 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
Jun 02, 2026Wide-baseline matching (WBM) requires integrating geometric understanding, viewpoint changes, fine-grained perception, and occlusion reasoning, making it a challenging testbed for spatial reasoning in multimodal large language models (MLLMs) deployed in physical environments. However, current MLLMs lack systematic evaluation and training frameworks for these capabilities. We introduce ReasonMatch-Bench, a benchmark stratified by viewpoint displacement and matching granularity across indoor, outdoor, and object-centric scenarios, and show that current MLLMs still struggle with fine-grained wide-baseline correspondence: on a difficult 90-sample subset, human annotators achieve 84.0 F1, while the best existing baseline reaches 37.2. To bridge this gap, we build a scalable data-generation pipeline that automatically extracts wide-baseline view pairs from large-scale video-3D corpora, including RGB-D videos and SfM reconstructions, yielding diverse and verifiable supervision. We further propose Dynamic Correspondence Reinforcement Learning (DCRL), which combines Image-Level Viewpoint Progression and Point-Level Correspondence Curriculum to improve WBM training through verifiable rewards without explicit CoT supervision. Extensive experiments show that DCRL substantially improves ReasonMatch-Bench and transfers to related spatial benchmarks, while maintaining general visual understanding performance with modest gains on several benchmarks.
FLaG: Fine-Grained Latent Grouping for Hallucination Detection
May 29, 2026Hallucinations in large language models (LLMs) arise from heterogeneous failure mechanisms, making reliable detection difficult for any single global uncertainty score. In this work, we formulate hallucination detection as a mechanism-aware evidence aggregation problem, where diverse representation- and token-level signals must be interpreted under multiple latent explanations. We propose FLaG, a lightweight hallucination detection framework that models correctness through a set of latent evidence groups. Each instance is softly associated with multiple groups via an energy-based routing mechanism, and group-conditional reliability signals are combined through a principled log-marginal aggregation. This design enables FLaG to capture heterogeneous hallucination patterns while remaining invariant to decision thresholds and evaluation metrics. The framework operates as a frozen-model head, requires no modification to the underlying language model, and incurs minimal computational overhead. We further provide a theoretical perspective that connects FLaG to optimal evidence aggregation under heterogeneous error mechanisms, showing that the Bayes-optimal test statistic necessarily admits a log-marginal form and that FLaG constitutes a tractable approximation with a controllable error bound. Extensive experiments across multiple benchmarks and LLM backbones demonstrate that FLaG consistently achieves SOTA performance, while exhibiting robust transfer across datasets and models, and remaining effective under limited supervision.
From Parameters to Data: A Task-Parameter-Guided Fine-Tuning Pipeline for Efficient LLM Alignment
May 20, 2026Adapting Large Language Models (LLMs) to specialized domains typically incurs high data and computational overhead. While prior efficiency efforts have largely treated data selection and parameter-efficient fine-tuning as isolated processes, our empirical analysis suggests they may be intrinsically coupled. We posit the Strong Map Hypothesis: a sparse subset of attention heads plays a dominant role in task-specific adaptation, acting as keys that unlock specific data patterns. Building on this observation, we propose From Parameters to Data (P2D), a unified framework that leverages these task-sensitive attention heads as a dual compass for both sample mining and structural pruning. To rigorously quantify the total pipeline cost, we introduce the Alignment Efficiency Ratio (AER) metric for both selection latency and training time. Mechanistically, P2D identifies critical heads via a lightweight proxy and uses them as a functional filter to curate high-affinity data, establishing a synergistic pipeline. Empirically, by updating merely 10% of attention heads on 10% of the data, P2D achieves an 8.3 pp performance gain over strong baselines and delivers a 7.0x end-to-end time speedup. These results validate that precise parameter-data synchronization eliminates redundancy, offering a new paradigm for efficient alignment.
