 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Hidden Risks of LLMs: An Empirical Study on Robustness, Consistency, and Credibility
May 25, 2023The recent popularity of large language models (LLMs) has brought a significant impact to boundless fields, particularly through their open-ended ecosystem such as the APIs, open-sourced models, and plugins. However, with their widespread deployment, there is a general lack of research that thoroughly discusses and analyzes the potential risks concealed. In that case, we intend to conduct a preliminary but pioneering study covering the robustness, consistency, and credibility of LLMs systems. With most of the related literature in the era of LLM uncharted, we propose an automated workflow that copes with an upscaled number of queries/responses. Overall, we conduct over a million queries to the mainstream LLMs including ChatGPT, LLaMA, and OPT. Core to our workflow consists of a data primitive, followed by an automated interpreter that evaluates these LLMs under different adversarial metrical systems. As a result, we draw several, and perhaps unfortunate, conclusions that are quite uncommon from this trendy community. Briefly, they are: (i)-the minor but inevitable error occurrence in the user-generated query input may, by chance, cause the LLM to respond unexpectedly; (ii)-LLMs possess poor consistency when processing semantically similar query input. In addition, as a side finding, we find that ChatGPT is still capable to yield the correct answer even when the input is polluted at an extreme level. While this phenomenon demonstrates the powerful memorization of the LLMs, it raises serious concerns about using such data for LLM-involved evaluation in academic development. To deal with it, we propose a novel index associated with a dataset that roughly decides the feasibility of using such data for LLM-involved evaluation. Extensive empirical studies are tagged to support the aforementioned claims.
Joining datasets via data augmentation in the label space for neural networks
Jun 17, 2021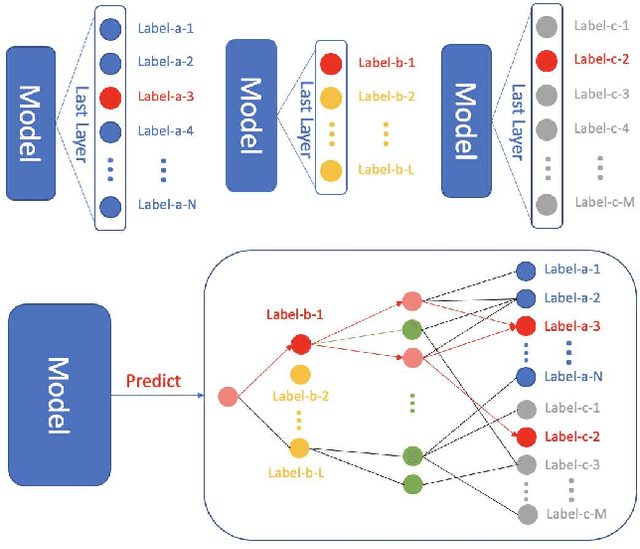
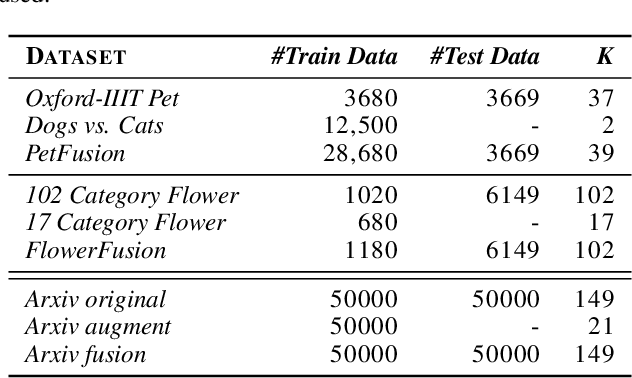
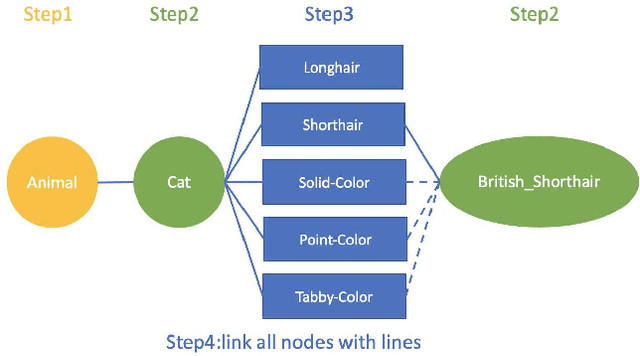
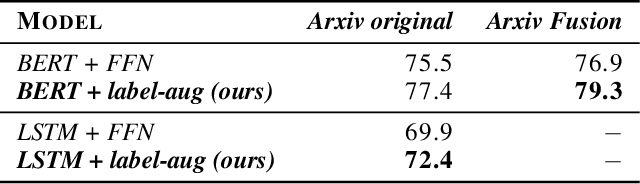
Most, if not all, modern deep learning systems restrict themselves to a single dataset for neural network training and inference. In this article, we are interested in systematic ways to join datasets that are made of similar purposes. Unlike previous published works that ubiquitously conduct the dataset joining in the uninterpretable latent vectorial space, the core to our method is an augmentation procedure in the label space. The primary challenge to address the label space for dataset joining is the discrepancy between labels: non-overlapping label annotation sets, different labeling granularity or hierarchy and etc. Notably we propose a new technique leveraging artificially created knowledge graph, recurrent neural networks and policy gradient that successfully achieve the dataset joining in the label space. Empirical results on both image and text classification justify the validity of our approach.