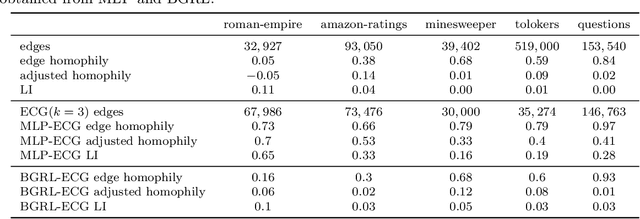
Graph neural networks (GNNs) have demonstrated success in modeling relational data, especially for data that exhibits homophily: when a connection between nodes tends to imply that they belong to the same class. However, while this assumption is true in many relevant situations, there are important real-world scenarios that violate this assumption, and this has spurred research into improving GNNs for these cases. In this work, we propose Evolving Computation Graphs (ECGs), a novel method for enhancing GNNs on heterophilic datasets. Our approach builds on prior theoretical insights linking node degree, high homophily, and inter vs intra-class embedding similarity by rewiring the GNNs' computation graph towards adding edges that connect nodes that are likely to be in the same class. We utilise weaker classifiers to identify these edges, ultimately improving GNN performance on non-homophilic data as a result. We evaluate ECGs on a diverse set of recently-proposed heterophilous datasets and demonstrate improvements over the relevant baselines. ECG presents a simple, intuitive and elegant approach for improving GNN performance on heterophilic datasets without requiring prior domain knowledge.
How does over-squashing affect the power of GNNs?
Jun 06, 2023Graph Neural Networks (GNNs) are the state-of-the-art model for machine learning on graph-structured data. The most popular class of GNNs operate by exchanging information between adjacent nodes, and are known as Message Passing Neural Networks (MPNNs). Given their widespread use, understanding the expressive power of MPNNs is a key question. However, existing results typically consider settings with uninformative node features. In this paper, we provide a rigorous analysis to determine which function classes of node features can be learned by an MPNN of a given capacity. We do so by measuring the level of pairwise interactions between nodes that MPNNs allow for. This measure provides a novel quantitative characterization of the so-called over-squashing effect, which is observed to occur when a large volume of messages is aggregated into fixed-size vectors. Using our measure, we prove that, to guarantee sufficient communication between pairs of nodes, the capacity of the MPNN must be large enough, depending on properties of the input graph structure, such as commute times. For many relevant scenarios, our analysis results in impossibility statements in practice, showing that over-squashing hinders the expressive power of MPNNs. We validate our theoretical findings through extensive controlled experiments and ablation studies.
Equivariant MuZero
Feb 09, 2023


Deep reinforcement learning repeatedly succeeds in closed, well-defined domains such as games (Chess, Go, StarCraft). The next frontier is real-world scenarios, where setups are numerous and varied. For this, agents need to learn the underlying rules governing the environment, so as to robustly generalise to conditions that differ from those they were trained on. Model-based reinforcement learning algorithms, such as the highly successful MuZero, aim to accomplish this by learning a world model. However, leveraging a world model has not consistently shown greater generalisation capabilities compared to model-free alternatives. In this work, we propose improving the data efficiency and generalisation capabilities of MuZero by explicitly incorporating the symmetries of the environment in its world-model architecture. We prove that, so long as the neural networks used by MuZero are equivariant to a particular symmetry group acting on the environment, the entirety of MuZero's action-selection algorithm will also be equivariant to that group. We evaluate Equivariant MuZero on procedurally-generated MiniPacman and on Chaser from the ProcGen suite: training on a set of mazes, and then testing on unseen rotated versions, demonstrating the benefits of equivariance. Further, we verify that our performance improvements hold even when only some of the components of Equivariant MuZero obey strict equivariance, which highlights the robustness of our construction.