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Supervised Fine-Tuning Needs to Unlock the Potential of Token Priority
Feb 01, 2026The transition from fitting empirical data to achieving true human utility is fundamentally constrained by a granularity mismatch, where fine-grained autoregressive generation is often supervised by coarse or uniform signals. This position paper advocates Token Priority as the essential bridge, formalizing Supervised Fine-Tuning (SFT) not as simple optimization but as a precise distribution reshaping process that aligns raw data with the ideal alignment manifold. We analyze recent breakthroughs through this unified lens, categorizing them into two distinct regimes: Positive Priority for noise filtration and Signed Priority for toxic modes unlearning. We revisit existing progress and limitations, identify key challenges, and suggest directions for future research.
Training-Trajectory-Aware Token Selection
Jan 15, 2026Efficient distillation is a key pathway for converting expensive reasoning capability into deployable efficiency, yet in the frontier regime where the student already has strong reasoning ability, naive continual distillation often yields limited gains or even degradation. We observe a characteristic training phenomenon: even as loss decreases monotonically, all performance metrics can drop sharply at almost the same bottleneck, before gradually recovering. We further uncover a token-level mechanism: confidence bifurcates into steadily increasing Imitation-Anchor Tokens that quickly anchor optimization and other yet-to-learn tokens whose confidence is suppressed until after the bottleneck. And the characteristic that these two types of tokens cannot coexist is the root cause of the failure in continual distillation. To this end, we propose Training-Trajectory-Aware Token Selection (T3S) to reconstruct the training objective at the token level, clearing the optimization path for yet-to-learn tokens. T3 yields consistent gains in both AR and dLLM settings: with only hundreds of examples, Qwen3-8B surpasses DeepSeek-R1 on competitive reasoning benchmarks, Qwen3-32B approaches Qwen3-235B, and T3-trained LLaDA-2.0-Mini exceeds its AR baseline, achieving state-of-the-art performance among all of 16B-scale no-think models.
TableGPT-R1: Advancing Tabular Reasoning Through Reinforcement Learning
Dec 23, 2025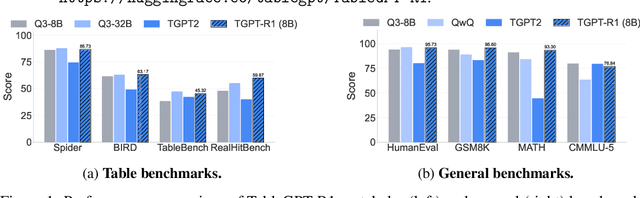
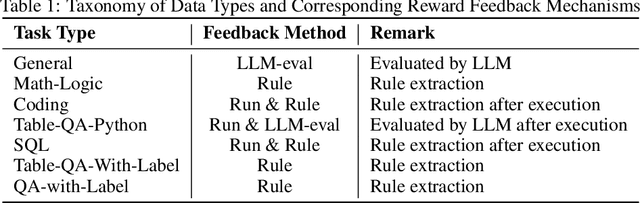
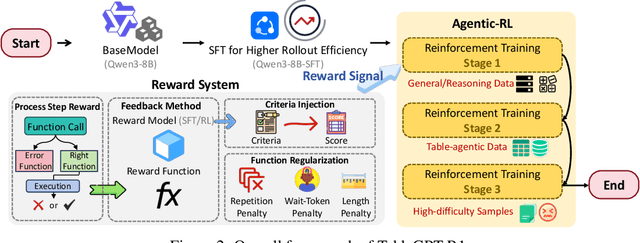
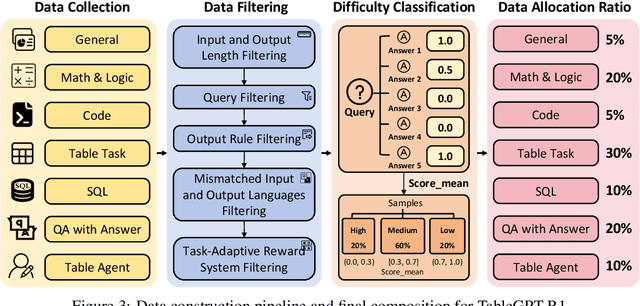
Tabular data serves as the backbone of modern data analysis and scientific research. While Large Language Models (LLMs) fine-tuned via Supervised Fine-Tuning (SFT) have significantly improved natural language interaction with such structured data, they often fall short in handling the complex, multi-step reasoning and robust code execution required for real-world table tasks. Reinforcement Learning (RL) offers a promising avenue to enhance these capabilities, yet its application in the tabular domain faces three critical hurdles: the scarcity of high-quality agentic trajectories with closed-loop code execution and environment feedback on diverse table structures, the extreme heterogeneity of feedback signals ranging from rigid SQL execution to open-ended data interpretation, and the risk of catastrophic forgetting of general knowledge during vertical specialization. To overcome these challenges and unlock advanced reasoning on complex tables, we introduce \textbf{TableGPT-R1}, a specialized tabular model built on a systematic RL framework. Our approach integrates a