 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
Data Efficacy for Language Model Training
Jun 26, 2025Data is fundamental to the training of language models (LM). Recent research has been dedicated to data efficiency, which aims to maximize performance by selecting a minimal or optimal subset of training data. Techniques such as data filtering, sampling, and selection play a crucial role in this area. To complement it, we define Data Efficacy, which focuses on maximizing performance by optimizing the organization of training data and remains relatively underexplored. This work introduces a general paradigm, DELT, for considering data efficacy in LM training, which highlights the significance of training data organization. DELT comprises three components: Data Scoring, Data Selection, and Data Ordering. Among these components, we design Learnability-Quality Scoring (LQS), as a new instance of Data Scoring, which considers both the learnability and quality of each data sample from the gradient consistency perspective. We also devise Folding Ordering (FO), as a novel instance of Data Ordering, which addresses issues such as model forgetting and data distribution bias. Comprehensive experiments validate the data efficacy in LM training, which demonstrates the following: Firstly, various instances of the proposed DELT enhance LM performance to varying degrees without increasing the data scale and model size. Secondly, among these instances, the combination of our proposed LQS for data scoring and Folding for data ordering achieves the most significant improvement. Lastly, data efficacy can be achieved together with data efficiency by applying data selection. Therefore, we believe that data efficacy is a promising foundational area in LM training.
CoSurfGS:Collaborative 3D Surface Gaussian Splatting with Distributed Learning for Large Scene Reconstruction
Dec 23, 20243D Gaussian Splatting (3DGS) has demonstrated impressive performance in scene reconstruction. However, most existing GS-based surface reconstruction methods focus on 3D objects or limited scenes. Directly applying these methods to large-scale scene reconstruction will pose challenges such as high memory costs, excessive time consumption, and lack of geometric detail, which makes it difficult to implement in practical applications. To address these issues, we propose a multi-agent collaborative fast 3DGS surface reconstruction framework based on distributed learning for large-scale surface reconstruction. Specifically, we develop local model compression (LMC) and model aggregation schemes (MAS) to achieve high-quality surface representation of large scenes while reducing GPU memory consumption. Extensive experiments on Urban3d, MegaNeRF, and BlendedMVS demonstrate that our proposed method can achieve fast and scalable high-fidelity surface reconstruction and photorealistic rendering. Our project page is available at \url{https://gyy456.github.io/CoSurfGS}.
Radiant: Large-scale 3D Gaussian Rendering based on Hierarchical Framework
Dec 07, 2024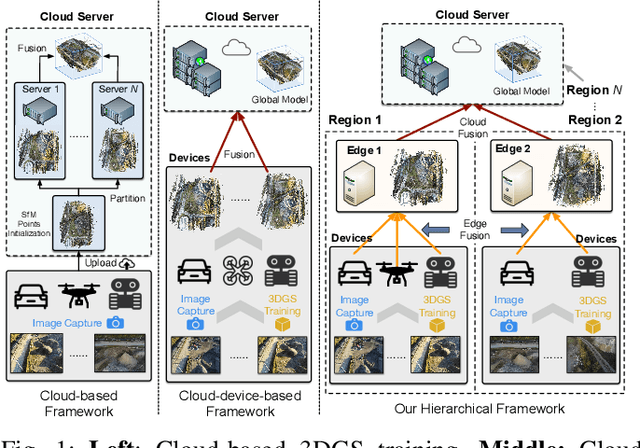
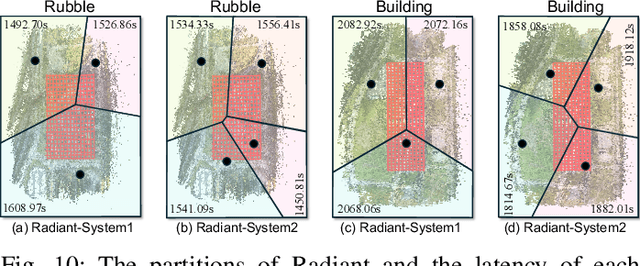
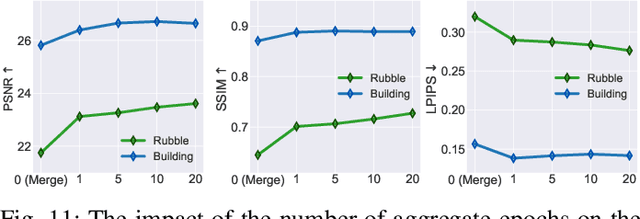

