 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBS-NAS: Broadening-and-Shrinking One-Shot NAS with Searchable Numbers of Channels
Mar 22, 2020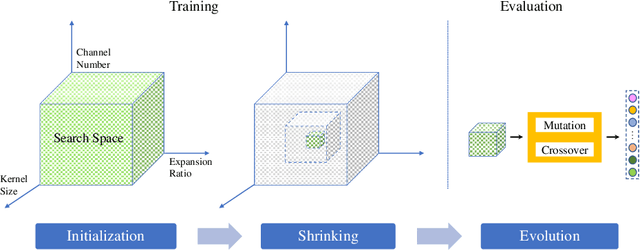

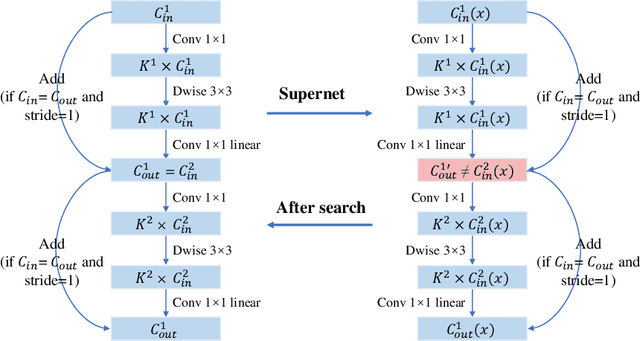
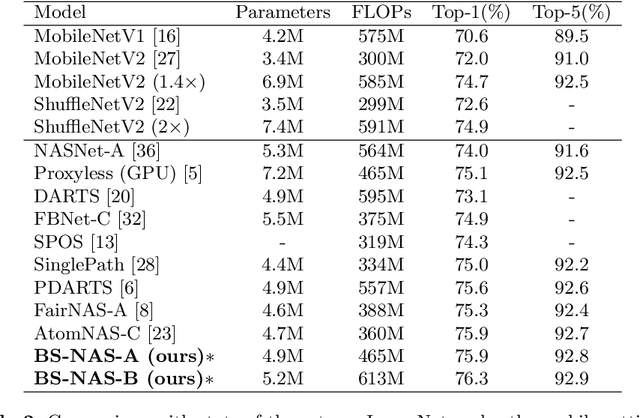
One-Shot methods have evolved into one of the most popular methods in Neural Architecture Search (NAS) due to weight sharing and single training of a supernet. However, existing methods generally suffer from two issues: predetermined number of channels in each layer which is suboptimal; and model averaging effects and poor ranking correlation caused by weight coupling and continuously expanding search space. To explicitly address these issues, in this paper, a Broadening-and-Shrinking One-Shot NAS (BS-NAS) framework is proposed, in which `broadening' refers to broadening the search space with a spring block enabling search for numbers of channels during training of the supernet; while `shrinking' refers to a novel shrinking strategy gradually turning off those underperforming operations. The above innovations broaden the search space for wider representation and then shrink it by gradually removing underperforming operations, followed by an evolutionary algorithm to efficiently search for the optimal architecture. Extensive experiments on ImageNet illustrate the effectiveness of the proposed BS-NAS as well as the state-of-the-art performance.
An Iterative Polishing Framework based on Quality Aware Masked Language Model for Chinese Poetry Generation
Nov 29, 2019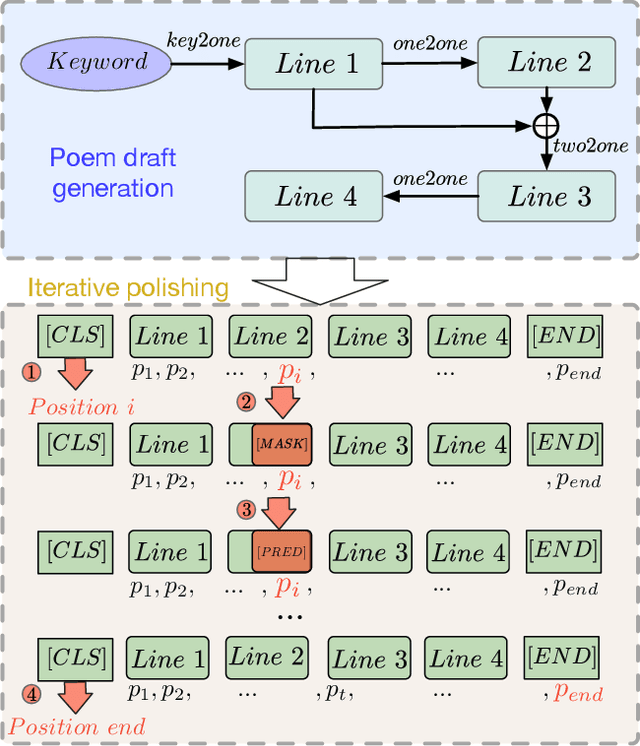
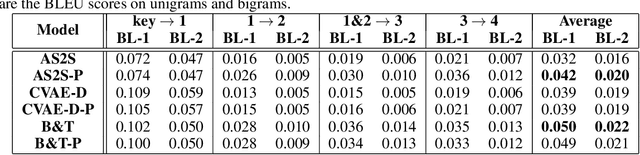
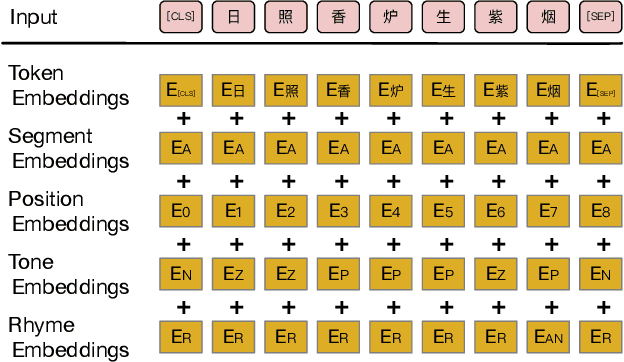

Owing to its unique literal and aesthetical characteristics, automatic generation of Chinese poetry is still challenging in Artificial Intelligence, which can hardly be straightforwardly realized by end-to-end methods. In this paper, we propose a novel iterative polishing framework for highly qualified Chinese poetry generation. In the first stage, an encoder-decoder structure is utilized