 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Syllable-Structured, Contextually-Based Conditionally Generation of Chinese Lyrics
Paper and Code
Jun 15, 2019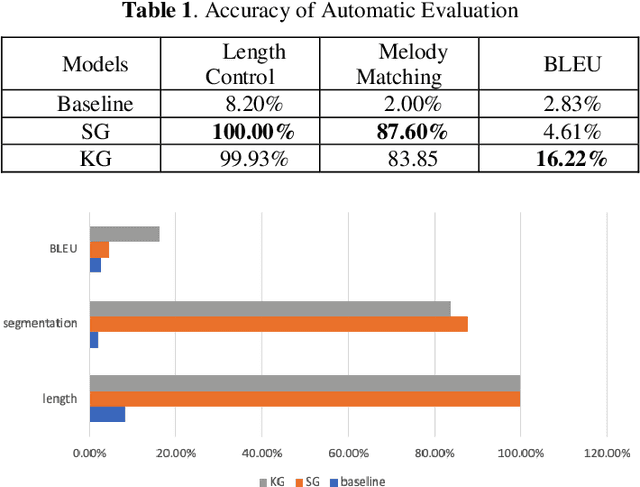
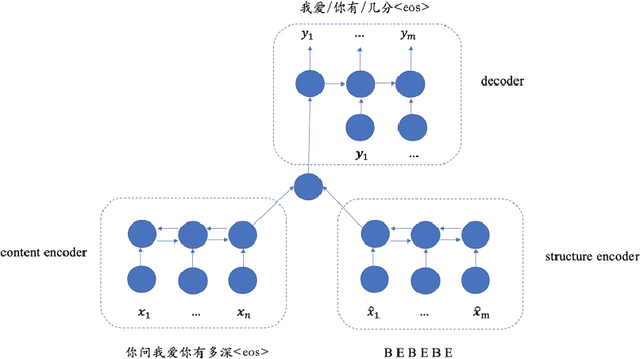


This paper presents a novel, syllable-structured Chinese lyrics generation model given a piece of original melody. Most previously reported lyrics generation models fail to include the relationship between lyrics and melody. In this work, we propose to interpret lyrics-melody alignments as syllable structural information and use a multi-channel sequence-to-sequence model with considering both phrasal structures and semantics. Two different RNN encoders are applied, one of which is for encoding syllable structures while the other for semantic encoding with contextual sentences or input keywords. Moreover, a large Chinese lyrics corpus for model training is leveraged. With automatic and human evaluations, results demonstrate the effectiveness of our proposed lyrics generation model. To the best of our knowledge, there is few previous reports on lyrics generation considering both music and linguistic perspectives.