 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXR-VIO: High-precision Visual Inertial Odometry with Fast Initialization for XR Applications
Feb 03, 2025This paper presents a novel approach to Visual Inertial Odometry (VIO), focusing on the initialization and feature matching modules. Existing methods for initialization often suffer from either poor stability in visual Structure from Motion (SfM) or fragility in solving a huge number of parameters simultaneously. To address these challenges, we propose a new pipeline for visual inertial initialization that robustly handles various complex scenarios. By tightly coupling gyroscope measurements, we enhance the robustness and accuracy of visual SfM. Our method demonstrates stable performance even with only four image frames, yielding competitive results. In terms of feature matching, we introduce a hybrid method that combines optical flow and descriptor-based matching. By leveraging the robustness of continuous optical flow tracking and the accuracy of descriptor matching, our approach achieves efficient, accurate, and robust tracking results. Through evaluation on multiple benchmarks, our method demonstrates state-of-the-art performance in terms of accuracy and success rate. Additionally, a video demonstration on mobile devices showcases the practical applicability of our approach in the field of Augmented Reality/Virtual Reality (AR/VR).
StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
Jan 10, 2025
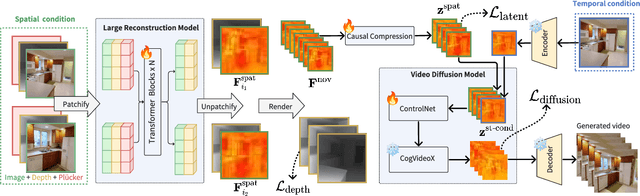


Recent advances in large reconstruction and generative models have significantly improved scene reconstruction and novel view generation. However, due to compute limitations, each inference with these large models is confined to a small area, making long-range consistent scene generation challenging. To address this, we propose StarGen, a novel framework that employs a pre-trained video diffusion model in an autoregressive manner for long-range scene generation. The generation of each video clip is conditioned on the 3D warping of spatially adjacent images and the temporally overlapping image from previously generated clips, improving spatiotemporal consistency in long-range scene generation with precise pose control. The spatiotemporal condition is compatible with various input conditions, facilitating diverse tasks, including sparse view interpolation, perpetual view generation, and layout-conditioned city generation. Quantitative and qualitative evaluations demonstrate StarGen's superior scalability, fidelity, and pose accuracy compared to state-of-the-art methods.
CoSurfGS:Collaborative 3D Surface Gaussian Splatting with Distributed Learning for Large Scene Reconstruction
Dec 23, 20243D Gaussian Splatting (3DGS) has demonstrated impressive performance in scene reconstruction. However, most existing GS-based surface reconstruction methods focus on 3D objects or limited scenes. Directly applying these methods to large-scale scene reconstruction will pose challenges such as high memory costs, excessive time consumption, and lack of geometric detail, which makes it difficult to implement in practical applications. To address these issues, we propose a multi-agent collaborative fast 3DGS surface reconstruction framework based on distributed learning for large-scale surface reconstruction. Specifically, we develop local model compression (LMC) and model aggregation schemes (MAS) to achieve high-quality surface representation of large scenes while reducing GPU memory consumption. Extensive experiments on Urban3d, MegaNeRF, and BlendedMVS demonstrate that our proposed method can achieve fast and scalable high-fidelity surface reconstruction and photorealistic rendering. Our project page is available at \url{https://gyy456.github.io/CoSurfGS}.
GigaGS: Scaling up Planar-Based 3D Gaussians for Large Scene Surface Reconstruction
Sep 10, 20243D Gaussian Splatting (3DGS) has shown promising performance in novel view synthesis. Previous methods adapt it to obtaining surfaces of either individual 3D objects or within limited scenes. In this paper, we make the first attempt to tackle the challenging task of large-scale scene surface reconstruction. This task is particularly difficult due to the high GPU memory consumption, different levels of details for geometric representation, and noticeable inconsistencies in appearance. To this end, we propose GigaGS, the first work for high-quality surface reconstruction for large-scale scenes using 3DGS. GigaGS first applies a partitioning strategy based on the mutual visibility of spatial regions, which effectively grouping cameras for parallel processing. To enhance the quality of the surface, we also propose novel multi-view photometric and geometric consistency constraints based on Level-of-Detail representation. In doing so, our method can reconstruct detailed surface structures. Comprehensive experiments are conducted on various datasets. The consistent improvement demonstrates the superiority of GigaGS.
PGSR: Planar-based Gaussian Splatting for Efficient and High-Fidelity Surface Reconstruction
Jun 10, 2024



Recently, 3D Gaussian Splatting (3DGS) has attracted widespread attention due to its high-quality rendering, and ultra-fast training and rendering speed. However, due to the unstructured and irregular nature of Gaussian point clouds, it is difficult to guarantee geometric reconstruction accuracy and multi-view consistency simply by relying on image reconstruction loss. Although many studies on surface reconstruction based on 3DGS have emerged recently, the quality of their meshes is generally unsatisfactory. To address this problem, we propose a fast planar-based Gaussian splatting reconstruction representation (PGSR) to achieve high-fidelity surface reconstruction while ensuring high-quality rendering. Specifically, we first introduce an unbiased depth rendering method, which directly renders the distance from the camera origin to the Gaussian plane and the corresponding normal map based on the Gaussian distribution of the point cloud, and divides the two to obtain the unbiased depth. We then introduce single-view geometric, multi-view photometric, and geometric regularization to preserve global geometric accuracy. We also propose a camera exposure compensation model to cope with scenes with large illumination variations. Experiments on indoor and outdoor scenes show that our method achieves fast training and rendering while maintaining high-fidelity rendering and geometric reconstruction, outperforming 3DGS-based and NeRF-based methods.
Depth Completion with Multiple Balanced Bases and Confidence for Dense Monocular SLAM
Sep 20, 2023Dense SLAM based on monocular cameras does indeed have immense application value in the field of AR/VR, especially when it is performed on a mobile device. In this paper, we propose a novel method that integrates a light-weight depth completion network into a sparse SLAM system using a multi-basis depth representation, so that dense mapping can be performed online even on a mobile phone. Specifically, we present a specifically optimized multi-basis depth completion network, called BBC-Net, tailored to the characteristics of traditional sparse SLAM systems. BBC-Net can predict multiple balanced bases and a confidence map from a monocular image with sparse points generated by off-the-shelf keypoint-based SLAM systems. The final depth is a linear combination of predicted depth bases that can be optimized by tuning the corresponding weights. To seamlessly incorporate the weights into traditional SLAM optimization and ensure efficiency and robustness, we design a set of depth weight factors, which makes our network a versatile plug-in module, facilitating easy integration into various existing sparse SLAM systems and significantly enhancing global depth consistency through bundle adjustment. To verify the portability of our method, we integrate BBC-Net into two representative SLAM systems. The experimental results on various datasets show that the proposed method achieves better performance in monocular dense mapping than the state-of-the-art methods. We provide an online demo running on a mobile phone, which verifies the efficiency and mapping quality of the proposed method in real-world scenarios.
VIP-SLAM: An Efficient Tightly-Coupled RGB-D Visual Inertial Planar SLAM
Jul 04, 2022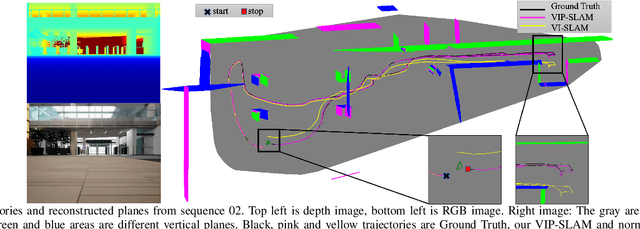
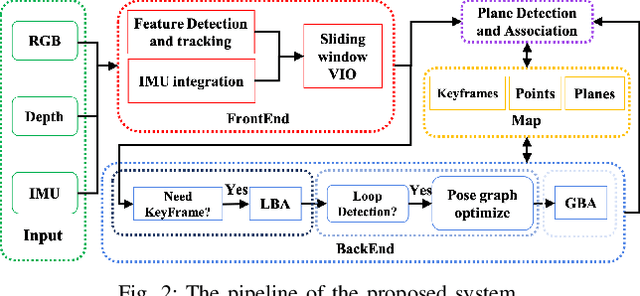
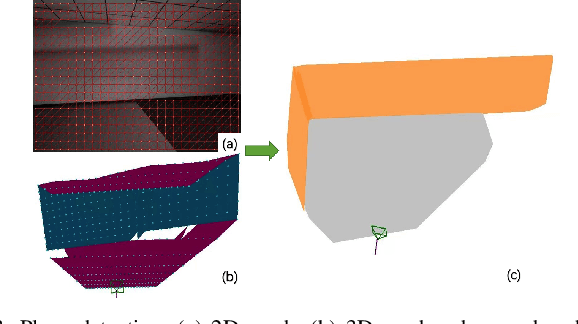
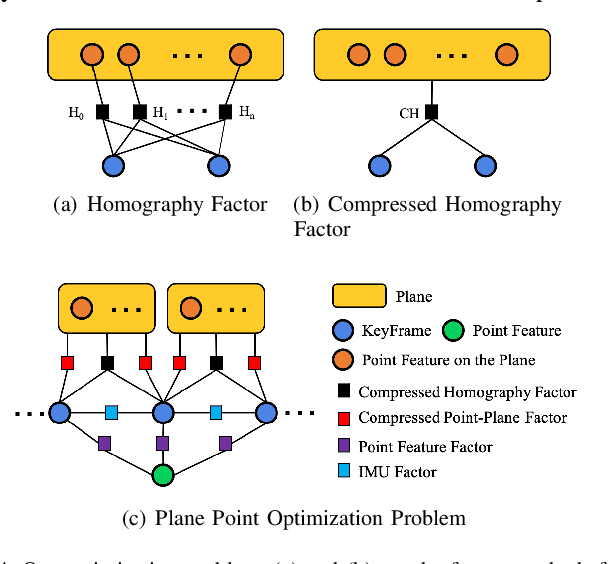
In this paper, we propose a tightly-coupled SLAM system fused with RGB, Depth, IMU and structured plane information. Traditional sparse points based SLAM systems always maintain a mass of map points to model the environment. Huge number of map points bring us a high computational complexity, making it difficult to be deployed on mobile devices. On the other hand, planes are common structures in man-made environment especially in indoor environments. We usually can use a small number of planes to represent a large scene. So the main purpose of this article is to decrease the high complexity of sparse points based SLAM. We build a lightweight back-end map which consists of a few planes and map points to achieve efficient bundle adjustment (BA) with an equal or better accuracy. We use homography constraints to eliminate the parameters of numerous plane points in the optimization and reduce the complexity of BA. We separate the parameters and measurements in homography and point-to-plane constraints and compress the measurements part to further effectively improve the speed of BA. We also integrate the plane information into the whole system to realize robust planar feature extraction, data association, and global consistent planar reconstruction. Finally, we perform an ablation study and compare our method with similar methods in simulation and real environment data. Our system achieves obvious advantages in accuracy and efficiency. Even if the plane parameters are involved in the optimization, we effectively simplify the back-end map by using planar structures. The global bundle adjustment is nearly 2 times faster than the sparse points based SLAM algorithm.