 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-Aware Multi-Behavior Dynamic Graph Transformer for Sequential Recommendation
Feb 11, 2026In the landscape of contemporary recommender systems, user-item interactions are inherently dynamic and sequential, often characterized by various behaviors. Prior research has explored the modeling of user preferences through sequential interactions and the user-item interaction graph, utilizing advanced techniques such as graph neural networks and transformer-based architectures. However, these methods typically fall short in simultaneously accounting for the dynamic nature of graph topologies and the sequential pattern of interactions in user preference models. Moreover, they often fail to adequately capture the multiple user behavior boundaries during model optimization. To tackle these challenges, we introduce a boundary-aware Multi-Behavioral Dynamic Graph Transformer (MB-DGT) model that dynamically refines the graph structure to reflect the evolving patterns of user behaviors and interactions. Our model involves a transformer-based dynamic graph aggregator for user preference modeling, which assimilates the changing graph structure and the sequence of user behaviors. This integration yields a more comprehensive and dynamic representation of user preferences. For model optimization, we implement a user-specific multi-behavior loss function that delineates the interest boundaries among different behaviors, thereby enriching the personalized learning of user preferences. Comprehensive experiments across three datasets indicate that our model consistently delivers remarkable recommendation performance.
FMaMIL: Frequency-Driven Mamba Multi-Instance Learning for Weakly Supervised Lesion Segmentation in Medical Images
Jun 09, 2025Accurate lesion segmentation in histopathology images is essential for diagnostic interpretation and quantitative analysis, yet it remains challenging due to the limited availability of costly pixel-level annotations. To address this, we propose FMaMIL, a novel two-stage framework for weakly supervised lesion segmentation based solely on image-level labels. In the first stage, a lightweight Mamba-based encoder is introduced to capture long-range dependencies across image patches under the MIL paradigm. To enhance spatial sensitivity and structural awareness, we design a learnable frequency-domain encoding module that supplements spatial-domain features with spectrum-based information. CAMs generated in this stage are used to guide segmentation training. In the second stage, we refine the initial pseudo labels via a CAM-guided soft-label supervision and a self-correction mechanism, enabling robust training even under label noise. Extensive experiments on both public and private histopathology datasets demonstrate that FMaMIL outperforms state-of-the-art weakly supervised methods without relying on pixel-level annotations, validating its effectiveness and potential for digital pathology applications.
SMART: Self-Generating and Self-Validating Multi-Dimensional Assessment for LLMs' Mathematical Problem Solving
May 22, 2025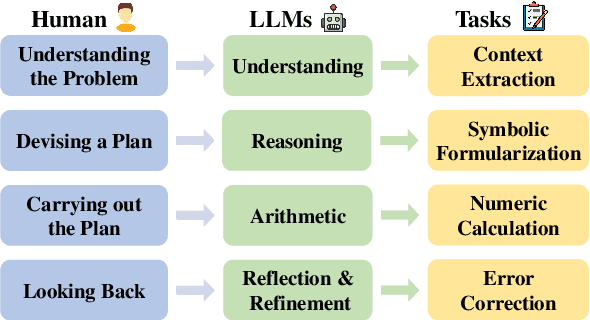
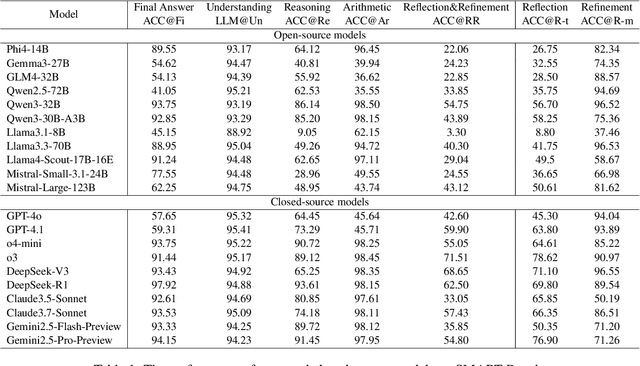

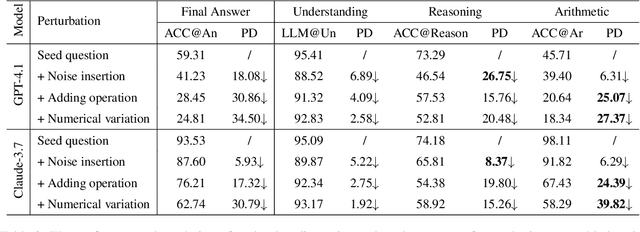
Large Language Models have achieved remarkable results on a variety of mathematical benchmarks. However, concerns remain as to whether these successes reflect genuine mathematical reasoning or superficial pattern recognition. Common evaluation metrics, such as final answer accuracy, fail to disentangle the underlying competencies involved, offering limited diagnostic value. To address these limitations, we introduce SMART: a Self-Generating and Self-Validating Multi-Dimensional Assessment Framework. SMART decomposes mathematical problem solving into four distinct dimensions: understanding, reasoning, arithmetic, and reflection \& refinement. Each dimension is evaluated independently through tailored tasks, enabling interpretable and fine-grained analysis of LLM behavior. Crucially, SMART integrates an automated self-generating and self-validating mechanism to produce and verify benchmark data, ensuring both scalability and reliability. We apply SMART to 21 state-of-the-art open- and closed-source LLMs, uncovering significant discrepancies in their abilities across different dimensions. Our findings demonstrate the inadequacy of final answer accuracy as a sole metric and motivate a new holistic metric to better capture true problem-solving capabilities. Code and benchmarks will be released upon acceptance.
