 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
Matrix-3D: Omnidirectional Explorable 3D World Generation
Aug 11, 2025Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
Jan 10, 2025
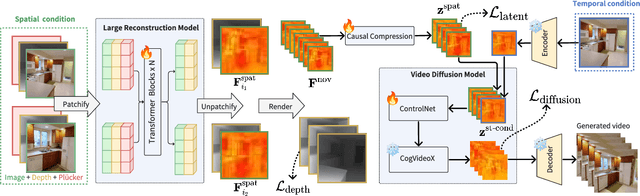


Recent advances in large reconstruction and generative models have significantly improved scene reconstruction and novel view generation. However, due to compute limitations, each inference with these large models is confined to a small area, making long-range consistent scene generation challenging. To address this, we propose StarGen, a novel framework that employs a pre-trained video diffusion model in an autoregressive manner for long-range scene generation. The generation of each video clip is conditioned on the 3D warping of spatially adjacent images and the temporally overlapping image from previously generated clips, improving spatiotemporal consistency in long-range scene generation with precise pose control. The spatiotemporal condition is compatible with various input conditions, facilitating diverse tasks, including sparse view interpolation, perpetual view generation, and layout-conditioned city generation. Quantitative and qualitative evaluations demonstrate StarGen's superior scalability, fidelity, and pose accuracy compared to state-of-the-art methods.