 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Data Organization for Enhanced LLM Training
May 28, 2026Large Language Models (LLMs) have revolutionized various fields, yet their training efficiency is heavily reliant on effective data curation. While data selection has been widely studied, the strategic data organization for enhanced training remains an underexplored area, particularly since current LLMs are often trained for only one or a few epochs. This paper systematically explores the influence of data organization on LLM training by reusing pre-computed sample-level scores originally generated for data efficiency, thereby incurring minimal additional computational overhead. We identify and formalize four key guidelines for optimizing data organization: Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, and Local Diversity. Guided by them, we introduce two novel data ordering methods termed STR and SAW. Extensive experiments across different model scales and data sizes, encompassing both pre-training and SFT stages, validate the effectiveness of our summarized guidelines. They also demonstrate the robustness of our proposed data ordering methods in enhancing the stability and performance of LLM training. Github Link: https://github.com/microsoft/data-efficacy/
SpaceDG: Benchmarking Spatial Intelligence under Visual Degradation
May 21, 2026Multimodal Large Language Models (MLLMs) have made rapid progress in spatial intelligence, yet existing spatial reasoning benchmarks largely assume pristine visual inputs and overlook the degradations that commonly occur in real-world deployment, such as motion blur, low light, adverse weather, lens distortion, and compression artifacts. This raises a fundamental question: how robust is the spatial intelligence of current MLLMs when visual observations are imperfect? To answer this question, we introduce SpaceDG, the first large-scale dataset for degradation-aware spatial understanding. It is constructed with a physically grounded degradation synthesis engine that embeds degradation formation process into 3D Gaussian Splatting (3DGS) rendering, enabling realistic simulation of nine degradation types. The resulting dataset contains approximately 1M QA pairs from nearly 1,000 indoor scenes. We further introduce SpaceDG-Bench, an human-verified benchmark with 1,102 questions spanning 11 reasoning categories and 9 visual degradation types, yielding over 10K VQA instances. Evaluating 25 open- and closed-source MLLMs reveals that visual degradations consistently and substantially impair spatial reasoning, exposing a critical robustness gap. Finally, we show that finetuning on SpaceDG markedly improves degradation robustness and can even surpass human performance under degraded conditions without any performance drop on clean images, highlighting the promise of degradation-aware training for robust spatial intelligence.
Nearest-Neighbor Radii under Dependent Sampling
May 14, 2026Nearest-neighbor methods are fundamental to classical and modern machine learning, yet their geometric properties are typically analyzed under independent sampling. In this paper, we study the nearest-neighbor radii under dependent sampling. We consider strong mixing dependent observations and ask whether dependence changes the scale of nearest-neighbor neighborhoods. We establish distribution-free almost sure convergence under polynomial mixing and sharp non-asymptotic moment bounds under geometric mixing. The moment bounds depend on the local intrinsic dimension rather than the ambient dimension, making the results applicable to high-dimensional data concentrated near lower-dimensional manifolds. Synthetic experiments and real-world time-series benchmarks support the theory, showing that nearest-neighbor geometry remains informative under dependence sampling.
Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports
Mar 10, 2026Sports have long attracted broad attention as they push the limits of human physical and cognitive capabilities. Amid growing interest in spatial intelligence for vision-language models (VLMs), sports provide a natural testbed for understanding high-intensity human motion and dynamic object interactions. To this end, we present CourtSI, the first large-scale spatial intelligence dataset tailored to sports scenarios. CourtSI contains over 1M QA pairs, organized under a holistic taxonomy that systematically covers spatial counting, distance measurement, localization, and relational reasoning, across representative net sports including badminton, tennis, and table tennis. Leveraging well-defined court geometry as metric anchors, we develop a semi-automatic data engine to reconstruct sports scenes, enabling scalable curation of CourtSI. In addition, we introduce CourtSI-Bench, a high-quality evaluation benchmark comprising 3,686 QA pairs with rigorous human verification. We evaluate 25 proprietary and open-source VLMs on CourtSI-Bench, revealing a remaining human-AI performance gap and limited generalization from existing spatial intelligence benchmarks. These findings indicate that sports scenarios expose limitations in spatial intelligence capabilities captured by existing benchmarks. Further, fine-tuning Qwen3-VL-8B on CourtSI improves accuracy on CourtSI-Bench by 23.5 percentage points. The adapted model also generalizes effectively to CourtSI-Ext, an evaluation set built on a similar but unseen sport, and demonstrates enhanced spatial-aware commentary generation. Together, these findings demonstrate that CourtSI provides a scalable pathway toward advancing spatial intelligence of VLMs in sports.
