 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSGaussian: Semantic-Aware and Structure-Preserving 3D Style Transfer
Sep 04, 2025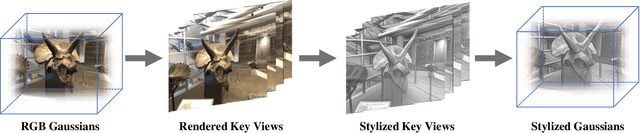
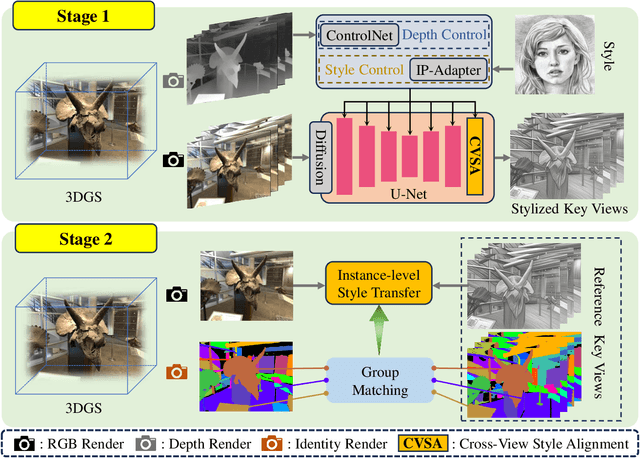


Recent advancements in neural representations, such as Neural Radiance Fields and 3D Gaussian Splatting, have increased interest in applying style transfer to 3D scenes. While existing methods can transfer style patterns onto 3D-consistent neural representations, they struggle to effectively extract and transfer high-level style semantics from the reference style image. Additionally, the stylized results often lack structural clarity and separation, making it difficult to distinguish between different instances or objects within the 3D scene. To address these limitations, we propose a novel 3D style transfer pipeline that effectively integrates prior knowledge from pretrained 2D diffusion models. Our pipeline consists of two key stages: First, we leverage diffusion priors to generate stylized renderings of key viewpoints. Then, we transfer the stylized key views onto the 3D representation. This process incorporates two innovative designs. The first is cross-view style alignment, which inserts cross-view attention into the last upsampling block of the UNet, allowing feature interactions across multiple key views. This ensures that the diffusion model generates stylized key views that maintain both style fidelity and instance-level consistency. The second is instance-level style transfer, which effectively leverages instance-level consistency across stylized key views and transfers it onto the 3D representation. This results in a more structured, visually coherent, and artistically enriched stylization. Extensive qualitative and quantitative experiments demonstrate that our 3D style transfer pipeline significantly outperforms state-of-the-art methods across a wide range of scenes, from forward-facing to challenging 360-degree environments. Visit our project page https://jm-xu.github.io/SSGaussian for immersive visualization.
HalluciDoctor: Mitigating Hallucinatory Toxicity in Visual Instruction Data
Nov 22, 2023



Multi-modal Large Language Models (MLLMs) tuned on machine-generated instruction-following data have demonstrated remarkable performance in various multi-modal understanding and generation tasks. However, the hallucinations inherent in machine-generated data, which could lead to hallucinatory outputs in MLLMs, remain under-explored. This work aims to investigate various hallucinations (i.e., object, relation, attribute hallucinations) and mitigate those hallucinatory toxicities in large-scale machine-generated visual instruction datasets. Drawing on the human ability to identify factual errors, we present a novel hallucination detection and elimination framework, HalluciDoctor, based on the cross-checking paradigm. We use our framework to identify and eliminate hallucinations in the training data automatically. Interestingly, HalluciDoctor also indicates that spurious correlations arising from long-tail object co-occurrences contribute to hallucinations. Based on that, we execute counterfactual visual instruction expansion to balance data distribution, thereby enhancing MLLMs' resistance to hallucinations. Comprehensive experiments on hallucination evaluation benchmarks show that our method successfully mitigates 44.6% hallucinations relatively and maintains competitive performance compared to LLaVA.The source code will be released at \url{https://github.com/Yuqifan1117/HalluciDoctor}.
Dancing Avatar: Pose and Text-Guided Human Motion Videos Synthesis with Image Diffusion Model
Aug 15, 2023