Problem-Solving Logic Guided Curriculum In-Context Learning for LLMs Complex Reasoning
Feb 21, 2025In-context learning (ICL) can significantly enhance the complex reasoning capabilities of large language models (LLMs), with the key lying in the selection and ordering of demonstration examples. Previous methods typically relied on simple features to measure the relevance between examples. We argue that these features are not sufficient to reflect the intrinsic connections between examples. In this study, we propose a curriculum ICL strategy guided by problem-solving logic. We select demonstration examples by analyzing the problem-solving logic and order them based on curriculum learning. Specifically, we constructed a problem-solving logic instruction set based on the BREAK dataset and fine-tuned a language model to analyze the problem-solving logic of examples. Subsequently, we selected appropriate demonstration examples based on problem-solving logic and assessed their difficulty according to the number of problem-solving steps. In accordance with the principles of curriculum learning, we ordered the examples from easy to hard to serve as contextual prompts. Experimental results on multiple benchmarks indicate that our method outperforms previous ICL approaches in terms of performance and efficiency, effectively enhancing the complex reasoning capabilities of LLMs. Our project will be publicly available subsequently.
Assessing Hidden Risks of LLMs: An Empirical Study on Robustness, Consistency, and Credibility
May 25, 2023The recent popularity of large language models (LLMs) has brought a significant impact to boundless fields, particularly through their open-ended ecosystem such as the APIs, open-sourced models, and plugins. However, with their widespread deployment, there is a general lack of research that thoroughly discusses and analyzes the potential risks concealed. In that case, we intend to conduct a preliminary but pioneering study covering the robustness, consistency, and credibility of LLMs systems. With most of the related literature in the era of LLM uncharted, we propose an automated workflow that copes with an upscaled number of queries/responses. Overall, we conduct over a million queries to the mainstream LLMs including ChatGPT, LLaMA, and OPT. Core to our workflow consists of a data primitive, followed by an automated interpreter that evaluates these LLMs under different adversarial metrical systems. As a result, we draw several, and perhaps unfortunate, conclusions that are quite uncommon from this trendy community. Briefly, they are: (i)-the minor but inevitable error occurrence in the user-generated query input may, by chance, cause the LLM to respond unexpectedly; (ii)-LLMs possess poor consistency when processing semantically similar query input. In addition, as a side finding, we find that ChatGPT is still capable to yield the correct answer even when the input is polluted at an extreme level. While this phenomenon demonstrates the powerful memorization of the LLMs, it raises serious concerns about using such data for LLM-involved evaluation in academic development. To deal with it, we propose a novel index associated with a dataset that roughly decides the feasibility of using such data for LLM-involved evaluation. Extensive empirical studies are tagged to support the aforementioned claims.
Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning
May 16, 2023Instruction tuning for large language models (LLMs) has gained attention from researchers due to its ability to unlock the potential of LLMs in following instructions. While instruction tuning offers advantages for facilitating the adaptation of large language models (LLMs) to downstream tasks as a fine-tuning approach, training models with tens of millions or even billions of parameters on large amounts of data results in unaffordable computational costs. To address this, we focus on reducing the data used in LLM instruction tuning to decrease training costs and improve data efficiency, dubbed as Low Training Data Instruction Tuning (LTD Instruction Tuning). Specifically, this paper conducts a preliminary exploration into reducing the data used in LLM training and identifies several observations regarding task specialization for LLM training, such as the optimization of performance for a specific task, the number of instruction types required for instruction tuning, and the amount of data required for task-specific models. The results suggest that task-specific models can be trained using less than 0.5% of the original dataset, with a 2% improvement in performance over those trained on full task-related data.