comprehensive data engineering pipeline that synthesizes difficulty-stratified agentic trajectories for both supervised alignment and RL rollouts, a task-adaptive reward system that combines rule-based verification with a criteria-injected reward model and incorporates process-level step reward shaping with behavioral regularization, and a multi-stage training framework that progressively stabilizes reasoning before specializing in table-specific tasks. Extensive evaluations demonstrate that TableGPT-R1 achieves state-of-the-art performance on authoritative benchmarks, significantly outperforming baseline models while retaining robust general capabilities. Our model is available at https://huggingface.co/tablegpt/TableGPT-R1.
SPA++: Generalized Graph Spectral Alignment for Versatile Domain Adaptation
Aug 07, 2025Domain Adaptation (DA) aims to transfer knowledge from a labeled source domain to an unlabeled or sparsely labeled target domain under domain shifts. Most prior works focus on capturing the inter-domain transferability but largely overlook rich intra-domain structures, which empirically results in even worse discriminability. To tackle this tradeoff, we propose a generalized graph SPectral Alignment framework, SPA++. Its core is briefly condensed as follows: (1)-by casting the DA problem to graph primitives, it composes a coarse graph alignment mechanism with a novel spectral regularizer toward aligning the domain graphs in eigenspaces; (2)-we further develop a fine-grained neighbor-aware propagation mechanism for enhanced discriminability in the target domain; (3)-by incorporating data augmentation and consistency regularization, SPA++ can adapt to complex scenarios including most DA settings and even challenging distribution scenarios. Furthermore, we also provide theoretical analysis to support our method, including the generalization bound of graph-based DA and the role of spectral alignment and smoothing consistency. Extensive experiments on benchmark datasets demonstrate that SPA++ consistently outperforms existing cutting-edge methods, achieving superior robustness and adaptability across various challenging adaptation scenarios.
RealHiTBench: A Comprehensive Realistic Hierarchical Table Benchmark for Evaluating LLM-Based Table Analysis
Jun 16, 2025With the rapid advancement of Large Language Models (LLMs), there is an increasing need for challenging benchmarks to evaluate their capabilities in handling complex tabular data. However, existing benchmarks are either based on outdated data setups or focus solely on simple, flat table structures. In this paper, we introduce RealHiTBench, a comprehensive benchmark designed to evaluate the performance of both LLMs and Multimodal LLMs (MLLMs) across a variety of input formats for complex tabular data, including LaTeX, HTML, and PNG. RealHiTBench also includes a diverse collection of tables with intricate structures, spanning a wide range of task types. Our experimental results, using 25 state-of-the-art LLMs, demonstrate that RealHiTBench is indeed a challenging benchmark. Moreover, we also develop TreeThinker, a tree-based pipeline that organizes hierarchical headers into a tree structure for enhanced tabular reasoning, validating the importance of improving LLMs' perception of table hierarchies. We hope that our work will inspire further research on tabular data reasoning and the development of more robust models. The code and data are available at https://github.com/cspzyy/RealHiTBench.
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Nov 04, 2024The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact.