 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Fine-Tuning Needs to Unlock the Potential of Token Priority
Feb 01, 2026The transition from fitting empirical data to achieving true human utility is fundamentally constrained by a granularity mismatch, where fine-grained autoregressive generation is often supervised by coarse or uniform signals. This position paper advocates Token Priority as the essential bridge, formalizing Supervised Fine-Tuning (SFT) not as simple optimization but as a precise distribution reshaping process that aligns raw data with the ideal alignment manifold. We analyze recent breakthroughs through this unified lens, categorizing them into two distinct regimes: Positive Priority for noise filtration and Signed Priority for toxic modes unlearning. We revisit existing progress and limitations, identify key challenges, and suggest directions for future research.
Training-Trajectory-Aware Token Selection
Jan 15, 2026Efficient distillation is a key pathway for converting expensive reasoning capability into deployable efficiency, yet in the frontier regime where the student already has strong reasoning ability, naive continual distillation often yields limited gains or even degradation. We observe a characteristic training phenomenon: even as loss decreases monotonically, all performance metrics can drop sharply at almost the same bottleneck, before gradually recovering. We further uncover a token-level mechanism: confidence bifurcates into steadily increasing Imitation-Anchor Tokens that quickly anchor optimization and other yet-to-learn tokens whose confidence is suppressed until after the bottleneck. And the characteristic that these two types of tokens cannot coexist is the root cause of the failure in continual distillation. To this end, we propose Training-Trajectory-Aware Token Selection (T3S) to reconstruct the training objective at the token level, clearing the optimization path for yet-to-learn tokens. T3 yields consistent gains in both AR and dLLM settings: with only hundreds of examples, Qwen3-8B surpasses DeepSeek-R1 on competitive reasoning benchmarks, Qwen3-32B approaches Qwen3-235B, and T3-trained LLaDA-2.0-Mini exceeds its AR baseline, achieving state-of-the-art performance among all of 16B-scale no-think models.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Training-Free Multi-View Extension of IC-Light for Textual Position-Aware Scene Relighting
Nov 17, 2025We introduce GS-Light, an efficient, textual position-aware pipeline for text-guided relighting of 3D scenes represented via Gaussian Splatting (3DGS). GS-Light implements a training-free extension of a single-input diffusion model to handle multi-view inputs. Given a user prompt that may specify lighting direction, color, intensity, or reference objects, we employ a large vision-language model (LVLM) to parse the prompt into lighting priors. Using off-the-shelf estimators for geometry and semantics (depth, surface normals, and semantic segmentation), we fuse these lighting priors with view-geometry constraints to compute illumination maps and generate initial latent codes for each view. These meticulously derived init latents guide the diffusion model to generate relighting outputs that more accurately reflect user expectations, especially in terms of lighting direction. By feeding multi-view rendered images, along with the init latents, into our multi-view relighting model, we produce high-fidelity, artistically relit images. Finally, we fine-tune the 3DGS scene with the relit appearance to obtain a fully relit 3D scene. We evaluate GS-Light on both indoor and outdoor scenes, comparing it to state-of-the-art baselines including per-view relighting, video relighting, and scene editing methods. Using quantitative metrics (multi-view consistency, imaging quality, aesthetic score, semantic similarity, etc.) and qualitative assessment (user studies), GS-Light demonstrates consistent improvements over baselines. Code and assets will be made available upon publication.
Merge-of-Thought Distillation
Sep 10, 2025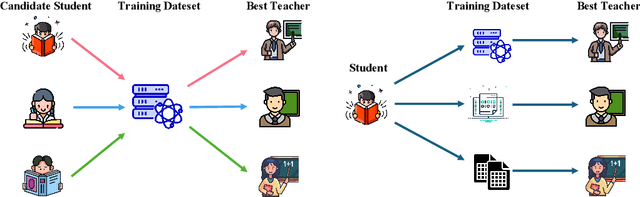
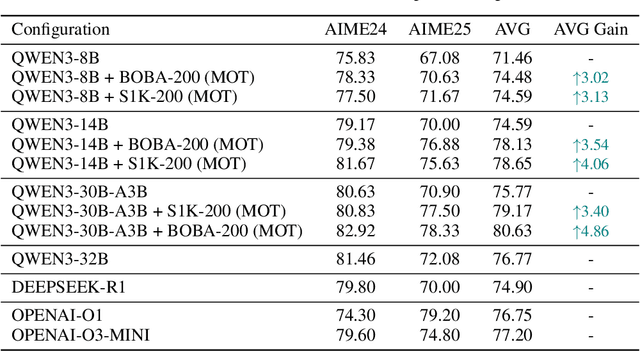
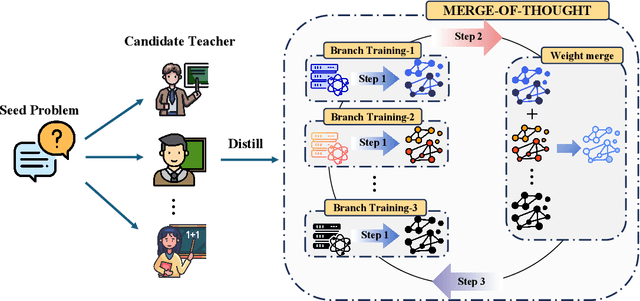

