 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
LMCD: Language Models are Zeroshot Cognitive Diagnosis Learners
May 27, 2025Cognitive Diagnosis (CD) has become a critical task in AI-empowered education, supporting personalized learning by accurately assessing students' cognitive states. However, traditional CD models often struggle in cold-start scenarios due to the lack of student-exercise interaction data. Recent NLP-based approaches leveraging pre-trained language models (PLMs) have shown promise by utilizing textual features but fail to fully bridge the gap between semantic understanding and cognitive profiling. In this work, we propose Language Models as Zeroshot Cognitive Diagnosis Learners (LMCD), a novel framework designed to handle cold-start challenges by harnessing large language models (LLMs). LMCD operates via two primary phases: (1) Knowledge Diffusion, where LLMs generate enriched contents of exercises and knowledge concepts (KCs), establishing stronger semantic links; and (2) Semantic-Cognitive Fusion, where LLMs employ causal attention mechanisms to integrate textual information and student cognitive states, creating comprehensive profiles for both students and exercises. These representations are efficiently trained with off-the-shelf CD models. Experiments on two real-world datasets demonstrate that LMCD significantly outperforms state-of-the-art methods in both exercise-cold and domain-cold settings. The code is publicly available at https://github.com/TAL-auroraX/LMCD
ResoFilter: Fine-grained Synthetic Data Filtering for Large Language Models through Data-Parameter Resonance Analysis
Dec 20, 2024



Large language models (LLMs) have shown remarkable effectiveness across various domains, with data augmentation methods utilizing GPT for synthetic data generation becoming prevalent. However, the quality and utility of augmented data remain questionable, and current methods lack clear metrics for evaluating data characteristics. To address these challenges, we propose ResoFilter, a novel method that integrates models, data, and tasks to refine datasets. ResoFilter leverages the fine-tuning process to obtain Data-Parameter features for data selection, offering improved interpretability by representing data characteristics through model weights. Our experiments demonstrate that ResoFilter achieves comparable results to full-scale fine-tuning using only half the data in mathematical tasks and exhibits strong generalization across different models and domains. This method provides valuable insights for constructing synthetic datasets and evaluating high-quality data, offering a promising solution for enhancing data augmentation techniques and improving training dataset quality for LLMs. For reproducibility, we will release our code and data upon acceptance.
ResoFilter: Rine-grained Synthetic Data Filtering for Large Language Models through Data-Parameter Resonance Analysis
Dec 19, 2024Large language models (LLMs) have shown remarkable effectiveness across various domains, with data augmentation methods utilizing GPT for synthetic data generation becoming prevalent. However, the quality and utility of augmented data remain questionable, and current methods lack clear metrics for evaluating data characteristics. To address these challenges, we propose ResoFilter, a novel method that integrates models, data, and tasks to refine datasets. ResoFilter leverages the fine-tuning process to obtain Data-Parameter features for data selection, offering improved interpretability by representing data characteristics through model weights. Our experiments demonstrate that ResoFilter achieves comparable results to full-scale fine-tuning using only half the data in mathematical tasks and exhibits strong generalization across different models and domains. This method provides valuable insights for constructing synthetic datasets and evaluating high-quality data, offering a promising solution for enhancing data augmentation techniques and improving training dataset quality for LLMs. For reproducibility, we will release our code and data upon acceptance.
Radiant: Large-scale 3D Gaussian Rendering based on Hierarchical Framework
Dec 07, 2024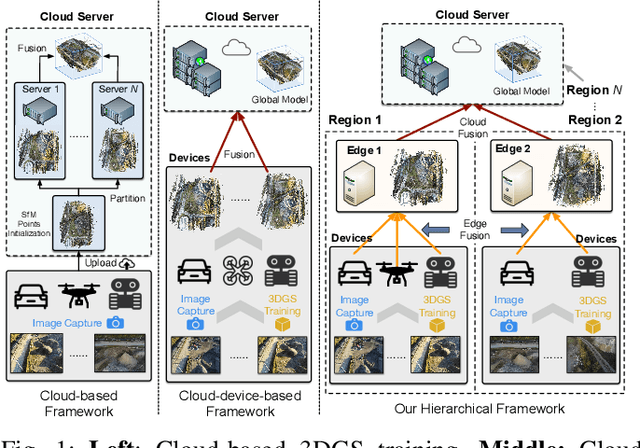
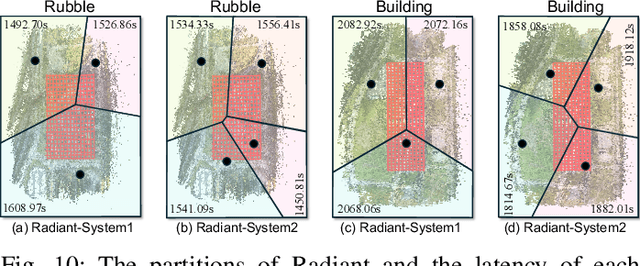
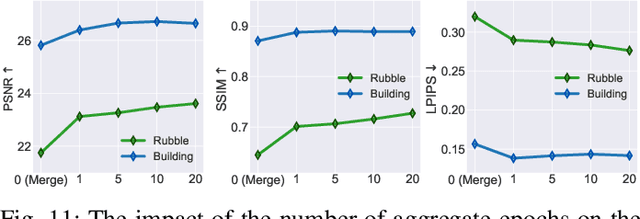