With the advancement of computer vision, the recently emerged 3D Gaussian Splatting (3DGS) has increasingly become a popular scene reconstruction algorithm due to its outstanding performance. Distributed 3DGS can efficiently utilize edge devices to directly train on the collected images, thereby offloading computational demands and enhancing efficiency. However, traditional distributed frameworks often overlook computational and communication challenges in real-world environments, hindering large-scale deployment and potentially posing privacy risks. In this paper, we propose Radiant, a hierarchical 3DGS algorithm designed for large-scale scene reconstruction that considers system heterogeneity, enhancing the model performance and training efficiency. Via extensive empirical study, we find that it is crucial to partition the regions for each edge appropriately and allocate varying camera positions to each device for image collection and training. The core of Radiant is partitioning regions based on heterogeneous environment information and allocating workloads to each device accordingly. Furthermore, we provide a 3DGS model aggregation algorithm that enhances the quality and ensures the continuity of models' boundaries. Finally, we develop a testbed, and experiments demonstrate that Radiant improved reconstruction quality by up to 25.7\% and reduced up to 79.6\% end-to-end latency.
LTRL: Boosting Long-tail Recognition via Reflective Learning
Jul 17, 2024



In real-world scenarios, where knowledge distributions exhibit long-tail. Humans manage to master knowledge uniformly across imbalanced distributions, a feat attributed to their diligent practices of reviewing, summarizing, and correcting errors. Motivated by this learning process, we propose a novel learning paradigm, called reflecting learning, in handling long-tail recognition. Our method integrates three processes for reviewing past predictions during training, summarizing and leveraging the feature relation across classes, and correcting gradient conflict for loss functions. These designs are lightweight enough to plug and play with existing long-tail learning methods, achieving state-of-the-art performance in popular long-tail visual benchmarks. The experimental results highlight the great potential of reflecting learning in dealing with long-tail recognition.
GGRt: Towards Pose-free Generalizable 3D Gaussian Splatting in Real-time
Mar 19, 2024



This paper presents GGRt, a novel approach to generalizable novel view synthesis that alleviates the need for real camera poses, complexity in processing high-resolution images, and lengthy optimization processes, thus facilitating stronger applicability of 3D Gaussian Splatting (3D-GS) in real-world scenarios. Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model. With the joint learning mechanism, the proposed framework can inherently estimate robust relative pose information from the image observations and thus primarily alleviate the requirement of real camera poses. Moreover, we implement a deferred back-propagation mechanism that enables high-resolution training and inference, overcoming the resolution constraints of previous methods. To enhance the speed and efficiency, we further introduce a progressive Gaussian cache module that dynamically adjusts during training and inference. As the first pose-free generalizable 3D-GS framework, GGRt achieves inference at $\ge$ 5 FPS and real-time rendering at $\ge$ 100 FPS. Through extensive experimentation, we demonstrate that our method outperforms existing NeRF-based pose-free techniques in terms of inference speed and effectiveness. It can also approach the real pose-based 3D-GS methods. Our contributions provide a significant leap forward for the integration of computer vision and computer graphics into practical applications, offering state-of-the-art results on LLFF, KITTI, and Waymo Open datasets and enabling real-time rendering for immersive experiences.
LTGC: Long-tail Recognition via Leveraging LLMs-driven Generated Content
Mar 13, 2024Long-tail recognition is challenging because it requires the model to learn good representations from tail categories and address imbalances across all categories. In this paper, we propose a novel generative and fine-tuning framework, LTGC, to handle long-tail recognition via leveraging generated content. Firstly, inspired by the rich implicit knowledge in large-scale models (e.g., large language models, LLMs), LTGC leverages the power of these models to parse and reason over the original tail data to produce diverse tail-class content. We then propose several novel designs for LTGC to ensure the quality of the generated data and to efficiently fine-tune the model using both the generated and original data. The visualization demonstrates the effectiveness of the generation module in LTGC, which produces accurate and diverse tail data. Additionally, the experimental results demonstrate that our LTGC outperforms existing state-of-the-art methods on popular long-tailed benchmarks.
GP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Nov 20, 2023



Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular. Most existing methods treat semantic prediction as an additional rendering task, \textit{i.e.}, the "label rendering" task, to build semantic NeRFs. However, by rendering semantic/instance labels per pixel without considering the contextual information of the rendered image, these methods usually suffer from unclear boundary segmentation and abnormal segmentation of pixels within an object. To solve this problem, we propose Generalized Perception NeRF (GP-NeRF), a novel pipeline that makes the widely used segmentation model and NeRF work compatibly under a unified framework, for facilitating context-aware 3D scene perception. To accomplish this goal, we introduce transformers to aggregate radiance as well as semantic embedding fields jointly for novel views and facilitate the joint volumetric rendering of both fields. In addition, we propose two self-distillation mechanisms, i.e., the Semantic Distill Loss and the Depth-Guided Semantic Distill Loss, to enhance the discrimination and quality of the semantic field and the maintenance of geometric consistency. In evaluation, we conduct experimental comparisons under two perception tasks (\textit{i.e.} semantic and instance segmentation) using both synthetic and real-world datasets. Notably, our method outperforms SOTA approaches by 6.94\%, 11.76\%, and 8.47\% on generalized semantic segmentation, finetuning semantic segmentation, and instance segmentation, respectively.
Boosting Low-Data Instance Segmentation by Unsupervised Pre-training with Saliency Prompt
Feb 02, 2023
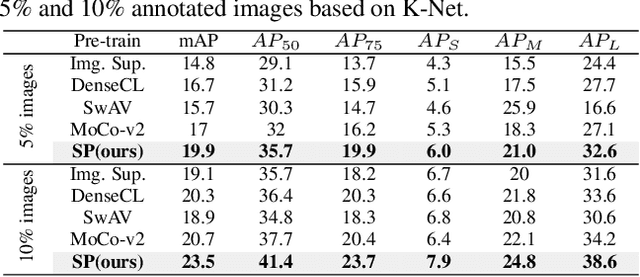
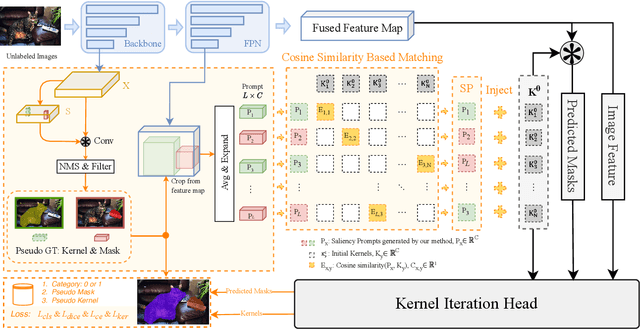

Recently, inspired by DETR variants, query-based end-to-end instance segmentation (QEIS) methods have outperformed CNN-based models on large-scale datasets. Yet they would lose efficacy when only a small amount of training data is available since it's hard for the crucial queries/kernels to learn localization and shape priors. To this end, this work offers a novel unsupervised pre-training solution for low-data regimes. Inspired by the recent success of the Prompting technique, we introduce a new pre-training method that boosts QEIS models by giving Saliency Prompt for queries/kernels. Our method contains three parts: 1) Saliency Masks Proposal is responsible for generating pseudo masks from unlabeled images based on the saliency mechanism. 2) Prompt-Kernel Matching transfers pseudo masks into prompts and injects the corresponding localization and shape priors to the best-matched kernels. 3) Kernel Supervision is applied to supply supervision at the kernel level for robust learning. From a practical perspective, our pre-training method helps QEIS models achieve a similar convergence speed and comparable performance with CNN-based models in low-data regimes. Experimental results show that our method significantly boosts several QEIS models on three datasets. Code will be made available.