 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArthroCut: Autonomous Policy Learning for Robotic Bone Resection in Knee Arthroplasty
Mar 04, 2026Despite rapid commercialization of surgical robots, their autonomy and real-time decision-making remain limited in practice. To address this gap, we propose ArthroCut, an autonomous policy learning framework that upgrades knee arthroplasty robots from assistive execution to context-aware action generation. ArthroCut fine-tunes a Qwen--VL backbone on a self-built, time-synchronized multimodal dataset from 21 complete cases (23,205 RGB--D pairs), integrating preoperative CT/MR, intraoperative NDI tracking of bones and end effector, RGB--D surgical video, robot state, and textual intent. The method operates on two complementary token families -- Preoperative Imaging Tokens (PIT) to encode patient-specific anatomy and planned resection planes, and Time-Aligned Surgical Tokens (TAST) to fuse real-time visual, geometric, and kinematic evidence -- and emits an interpretable action grammar under grammar/safety-constrained decoding. In bench-top experiments on a knee prosthesis across seven trials, ArthroCut achieves an average success rate of 86% over the six standard resections, significantly outperforming strong baselines trained under the same protocol. Ablations show that TAST is the principal driver of reliability while PIT provides essential anatomical grounding, and their combination yields the most stable multi-plane execution. These results indicate that aligning preoperative geometry with time-aligned intraoperative perception and translating that alignment into tokenized, constrained actions is an effective path toward robust, interpretable autonomy in orthopedic robotic surgery.
Heteroscedastic Bayesian Optimization-Based Dynamic PID Tuning for Accurate and Robust UAV Trajectory Tracking
Dec 30, 2025Unmanned Aerial Vehicles (UAVs) play an important role in various applications, where precise trajectory tracking is crucial. However, conventional control algorithms for trajectory tracking often exhibit limited performance due to the underactuated, nonlinear, and highly coupled dynamics of quadrotor systems. To address these challenges, we propose HBO-PID, a novel control algorithm that integrates the Heteroscedastic Bayesian Optimization (HBO) framework with the classical PID controller to achieve accurate and robust trajectory tracking. By explicitly modeling input-dependent noise variance, the proposed method can better adapt to dynamic and complex environments, and therefore improve the accuracy and robustness of trajectory tracking. To accelerate the convergence of optimization, we adopt a two-stage optimization strategy that allow us to more efficiently find the optimal controller parameters. Through experiments in both simulation and real-world scenarios, we demonstrate that the proposed method significantly outperforms state-of-the-art (SOTA) methods. Compared to SOTA methods, it improves the position accuracy by 24.7% to 42.9%, and the angular accuracy by 40.9% to 78.4%.
* Accepted by IROS 2025 (2025 IEEE/RSJ International Conference on Intelligent Robots and Systems)
SPA++: Generalized Graph Spectral Alignment for Versatile Domain Adaptation
Aug 07, 2025Domain Adaptation (DA) aims to transfer knowledge from a labeled source domain to an unlabeled or sparsely labeled target domain under domain shifts. Most prior works focus on capturing the inter-domain transferability but largely overlook rich intra-domain structures, which empirically results in even worse discriminability. To tackle this tradeoff, we propose a generalized graph SPectral Alignment framework, SPA++. Its core is briefly condensed as follows: (1)-by casting the DA problem to graph primitives, it composes a coarse graph alignment mechanism with a novel spectral regularizer toward aligning the domain graphs in eigenspaces; (2)-we further develop a fine-grained neighbor-aware propagation mechanism for enhanced discriminability in the target domain; (3)-by incorporating data augmentation and consistency regularization, SPA++ can adapt to complex scenarios including most DA settings and even challenging distribution scenarios. Furthermore, we also provide theoretical analysis to support our method, including the generalization bound of graph-based DA and the role of spectral alignment and smoothing consistency. Extensive experiments on benchmark datasets demonstrate that SPA++ consistently outperforms existing cutting-edge methods, achieving superior robustness and adaptability across various challenging adaptation scenarios.
RealHiTBench: A Comprehensive Realistic Hierarchical Table Benchmark for Evaluating LLM-Based Table Analysis
Jun 16, 2025With the rapid advancement of Large Language Models (LLMs), there is an increasing need for challenging benchmarks to evaluate their capabilities in handling complex tabular data. However, existing benchmarks are either based on outdated data setups or focus solely on simple, flat table structures. In this paper, we introduce RealHiTBench, a comprehensive benchmark designed to evaluate the performance of both LLMs and Multimodal LLMs (MLLMs) across a variety of input formats for complex tabular data, including LaTeX, HTML, and PNG. RealHiTBench also includes a diverse collection of tables with intricate structures, spanning a wide range of task types. Our experimental results, using 25 state-of-the-art LLMs, demonstrate that RealHiTBench is indeed a challenging benchmark. Moreover, we also develop TreeThinker, a tree-based pipeline that organizes hierarchical headers into a tree structure for enhanced tabular reasoning, validating the importance of improving LLMs' perception of table hierarchies. We hope that our work will inspire further research on tabular data reasoning and the development of more robust models. The code and data are available at https://github.com/cspzyy/RealHiTBench.