With the advancement of computer vision, the recently emerged 3D Gaussian Splatting (3DGS) has increasingly become a popular scene reconstruction algorithm due to its outstanding performance. Distributed 3DGS can efficiently utilize edge devices to directly train on the collected images, thereby offloading computational demands and enhancing efficiency. However, traditional distributed frameworks often overlook computational and communication challenges in real-world environments, hindering large-scale deployment and potentially posing privacy risks. In this paper, we propose Radiant, a hierarchical 3DGS algorithm designed for large-scale scene reconstruction that considers system heterogeneity, enhancing the model performance and training efficiency. Via extensive empirical study, we find that it is crucial to partition the regions for each edge appropriately and allocate varying camera positions to each device for image collection and training. The core of Radiant is partitioning regions based on heterogeneous environment information and allocating workloads to each device accordingly. Furthermore, we provide a 3DGS model aggregation algorithm that enhances the quality and ensures the continuity of models' boundaries. Finally, we develop a testbed, and experiments demonstrate that Radiant improved reconstruction quality by up to 25.7\% and reduced up to 79.6\% end-to-end latency.
TSO: Self-Training with Scaled Preference Optimization
Aug 31, 2024



Enhancing the conformity of large language models (LLMs) to human preferences remains an ongoing research challenge. Recently, offline approaches such as Direct Preference Optimization (DPO) have gained prominence as attractive options due to offering effective improvement in simple, efficient, and stable without interactions with reward models. However, these offline preference optimization methods highly rely on the quality of pairwise preference samples. Meanwhile, numerous iterative methods require additional training of reward models to select positive and negative samples from the model's own generated responses for preference learning. Furthermore, as LLMs' capabilities advance, it is quite challenging to continuously construct high-quality positive and negative preference instances from the model's outputs due to the lack of diversity. To tackle these challenges, we propose TSO, or Self-Training with Scaled Preference Optimization, a framework for preference optimization that conducts self-training preference learning without training an additional reward model. TSO enhances the diversity of responses by constructing a model matrix and incorporating human preference responses. Furthermore, TSO introduces corrections for model preference errors through human and AI feedback. Finally, TSO adopts iterative and dual clip reward strategies to update the reference model and its responses, adaptively adjusting preference data and balancing the optimization process. Experimental results demonstrate that TSO outperforms existing mainstream methods on various alignment evaluation benchmarks, providing practical insight into preference data construction and model training strategies in the alignment domain.
Scalable Model Editing via Customized Expert Networks
Apr 03, 2024Addressing the issue of hallucinations and outdated knowledge in large language models is critical for their reliable application. Model Editing presents a promising avenue for mitigating these challenges in a cost-effective manner. However, existing methods often suffer from unsatisfactory generalization and unintended effects on unrelated samples. To overcome these limitations, we introduce a novel approach: Scalable Model Editing via Customized Expert Networks (SCEN), which is a two-stage continuous training paradigm. Specifically, in the first stage, we train lightweight expert networks individually for each piece of knowledge that needs to be updated. Subsequently, we train a corresponding neuron for each expert to control the activation state of that expert. Our experiments on two different sizes of open-source large language models, the Llama2 7B and 13B, achieve state-of-the-art results compared to existing mainstream Model Editing methods. Our code is available at https: //github.com/TAL-auroraX/SCEN