Continuous Neural Algorithmic Planners
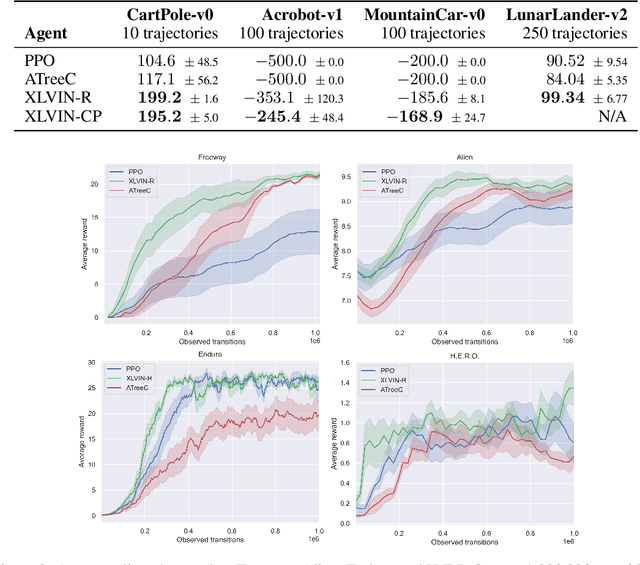
Nov 29, 2022Neural algorithmic reasoning studies the problem of learning algorithms with neural networks, especially with graph architectures. A recent proposal, XLVIN, reaps the benefits of using a graph neural network that simulates the value iteration algorithm in deep reinforcement learning agents. It allows model-free planning without access to privileged information about the environment, which is usually unavailable. However, XLVIN only supports discrete action spaces, and is hence nontrivially applicable to most tasks of real-world interest. We expand XLVIN to continuous action spaces by discretization, and evaluate several selective expansion policies to deal with the large planning graphs. Our proposal, CNAP, demonstrates how neural algorithmic reasoning can make a measurable impact in higher-dimensional continuous control settings, such as MuJoCo, bringing gains in low-data settings and outperforming model-free baselines.
Expander Graph Propagation
Oct 06, 2022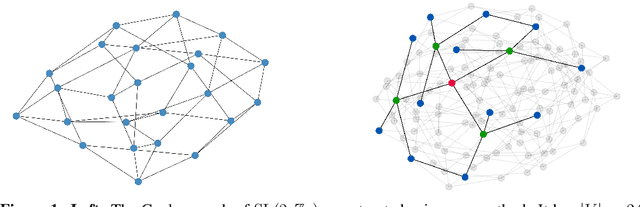



Deploying graph neural networks (GNNs) on whole-graph classification or regression tasks is known to be challenging: it often requires computing node features that are mindful of both local interactions in their neighbourhood and the global context of the graph structure. GNN architectures that navigate this space need to avoid pathological behaviours, such as bottlenecks and oversquashing, while ideally having linear time and space complexity requirements. In this work, we propose an elegant approach based on propagating information over expander graphs. We provide an efficient method for constructing expander graphs of a given size, and use this insight to propose the EGP model. We show that EGP is able to address all of the above concerns, while requiring minimal effort to set up, and provide evidence of its empirical utility on relevant datasets and baselines in the Open Graph Benchmark. Importantly, using expander graphs as a template for message passing necessarily gives rise to negative curvature. While this appears to be counterintuitive in light of recent related work on oversquashing, we theoretically demonstrate that negatively curved edges are likely to be required to obtain scalable message passing without bottlenecks. To the best of our knowledge, this is a previously unstudied result in the context of graph representation learning, and we believe our analysis paves the way to a novel class of scalable methods to counter oversquashing in GNNs.