ParMod: A Parallel and Modular Framework for Learning Non-Markovian Tasks
Dec 17, 2024



The commonly used Reinforcement Learning (RL) model, MDPs (Markov Decision Processes), has a basic premise that rewards depend on the current state and action only. However, many real-world tasks are non-Markovian, which has long-term memory and dependency. The reward sparseness problem is further amplified in non-Markovian scenarios. Hence learning a non-Markovian task (NMT) is inherently more difficult than learning a Markovian one. In this paper, we propose a novel \textbf{Par}allel and \textbf{Mod}ular RL framework, ParMod, specifically for learning NMTs specified by temporal logic. With the aid of formal techniques, the NMT is modulaized into a series of sub-tasks based on the automaton structure (equivalent to its temporal logic counterpart). On this basis, sub-tasks will be trained by a group of agents in a parallel fashion, with one agent handling one sub-task. Besides parallel training, the core of ParMod lies in: a flexible classification method for modularizing the NMT, and an effective reward shaping method for improving the sample efficiency. A comprehensive evaluation is conducted on several challenging benchmark problems with respect to various metrics. The experimental results show that ParMod achieves superior performance over other relevant studies. Our work thus provides a good synergy among RL, NMT and temporal logic.
Using Experience Classification for Training Non-Markovian Tasks
Oct 18, 2023



Unlike the standard Reinforcement Learning (RL) model, many real-world tasks are non-Markovian, whose rewards are predicated on state history rather than solely on the current state. Solving a non-Markovian task, frequently applied in practical applications such as autonomous driving, financial trading, and medical diagnosis, can be quite challenging. We propose a novel RL approach to achieve non-Markovian rewards expressed in temporal logic LTL$_f$ (Linear Temporal Logic over Finite Traces). To this end, an encoding of linear complexity from LTL$_f$ into MDPs (Markov Decision Processes) is introduced to take advantage of advanced RL algorithms. Then, a prioritized experience replay technique based on the automata structure (semantics equivalent to LTL$_f$ specification) is utilized to improve the training process. We empirically evaluate several benchmark problems augmented with non-Markovian tasks to demonstrate the feasibility and effectiveness of our approach.
From General to Specific: Informative Scene Graph Generation via Balance Adjustment
Aug 30, 2021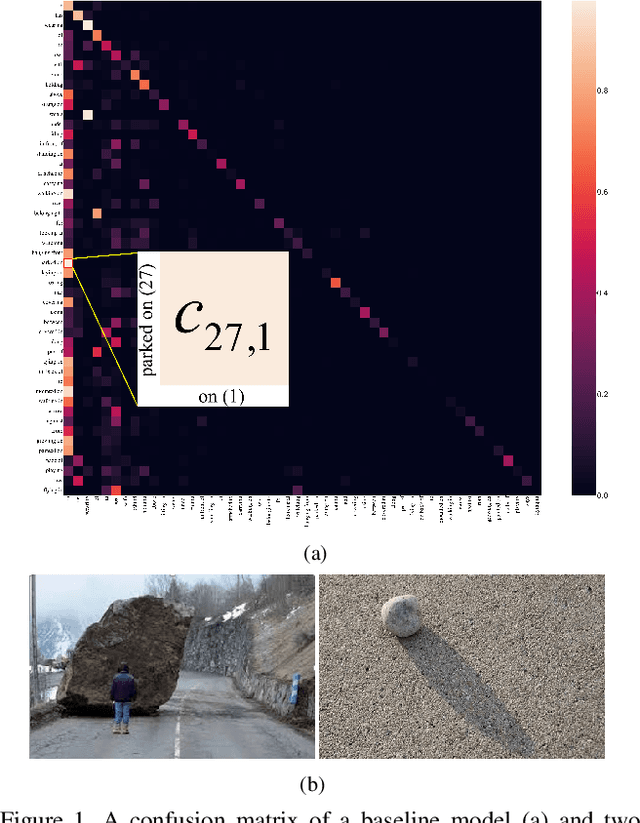
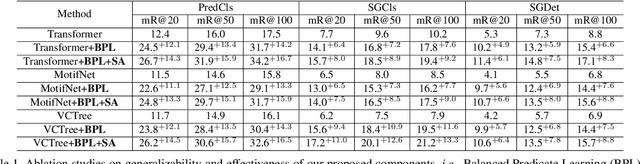

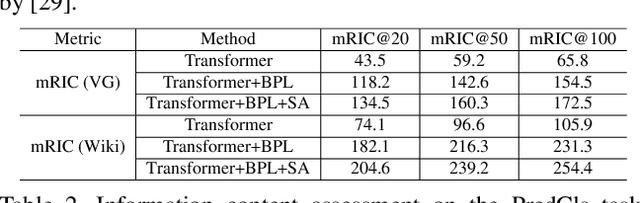
The scene graph generation (SGG) task aims to detect visual relationship triplets, i.e., subject, predicate, object, in an image, providing a structural vision layout for scene understanding. However, current models are stuck in common predicates, e.g., "on" and "at", rather than informative ones, e.g., "standing on" and "looking at", resulting in the loss of precise information and overall performance. If a model only uses "stone on road" rather than "blocking" to describe an image, it is easy to misunderstand the scene. We argue that this phenomenon is caused by two key imbalances between informative predicates and common ones, i.e., semantic space level imbalance and training sample level imbalance. To tackle this problem, we propose BA-SGG, a simple yet effective SGG framework based on balance adjustment but not the conventional distribution fitting. It integrates two components: Semantic Adjustment (SA) and Balanced Predicate Learning (BPL), respectively for adjusting these imbalances. Benefited from the model-agnostic process, our method is easily applied to the state-of-the-art SGG models and significantly improves the SGG performance. Our method achieves 14.3%, 8.0%, and 6.1% higher Mean Recall (mR) than that of the Transformer model at three scene graph generation sub-tasks on Visual Genome, respectively. Codes are publicly available.
A Syllable-Structured, Contextually-Based Conditionally Generation of Chinese Lyrics
Jun 15, 2019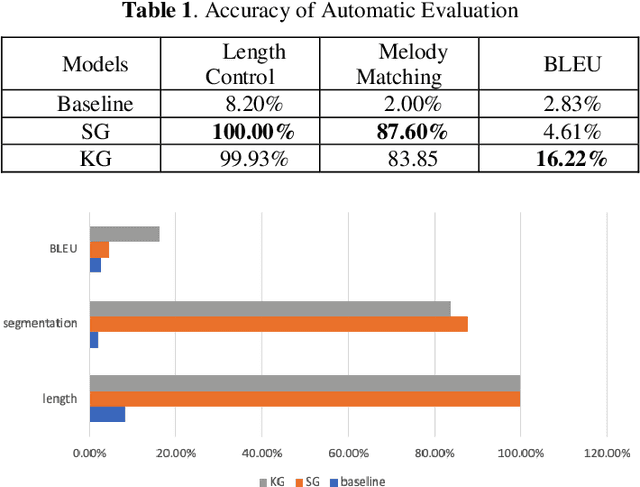
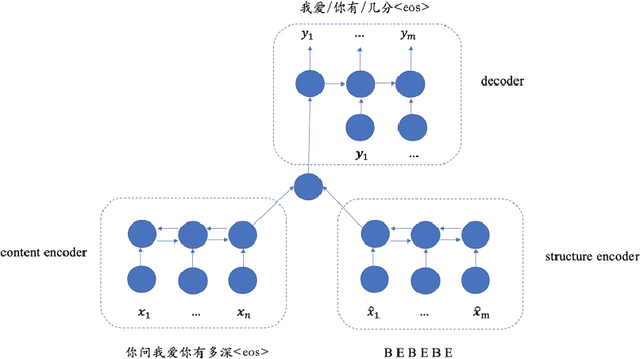


This paper presents a novel, syllable-structured Chinese lyrics generation model given a piece of original melody. Most previously reported lyrics generation models fail to include the relationship between lyrics and melody. In this work, we propose to interpret lyrics-melody alignments as syllable structural information and use a multi-channel sequence-to-sequence model with considering both phrasal structures and semantics. Two different RNN encoders are applied, one of which is for encoding syllable structures while the other for semantic encoding with contextual sentences or input keywords. Moreover, a large Chinese lyrics corpus for model training is leveraged. With automatic and human evaluations, results demonstrate the effectiveness of our proposed lyrics generation model. To the best of our knowledge, there is few previous reports on lyrics generation considering both music and linguistic perspectives.