Holi-Spatial: Evolving Video Streams into Holistic 3D Spatial Intelligence
Mar 08, 2026The pursuit of spatial intelligence fundamentally relies on access to large-scale, fine-grained 3D data. However, existing approaches predominantly construct spatial understanding benchmarks by generating question-answer (QA) pairs from a limited number of manually annotated datasets, rather than systematically annotating new large-scale 3D scenes from raw web data. As a result, their scalability is severely constrained, and model performance is further hindered by domain gaps inherent in these narrowly curated datasets. In this work, we propose Holi-Spatial, the first fully automated, large-scale, spatially-aware multimodal dataset, constructed from raw video inputs without human intervention, using the proposed data curation pipeline. Holi-Spatial supports multi-level spatial supervision, ranging from geometrically accurate 3D Gaussian Splatting (3DGS) reconstructions with rendered depth maps to object-level and relational semantic annotations, together with corresponding spatial Question-Answer (QA) pairs. Following a principled and systematic pipeline, we further construct Holi-Spatial-4M, the first large-scale, high-quality 3D semantic dataset, containing 12K optimized 3DGS scenes, 1.3M 2D masks, 320K 3D bounding boxes, 320K instance captions, 1.2M 3D grounding instances, and 1.2M spatial QA pairs spanning diverse geometric, relational, and semantic reasoning tasks. Holi-Spatial demonstrates exceptional performance in data curation quality, significantly outperforming existing feed-forward and per-scene optimized methods on datasets such as ScanNet, ScanNet++, and DL3DV. Furthermore, fine-tuning Vision-Language Models (VLMs) on spatial reasoning tasks using this dataset has also led to substantial improvements in model performance.
Visionary: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform
Dec 09, 2025Neural rendering, particularly 3D Gaussian Splatting (3DGS), has evolved rapidly and become a key component for building world models. However, existing viewer solutions remain fragmented, heavy, or constrained by legacy pipelines, resulting in high deployment friction and limited support for dynamic content and generative models. In this work, we present Visionary, an open, web-native platform for real-time various Gaussian Splatting and meshes rendering. Built on an efficient WebGPU renderer with per-frame ONNX inference, Visionary enables dynamic neural processing while maintaining a lightweight, "click-to-run" browser experience. It introduces a standardized Gaussian Generator contract, which not only supports standard 3DGS rendering but also allows plug-and-play algorithms to generate or update Gaussians each frame. Such inference also enables us to apply feedforward generative post-processing. The platform further offers a plug in three.js library with a concise TypeScript API for seamless integration into existing web applications. Experiments show that, under identical 3DGS assets, Visionary achieves superior rendering efficiency compared to current Web viewers due to GPU-based primitive sorting. It already supports multiple variants, including MLP-based 3DGS, 4DGS, neural avatars, and style transformation or enhancement networks. By unifying inference and rendering directly in the browser, Visionary significantly lowers the barrier to reproduction, comparison, and deployment of 3DGS-family methods, serving as a unified World Model Carrier for both reconstructive and generative paradigms.
CityGS-X: A Scalable Architecture for Efficient and Geometrically Accurate Large-Scale Scene Reconstruction
Mar 29, 2025Despite its significant achievements in large-scale scene reconstruction, 3D Gaussian Splatting still faces substantial challenges, including slow processing, high computational costs, and limited geometric accuracy. These core issues arise from its inherently unstructured design and the absence of efficient parallelization. To overcome these challenges simultaneously, we introduce CityGS-X, a scalable architecture built on a novel parallelized hybrid hierarchical 3D representation (PH^2-3D). As an early attempt, CityGS-X abandons the cumbersome merge-and-partition process and instead adopts a newly-designed batch-level multi-task rendering process. This architecture enables efficient multi-GPU rendering through dynamic Level-of-Detail voxel allocations, significantly improving scalability and performance. Through extensive experiments, CityGS-X consistently outperforms existing methods in terms of faster training times, larger rendering capacities, and more accurate geometric details in large-scale scenes. Notably, CityGS-X can train and render a scene with 5,000+ images in just 5 hours using only 4 * 4090 GPUs, a task that would make other alternative methods encounter Out-Of-Memory (OOM) issues and fail completely. This implies that CityGS-X is far beyond the capacity of other existing methods.
CoSurfGS:Collaborative 3D Surface Gaussian Splatting with Distributed Learning for Large Scene Reconstruction
Dec 23, 20243D Gaussian Splatting (3DGS) has demonstrated impressive performance in scene reconstruction. However, most existing GS-based surface reconstruction methods focus on 3D objects or limited scenes. Directly applying these methods to large-scale scene reconstruction will pose challenges such as high memory costs, excessive time consumption, and lack of geometric detail, which makes it difficult to implement in practical applications. To address these issues, we propose a multi-agent collaborative fast 3DGS surface reconstruction framework based on distributed learning for large-scale surface reconstruction. Specifically, we develop local model compression (LMC) and model aggregation schemes (MAS) to achieve high-quality surface representation of large scenes while reducing GPU memory consumption. Extensive experiments on Urban3d, MegaNeRF, and BlendedMVS demonstrate that our proposed method can achieve fast and scalable high-fidelity surface reconstruction and photorealistic rendering. Our project page is available at \url{https://gyy456.github.io/CoSurfGS}.
DGTR: Distributed Gaussian Turbo-Reconstruction for Sparse-View Vast Scenes
Nov 20, 2024
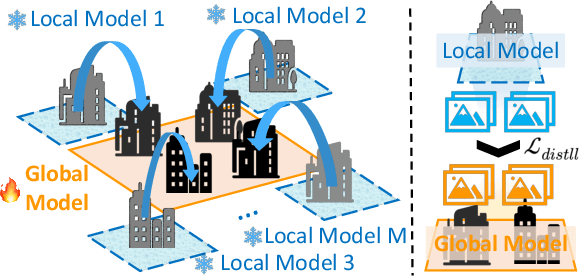


Novel-view synthesis (NVS) approaches play a critical role in vast scene reconstruction. However, these methods rely heavily on dense image inputs and prolonged training times, making them unsuitable where computational resources are limited. Additionally, few-shot methods often struggle with poor reconstruction quality in vast environments. This paper presents DGTR, a novel distributed framework for efficient Gaussian reconstruction for sparse-view vast scenes. Our approach divides the scene into regions, processed independently by drones with sparse image inputs. Using a feed-forward Gaussian model, we predict high-quality Gaussian primitives, followed by a global alignment algorithm to ensure geometric consistency. Synthetic views and depth priors are incorporated to further enhance training, while a distillation-based model aggregation mechanism enables efficient reconstruction. Our method achieves high-quality large-scale scene reconstruction and novel-view synthesis in significantly reduced training times, outperforming existing approaches in both speed and scalability. We demonstrate the effectiveness of our framework on vast aerial scenes, achieving high-quality results within minutes. Code will released on our [https://3d-aigc.github.io/DGTR].
GGRt: Towards Pose-free Generalizable 3D Gaussian Splatting in Real-time
Mar 19, 2024



This paper presents GGRt, a novel approach to generalizable novel view synthesis that alleviates the need for real camera poses, complexity in processing high-resolution images, and lengthy optimization processes, thus facilitating stronger applicability of 3D Gaussian Splatting (3D-GS) in real-world scenarios. Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model. With the joint learning mechanism, the proposed framework can inherently estimate robust relative pose information from the image observations and thus primarily alleviate the requirement of real camera poses. Moreover, we implement a deferred back-propagation mechanism that enables high-resolution training and inference, overcoming the resolution constraints of previous methods. To enhance the speed and efficiency, we further introduce a progressive Gaussian cache module that dynamically adjusts during training and inference. As the first pose-free generalizable 3D-GS framework, GGRt achieves inference at $\ge$ 5 FPS and real-time rendering at $\ge$ 100 FPS. Through extensive experimentation, we demonstrate that our method outperforms existing NeRF-based pose-free techniques in terms of inference speed and effectiveness. It can also approach the real pose-based 3D-GS methods. Our contributions provide a significant leap forward for the integration of computer vision and computer graphics into practical applications, offering state-of-the-art results on LLFF, KITTI, and Waymo Open datasets and enabling real-time rendering for immersive experiences.