A Generalist Neural Algorithmic Learner
Sep 22, 2022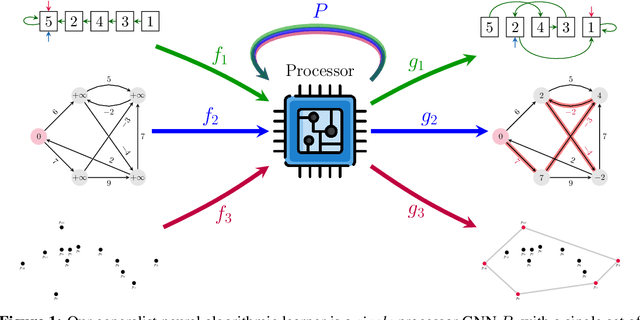
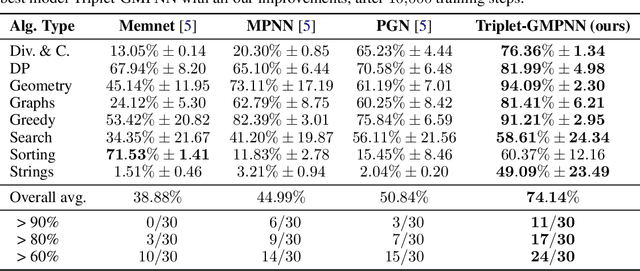
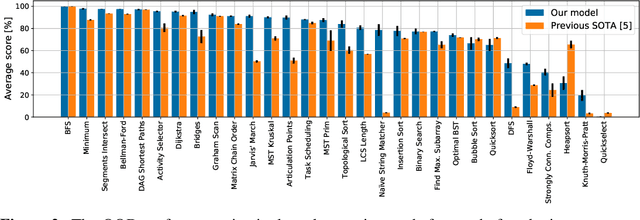
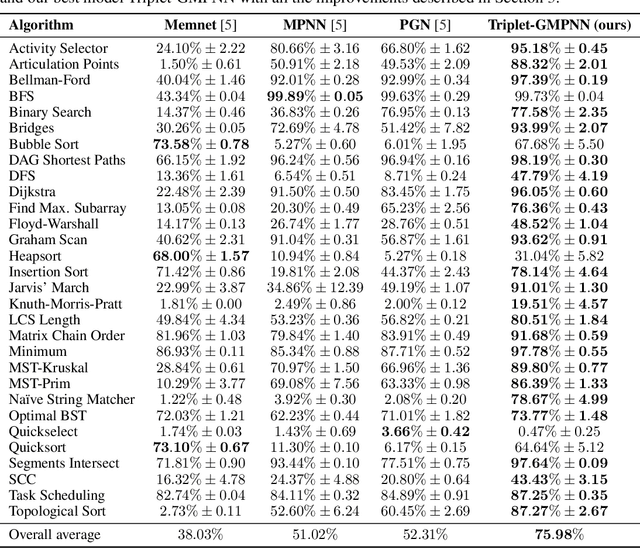
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner -- a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
How to transfer algorithmic reasoning knowledge to learn new algorithms?
Oct 26, 2021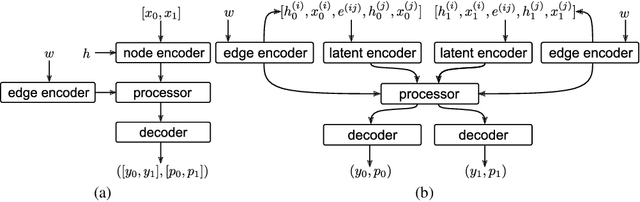

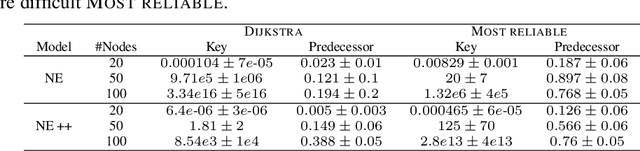
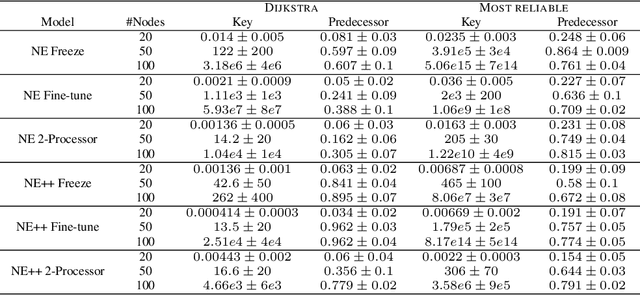
Learning to execute algorithms is a fundamental problem that has been widely studied. Prior work~\cite{veli19neural} has shown that to enable systematic generalisation on graph algorithms it is critical to have access to the intermediate steps of the program/algorithm. In many reasoning tasks, where algorithmic-style reasoning is important, we only have access to the input and output examples. Thus, inspired by the success of pre-training on similar tasks or data in Natural Language Processing (NLP) and Computer Vision, we set out to study how we can transfer algorithmic reasoning knowledge. Specifically, we investigate how we can use algorithms for which we have access to the execution trace to learn to solve similar tasks for which we do not. We investigate two major classes of graph algorithms, parallel algorithms such as breadth-first search and Bellman-Ford and sequential greedy algorithms such as Prim and Dijkstra. Due to the fundamental differences between algorithmic reasoning knowledge and feature extractors such as used in Computer Vision or NLP, we hypothesise that standard transfer techniques will not be sufficient to achieve systematic generalisation. To investigate this empirically we create a dataset including 9 algorithms and 3 different graph types. We validate this empirically and show how instead multi-task learning can be used to achieve the transfer of algorithmic reasoning knowledge.
Neural Algorithmic Reasoners are Implicit Planners
Oct 11, 2021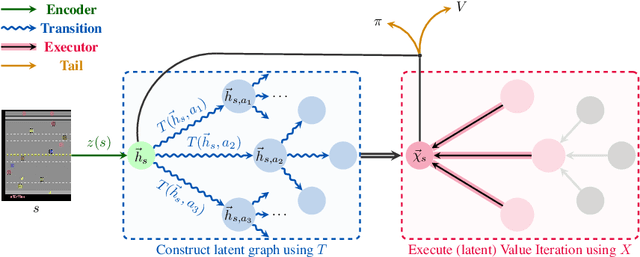

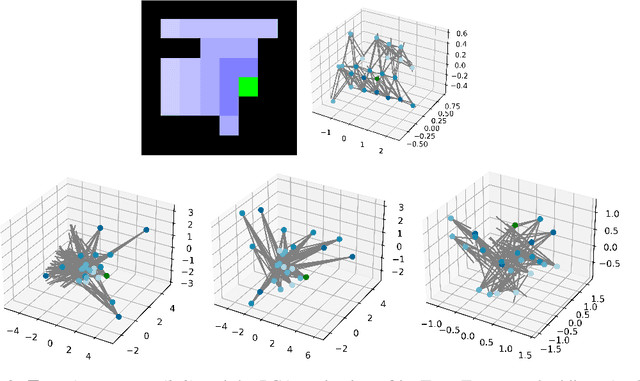
Implicit planning has emerged as an elegant technique for combining learned models of the world with end-to-end model-free reinforcement learning. We study the class of implicit planners inspired by value iteration, an algorithm that is guaranteed to yield perfect policies in fully-specified tabular environments. We find that prior approaches either assume that the environment is provided in such a tabular form -- which is highly restrictive -- or infer "local neighbourhoods" of states to run value iteration over -- for which we discover an algorithmic bottleneck effect. This effect is caused by explicitly running the planning algorithm based on scalar predictions in every state, which can be harmful to data efficiency if such scalars are improperly predicted. We propose eXecuted Latent Value Iteration Networks (XLVINs), which alleviate the above limitations. Our method performs all planning computations in a high-dimensional latent space, breaking the algorithmic bottleneck. It maintains alignment with value iteration by carefully leveraging neural graph-algorithmic reasoning and contrastive self-supervised learning. Across eight low-data settings -- including classical control, navigation and Atari -- XLVINs provide significant improvements to data efficiency against value iteration-based implicit planners, as well as relevant model-free baselines. Lastly, we empirically verify that XLVINs can closely align with value iteration.
Large-scale graph representation learning with very deep GNNs and self-supervision
Jul 20, 2021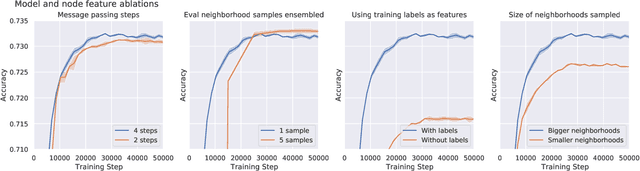
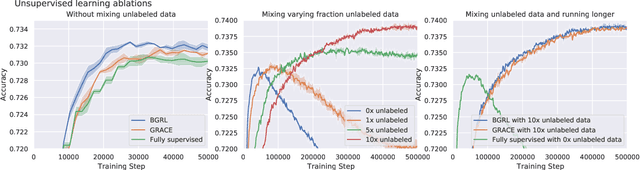
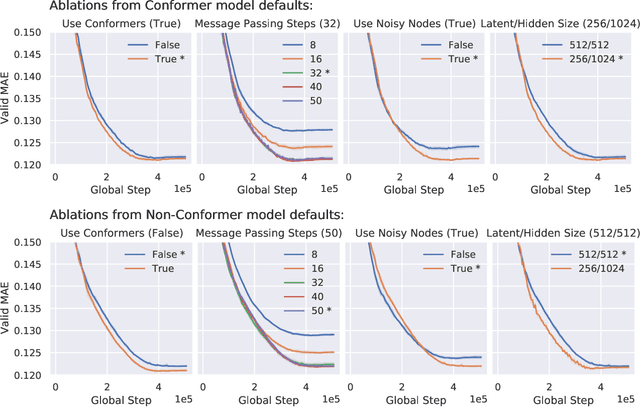
Effectively and efficiently deploying graph neural networks (GNNs) at scale remains one of the most challenging aspects of graph representation learning. Many powerful solutions have only ever been validated on comparatively small datasets, often with counter-intuitive outcomes -- a barrier which has been broken by the Open Graph Benchmark Large-Scale Challenge (OGB-LSC). We entered the OGB-LSC with two large-scale GNNs: a deep transductive node classifier powered by bootstrapping, and a very deep (up to 50-layer) inductive graph regressor regularised by denoising objectives. Our models achieved an award-level (top-3) performance on both the MAG240M and PCQM4M benchmarks. In doing so, we demonstrate evidence of scalable self-supervised graph representation learning, and utility of very deep GNNs -- both very important open issues. Our code is publicly available at: https://github.com/deepmind/deepmind-research/tree/master/ogb_lsc.