Efficient reasoning distillation for long chain-of-thought (CoT) models is increasingly constrained by the assumption of a single oracle teacher, despite practical availability of multiple candidate teachers and growing CoT corpora. We revisit teacher selection and observe that different students have different "best teachers," and even for the same student the best teacher can vary across datasets. Therefore, to unify multiple teachers' reasoning abilities into student with overcoming conflicts among various teachers' supervision, we propose Merge-of-Thought Distillation (MoT), a lightweight framework that alternates between teacher-specific supervised fine-tuning branches and weight-space merging of the resulting student variants. On competition math benchmarks, using only about 200 high-quality CoT samples, applying MoT to a Qwen3-14B student surpasses strong models including DEEPSEEK-R1, QWEN3-30B-A3B, QWEN3-32B, and OPENAI-O1, demonstrating substantial gains. Besides, MoT consistently outperforms the best single-teacher distillation and the naive multi-teacher union, raises the performance ceiling while mitigating overfitting, and shows robustness to distribution-shifted and peer-level teachers. Moreover, MoT reduces catastrophic forgetting, improves general reasoning beyond mathematics and even cultivates a better teacher, indicating that consensus-filtered reasoning features transfer broadly. These results position MoT as a simple, scalable route to efficiently distilling long CoT capabilities from diverse teachers into compact students.
No Pixel Left Behind: A Detail-Preserving Architecture for Robust High-Resolution AI-Generated Image Detection
Aug 24, 2025The rapid growth of high-resolution, meticulously crafted AI-generated images poses a significant challenge to existing detection methods, which are often trained and evaluated on low-resolution, automatically generated datasets that do not align with the complexities of high-resolution scenarios. A common practice is to resize or center-crop high-resolution images to fit standard network inputs. However, without full coverage of all pixels, such strategies risk either obscuring subtle, high-frequency artifacts or discarding information from uncovered regions, leading to input information loss. In this paper, we introduce the High-Resolution Detail-Aggregation Network (HiDA-Net), a novel framework that ensures no pixel is left behind. We use the Feature Aggregation Module (FAM), which fuses features from multiple full-resolution local tiles with a down-sampled global view of the image. These local features are aggregated and fused with global representations for final prediction, ensuring that native-resolution details are preserved and utilized for detection. To enhance robustness against challenges such as localized AI manipulations and compression, we introduce Token-wise Forgery Localization (TFL) module for fine-grained spatial sensitivity and JPEG Quality Factor Estimation (QFE) module to disentangle generative artifacts from compression noise explicitly. Furthermore, to facilitate future research, we introduce HiRes-50K, a new challenging benchmark consisting of 50,568 images with up to 64 megapixels. Extensive experiments show that HiDA-Net achieves state-of-the-art, increasing accuracy by over 13% on the challenging Chameleon dataset and 10% on our HiRes-50K.
Neural Operator based Reinforcement Learning for Control of first-order PDEs with Spatially-Varying State Delay
Jan 30, 2025



