 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Contamination Calibration for Black-box LLMs
Paper and Code



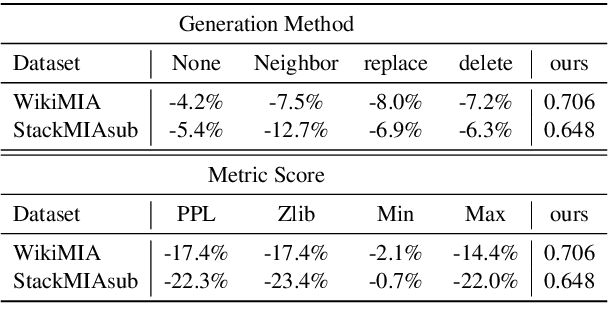
The rapid advancements of Large Language Models (LLMs) tightly associate with the expansion of the training data size. However, the unchecked ultra-large-scale training sets introduce a series of potential risks like data contamination, i.e. the benchmark data is used for training. In this work, we propose a holistic method named Polarized Augment Calibration (PAC) along with a new to-be-released dataset to detect the contaminated data and diminish the contamination effect. PAC extends the popular MIA (Membership Inference Attack) -- from machine learning community -- by forming a more global target at detecting training data to Clarify invisible training data. As a pioneering work, PAC is very much plug-and-play that can be integrated with most (if not all) current white- and black-box LLMs. By extensive experiments, PAC outperforms existing methods by at least 4.5%, towards data contamination detection on more 4 dataset formats, with more than 10 base LLMs. Besides, our application in real-world scenarios highlights the prominent presence of contamination and related issues.