Neural message passing for joint paratope-epitope prediction
May 31, 2021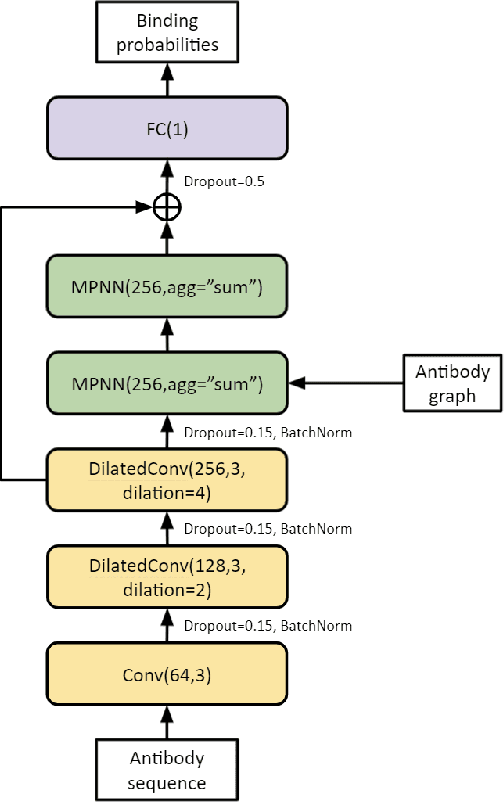

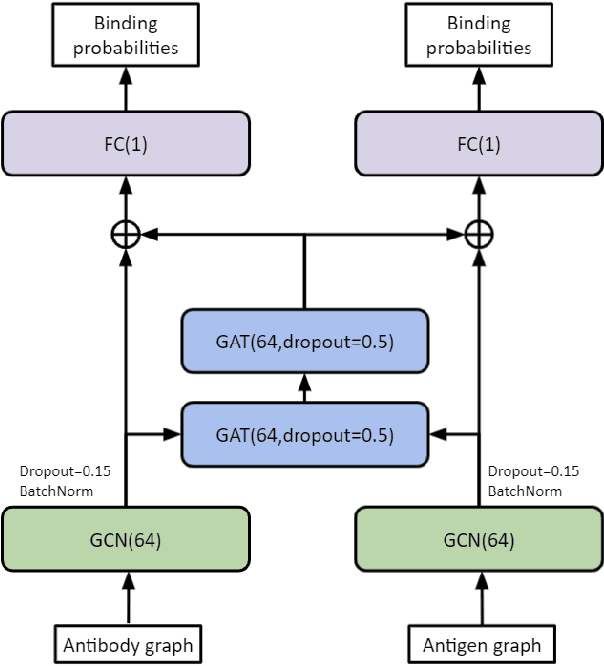
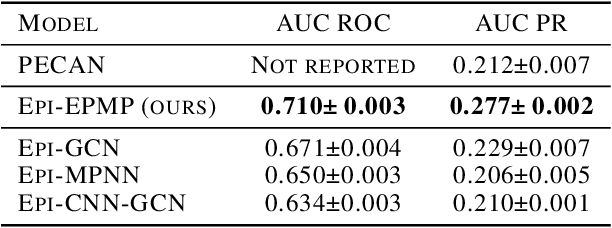
Antibodies are proteins in the immune system which bind to antigens to detect and neutralise them. The binding sites in an antibody-antigen interaction are known as the paratope and epitope, respectively, and the prediction of these regions is key to vaccine and synthetic antibody development. Contrary to prior art, we argue that paratope and epitope predictors require asymmetric treatment, and propose distinct neural message passing architectures that are geared towards the specific aspects of paratope and epitope prediction, respectively. We obtain significant improvements on both tasks, setting the new state-of-the-art and recovering favourable qualitative predictions on antigens of relevance to COVID-19.