 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient and Robust Linguistic Emotion Diagnosis for Mental Health via Multi-Agent Instruction Refinement
Jan 20, 2026Linguistic expressions of emotions such as depression, anxiety, and trauma-related states are pervasive in clinical notes, counseling dialogues, and online mental health communities, and accurate recognition of these emotions is essential for clinical triage, risk assessment, and timely intervention. Although large language models (LLMs) have demonstrated strong generalization ability in emotion analysis tasks, their diagnostic reliability in high-stakes, context-intensive medical settings remains highly sensitive to prompt design. Moreover, existing methods face two key challenges: emotional comorbidity, in which multiple intertwined emotional states complicate prediction, and inefficient exploration of clinically relevant cues. To address these challenges, we propose APOLO (Automated Prompt Optimization for Linguistic Emotion Diagnosis), a framework that systematically explores a broader and finer-grained prompt space to improve diagnostic efficiency and robustness. APOLO formulates instruction refinement as a Partially Observable Markov Decision Process and adopts a multi-agent collaboration mechanism involving Planner, Teacher, Critic, Student, and Target roles. Within this closed-loop framework, the Planner defines an optimization trajectory, while the Teacher-Critic-Student agents iteratively refine prompts to enhance reasoning stability and effectiveness, and the Target agent determines whether to continue optimization based on performance evaluation. Experimental results show that APOLO consistently improves diagnostic accuracy and robustness across domain-specific and stratified benchmarks, demonstrating a scalable and generalizable paradigm for trustworthy LLM applications in mental healthcare.
ErrEval: Error-Aware Evaluation for Question Generation through Explicit Diagnostics
Jan 15, 2026Automatic Question Generation (QG) often produces outputs with critical defects, such as factual hallucinations and answer mismatches. However, existing evaluation methods, including LLM-based evaluators, mainly adopt a black-box and holistic paradigm without explicit error modeling, leading to the neglect of such defects and overestimation of question quality. To address this issue, we propose ErrEval, a flexible and Error-aware Evaluation framework that enhances QG evaluation through explicit error diagnostics. Specifically, ErrEval reformulates evaluation as a two-stage process of error diagnosis followed by informed scoring. At the first stage, a lightweight plug-and-play Error Identifier detects and categorizes common errors across structural, linguistic, and content-related aspects. These diagnostic signals are then incorporated as explicit evidence to guide LLM evaluators toward more fine-grained and grounded judgments. Extensive experiments on three benchmarks demonstrate the effectiveness of ErrEval, showing that incorporating explicit diagnostics improves alignment with human judgments. Further analyses confirm that ErrEval effectively mitigates the overestimation of low-quality questions.
MAXS: Meta-Adaptive Exploration with LLM Agents
Jan 14, 2026Large Language Model (LLM) Agents exhibit inherent reasoning abilities through the collaboration of multiple tools. However, during agent inference, existing methods often suffer from (i) locally myopic generation, due to the absence of lookahead, and (ii) trajectory instability, where minor early errors can escalate into divergent reasoning paths. These issues make it difficult to balance global effectiveness and computational efficiency. To address these two issues, we propose meta-adaptive exploration with LLM agents https://github.com/exoskeletonzj/MAXS, a meta-adaptive reasoning framework based on LLM Agents that flexibly integrates tool execution and reasoning planning. MAXS employs a lookahead strategy to extend reasoning paths a few steps ahead, estimating the advantage value of tool usage, and combines step consistency variance and inter-step trend slopes to jointly select stable, consistent, and high-value reasoning steps. Additionally, we introduce a trajectory convergence mechanism that controls computational cost by halting further rollouts once path consistency is achieved, enabling a balance between resource efficiency and global effectiveness in multi-tool reasoning. We conduct extensive empirical studies across three base models (MiMo-VL-7B, Qwen2.5-VL-7B, Qwen2.5-VL-32B) and five datasets, demonstrating that MAXS consistently outperforms existing methods in both performance and inference efficiency. Further analysis confirms the effectiveness of our lookahead strategy and tool usage.
$A^3$-Bench: Benchmarking Memory-Driven Scientific Reasoning via Anchor and Attractor Activation
Jan 14, 2026Scientific reasoning relies not only on logical inference but also on activating prior knowledge and experiential structures. Memory can efficiently reuse knowledge and enhance reasoning consistency and stability. However, existing benchmarks mainly evaluate final answers or step-by-step coherence, overlooking the \textit{memory-driven} mechanisms that underlie human reasoning, which involves activating anchors and attractors, then integrating them into multi-step inference. To address this gap, we propose $A^3$-Bench~ https://a3-bench.github.io, a benchmark designed to evaluate scientific reasoning through dual-scale memory-driven activation, grounded in Anchor and Attractor Activation. First, we annotate 2,198 science reasoning problems across domains using the SAPM process(subject, anchor & attractor, problem, and memory developing). Second, we introduce a dual-scale memory evaluation framework utilizing anchors and attractors, along with the AAUI(Anchor--Attractor Utilization Index) metric to measure memory activation rates. Finally, through experiments with various base models and paradigms, we validate $A^3$-Bench and analyze how memory activation impacts reasoning performance, providing insights into memory-driven scientific reasoning.