The rising demand for creating lifelike avatars in the digital realm has led to an increased need for generating high-quality human videos guided by textual descriptions and poses. We propose Dancing Avatar, designed to fabricate human motion videos driven by poses and textual cues. Our approach employs a pretrained T2I diffusion model to generate each video frame in an autoregressive fashion. The crux of innovation lies in our adept utilization of the T2I diffusion model for producing video frames successively while preserving contextual relevance. We surmount the hurdles posed by maintaining human character and clothing consistency across varying poses, along with upholding the background's continuity amidst diverse human movements. To ensure consistent human appearances across the entire video, we devise an intra-frame alignment module. This module assimilates text-guided synthesized human character knowledge into the pretrained T2I diffusion model, synergizing insights from ChatGPT. For preserving background continuity, we put forth a background alignment pipeline, amalgamating insights from segment anything and image inpainting techniques. Furthermore, we propose an inter-frame alignment module that draws inspiration from an auto-regressive pipeline to augment temporal consistency between adjacent frames, where the preceding frame guides the synthesis process of the current frame. Comparisons with state-of-the-art methods demonstrate that Dancing Avatar exhibits the capacity to generate human videos with markedly superior quality, both in terms of human and background fidelity, as well as temporal coherence compared to existing state-of-the-art approaches.
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
May 21, 2023We present an end-to-end diffusion-based method for editing videos with human language instructions, namely $\textbf{InstructVid2Vid}$. Our approach enables the editing of input videos based on natural language instructions without any per-example fine-tuning or inversion. The proposed InstructVid2Vid model combines a pretrained image generation model, Stable Diffusion, with a conditional 3D U-Net architecture to generate time-dependent sequence of video frames. To obtain the training data, we incorporate the knowledge and expertise of different models, including ChatGPT, BLIP, and Tune-a-Video, to synthesize video-instruction triplets, which is a more cost-efficient alternative to collecting data in real-world scenarios. To improve the consistency between adjacent frames of generated videos, we propose the Frame Difference Loss, which is incorporated during the training process. During inference, we extend the classifier-free guidance to text-video input to guide the generated results, making them more related to both the input video and instruction. Experiments demonstrate that InstructVid2Vid is able to generate high-quality, temporally coherent videos and perform diverse edits, including attribute editing, change of background, and style transfer. These results highlight the versatility and effectiveness of our proposed method. Code is released in $\href{https://github.com/BrightQin/InstructVid2Vid}{InstructVid2Vid}$.
DBA: Efficient Transformer with Dynamic Bilinear Low-Rank Attention
Nov 24, 2022



Many studies have been conducted to improve the efficiency of Transformer from quadric to linear. Among them, the low-rank-based methods aim to learn the projection matrices to compress the sequence length. However, the projection matrices are fixed once they have been learned, which compress sequence length with dedicated coefficients for tokens in the same position. Adopting such input-invariant projections ignores the fact that the most informative part of a sequence varies from sequence to sequence, thus failing to preserve the most useful information that lies in varied positions. In addition, previous efficient Transformers only focus on the influence of sequence length while neglecting the effect of hidden state dimension. To address the aforementioned problems, we present an efficient yet effective attention mechanism, namely the Dynamic Bilinear Low-Rank Attention (DBA), which compresses the sequence length by input-sensitive dynamic projection matrices and achieves linear time and space complexity by jointly optimizing the sequence length and hidden state dimension while maintaining state-of-the-art performance. Specifically, we first theoretically demonstrate that the sequence length can be compressed non-destructively from a novel perspective of information theory, with compression matrices dynamically determined by the input sequence. Furthermore, we show that the hidden state dimension can be approximated by extending the Johnson-Lindenstrauss lemma, optimizing the attention in bilinear form. Theoretical analysis shows that DBA is proficient in capturing high-order relations in cross-attention problems. Experiments over tasks with diverse sequence length conditions show that DBA achieves state-of-the-art performance compared with various strong baselines while maintaining less memory consumption with higher speed.