Control of distributed parameter systems affected by delays is a challenging task, particularly when the delays depend on spatial variables. The idea of integrating analytical control theory with learning-based control within a unified control scheme is becoming increasingly promising and advantageous. In this paper, we address the problem of controlling an unstable first-order hyperbolic PDE with spatially-varying delays by combining PDE backstepping control strategies and deep reinforcement learning (RL). To eliminate the assumption on the delay function required for the backstepping design, we propose a soft actor-critic (SAC) architecture incorporating a DeepONet to approximate the backstepping controller. The DeepONet extracts features from the backstepping controller and feeds them into the policy network. In simulations, our algorithm outperforms the baseline SAC without prior backstepping knowledge and the analytical controller.
StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
Jan 10, 2025
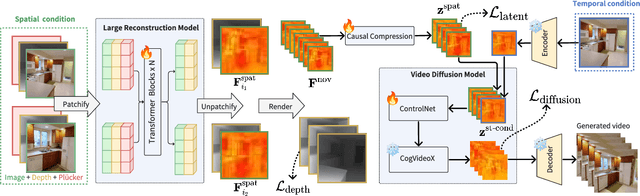


Recent advances in large reconstruction and generative models have significantly improved scene reconstruction and novel view generation. However, due to compute limitations, each inference with these large models is confined to a small area, making long-range consistent scene generation challenging. To address this, we propose StarGen, a novel framework that employs a pre-trained video diffusion model in an autoregressive manner for long-range scene generation. The generation of each video clip is conditioned on the 3D warping of spatially adjacent images and the temporally overlapping image from previously generated clips, improving spatiotemporal consistency in long-range scene generation with precise pose control. The spatiotemporal condition is compatible with various input conditions, facilitating diverse tasks, including sparse view interpolation, perpetual view generation, and layout-conditioned city generation. Quantitative and qualitative evaluations demonstrate StarGen's superior scalability, fidelity, and pose accuracy compared to state-of-the-art methods.
FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance
Jul 08, 2024



CLIP has achieved impressive zero-shot performance after pre-training on a large-scale dataset consisting of paired image-text data. Previous works have utilized CLIP by incorporating manually designed visual prompts like colored circles and blur masks into the images to guide the model's attention, showing enhanced zero-shot performance in downstream tasks. Although these methods have achieved promising results, they inevitably alter the original information of the images, which can lead to failure in specific tasks. We propose a train-free method Foveal-Attention CLIP (FALIP), which adjusts the CLIP's attention by inserting foveal attention masks into the multi-head self-attention module. We demonstrate FALIP effectively boosts CLIP zero-shot performance in tasks such as referring expressions comprehension, image classification, and 3D point cloud recognition. Experimental results further show that FALIP outperforms existing methods on most metrics and can augment current methods to enhance their performance.
Data Contamination Calibration for Black-box LLMs
May 20, 2024


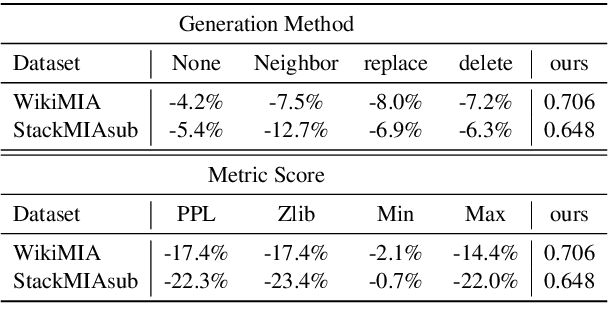
The rapid advancements of Large Language Models (LLMs) tightly associate with the expansion of the training data size. However, the unchecked ultra-large-scale training sets introduce a series of potential risks like data contamination, i.e. the benchmark data is used for training. In this work, we propose a holistic method named Polarized Augment Calibration (PAC) along with a new to-be-released dataset to detect the contaminated data and diminish the contamination effect. PAC extends the popular MIA (Membership Inference Attack) -- from machine learning community -- by forming a more global target at detecting training data to Clarify invisible training data. As a pioneering work, PAC is very much plug-and-play that can be integrated with most (if not all) current white- and black-box LLMs. By extensive experiments, PAC outperforms existing methods by at least 4.5%, towards data contamination detection on more 4 dataset formats, with more than 10 base LLMs. Besides, our application in real-world scenarios highlights the prominent presence of contamination and related issues.