Schrödinger's Navigator: Imagining an Ensemble of Futures for Zero-Shot Object Navigation
Dec 24, 2025Zero-shot object navigation (ZSON) requires a robot to locate a target object in a previously unseen environment without relying on pre-built maps or task-specific training. However, existing ZSON methods often struggle in realistic and cluttered environments, particularly when the scene contains heavy occlusions, unknown risks, or dynamically moving target objects. To address these challenges, we propose \textbf{Schrödinger's Navigator}, a navigation framework inspired by Schrödinger's thought experiment on uncertainty. The framework treats unobserved space as a set of plausible future worlds and reasons over them before acting. Conditioned on egocentric visual inputs and three candidate trajectories, a trajectory-conditioned 3D world model imagines future observations along each path. This enables the agent to see beyond occlusions and anticipate risks in unseen regions without requiring extra detours or dense global mapping. The imagined 3D observations are fused into the navigation map and used to update a value map. These updates guide the policy toward trajectories that avoid occlusions, reduce exposure to uncertain space, and better track moving targets. Experiments on a Go2 quadruped robot across three challenging scenarios, including severe static occlusions, unknown risks, and dynamically moving targets, show that Schrödinger's Navigator consistently outperforms strong ZSON baselines in self-localization, object localization, and overall Success Rate in occlusion-heavy environments. These results demonstrate the effectiveness of trajectory-conditioned 3D imagination in enabling robust zero-shot object navigation.
Structural Invariance Matters: Rethinking Graph Rewiring through Graph Metrics
Oct 23, 2025Graph rewiring has emerged as a key technique to alleviate over-squashing in Graph Neural Networks (GNNs) and Graph Transformers by modifying the graph topology to improve information flow. While effective, rewiring inherently alters the graph's structure, raising the risk of distorting important topology-dependent signals. Yet, despite the growing use of rewiring, little is known about which structural properties must be preserved to ensure both performance gains and structural fidelity. In this work, we provide the first systematic analysis of how rewiring affects a range of graph structural metrics, and how these changes relate to downstream task performance. We study seven diverse rewiring strategies and correlate changes in local and global graph properties with node classification accuracy. Our results reveal a consistent pattern: successful rewiring methods tend to preserve local structure while allowing for flexibility in global connectivity. These findings offer new insights into the design of effective rewiring strategies, bridging the gap between graph theory and practical GNN optimization.
RePainter: Empowering E-commerce Object Removal via Spatial-matting Reinforcement Learning
Oct 09, 2025In web data, product images are central to boosting user engagement and advertising efficacy on e-commerce platforms, yet the intrusive elements such as watermarks and promotional text remain major obstacles to delivering clear and appealing product visuals. Although diffusion-based inpainting methods have advanced, they still face challenges in commercial settings due to unreliable object removal and limited domain-specific adaptation. To tackle these challenges, we propose Repainter, a reinforcement learning framework that integrates spatial-matting trajectory refinement with Group Relative Policy Optimization (GRPO). Our approach modulates attention mechanisms to emphasize background context, generating higher-reward samples and reducing unwanted object insertion. We also introduce a composite reward mechanism that balances global, local, and semantic constraints, effectively reducing visual artifacts and reward hacking. Additionally, we contribute EcomPaint-100K, a high-quality, large-scale e-commerce inpainting dataset, and a standardized benchmark EcomPaint-Bench for fair evaluation. Extensive experiments demonstrate that Repainter significantly outperforms state-of-the-art methods, especially in challenging scenes with intricate compositions. We will release our code and weights upon acceptance.
SoK: Large Language Model Copyright Auditing via Fingerprinting
Aug 27, 2025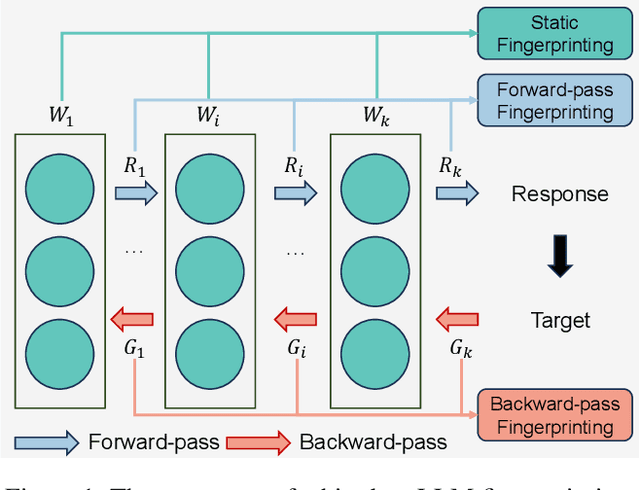

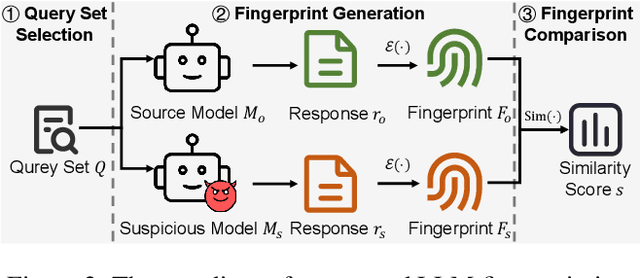

The broad capabilities and substantial resources required to train Large Language Models (LLMs) make them valuable intellectual property, yet they remain vulnerable to copyright infringement, such as unauthorized use and model theft. LLM fingerprinting, a non-intrusive technique that extracts and compares the distinctive features from LLMs to identify infringements, offers a promising solution to copyright auditing. However, its reliability remains uncertain due to the prevalence of diverse model modifications and the lack of standardized evaluation. In this SoK, we present the first comprehensive study of LLM fingerprinting. We introduce a unified framework and formal taxonomy that categorizes existing methods into white-box and black-box approaches, providing a structured overview of the state of the art. We further propose LeaFBench, the first systematic benchmark for evaluating LLM fingerprinting under realistic deployment scenarios. Built upon mainstream foundation models and comprising 149 distinct model instances, LeaFBench integrates 13 representative post-development techniques, spanning both parameter-altering methods (e.g., fine-tuning, quantization) and parameter-independent mechanisms (e.g., system prompts, RAG). Extensive experiments on LeaFBench reveal the strengths and weaknesses of existing methods, thereby outlining future research directions and critical open problems in this emerging field. The code is available at https://github.com/shaoshuo-ss/LeaFBench.
DSR-Bench: Evaluating the Structural Reasoning Abilities of LLMs via Data Structures
May 29, 2025Large language models (LLMs) are increasingly deployed for real-world tasks that fundamentally involve data manipulation. A core requirement across these tasks is the ability to perform structural reasoning--that is, to understand and reason about data relationships. For example, customer requests require a temporal ordering, which can be represented by data structures such as queues. However, existing benchmarks primarily focus on high-level, application-driven evaluations without isolating this fundamental capability. To address this gap, we introduce DSR-Bench, a novel benchmark evaluating LLMs' structural reasoning capabilities through data structures, which provide interpretable representations of data relationships. DSR-Bench includes 20 data structures, 35 operations, and 4,140 problem instances, organized hierarchically for fine-grained analysis of reasoning limitations. Our evaluation pipeline is fully automated and deterministic, eliminating subjective human or model-based judgments. Its synthetic nature also ensures scalability and minimizes data contamination risks. We benchmark nine state-of-the-art LLMs. Our analysis shows that instruction-tuned models struggle with basic multi-attribute and multi-hop reasoning. Furthermore, while reasoning-oriented models perform better, they remain fragile on complex and hybrid structures, with the best model achieving an average score of only 47% on the challenge subset. Crucially, models often perform poorly on multi-dimensional data and natural language task descriptions, highlighting a critical gap for real-world deployment.
Primal-Dual Neural Algorithmic Reasoning
May 29, 2025Neural Algorithmic Reasoning (NAR) trains neural networks to simulate classical algorithms, enabling structured and interpretable reasoning over complex data. While prior research has predominantly focused on learning exact algorithms for polynomial-time-solvable problems, extending NAR to harder problems remains an open challenge. In this work, we introduce a general NAR framework grounded in the primal-dual paradigm, a classical method for designing efficient approximation algorithms. By leveraging a bipartite representation between primal and dual variables, we establish an alignment between primal-dual algorithms and Graph Neural Networks. Furthermore, we incorporate optimal solutions from small instances to greatly enhance the model's reasoning capabilities. Our empirical results demonstrate that our model not only simulates but also outperforms approximation algorithms for multiple tasks, exhibiting robust generalization to larger and out-of-distribution graphs. Moreover, we highlight the framework's practical utility by integrating it with commercial solvers and applying it to real-world datasets.