to generate a poem draft. Afterwards, our proposed Quality-Aware Masked Language Model (QAMLM) is employed to polish the draft towards higher quality in terms of linguistics and literalness. Based on a multi-task learning scheme, QA-MLM is able to determine whether polishing is needed based on the poem draft. Furthermore, QAMLM is able to localize improper characters of the poem draft and substitute with newly predicted ones accordingly. Benefited from the masked language model structure, QAMLM incorporates global context information into the polishing process, which can obtain more appropriate polishing results than the unidirectional sequential decoding. Moreover, the iterative polishing process will be terminated automatically when QA-MLM regards the processed poem as a qualified one. Both human and automatic evaluation have been conducted, and the results demonstrate that our approach is effective to improve the performance of encoder-decoder structure.
Cross-Platform Modeling of Users' Behavior on Social Media
Jun 23, 2019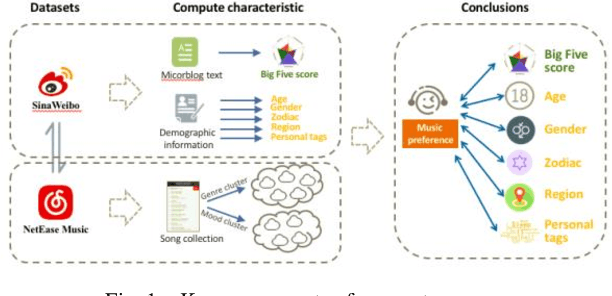
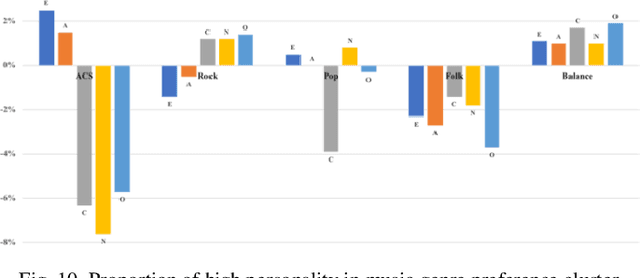
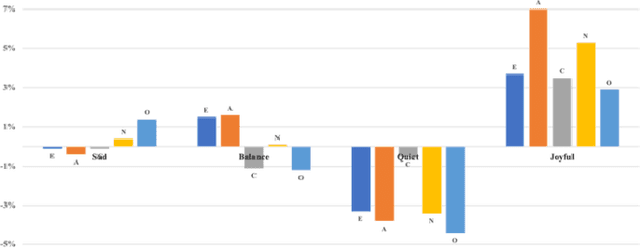
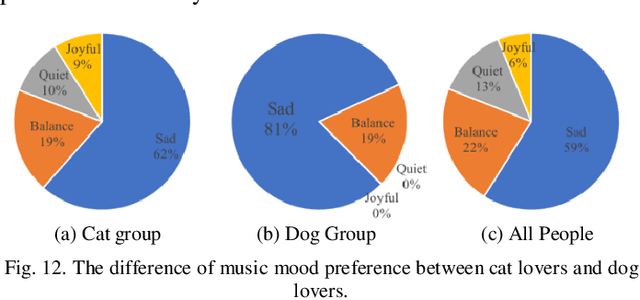
With the booming development and popularity of mobile applications, different verticals accumulate abundant data of user information and social behavior, which are spontaneous, genuine and diversified. However, each platform describes user's portraits in only certain aspect, resulting in difficult combination of those internet footprints together. In our research, we proposed a modeling approach to analyze user's online behavior across different social media platforms. Structured and unstructured data of same users shared by NetEase Music and Sina Weibo have been collected for cross-platform analysis of correlations between music preference and other users' characteristics. Based on music tags of genre and mood, genre cluster of five groups and mood cluster of four groups have been formed by computing their collected song lists with K-means method. Moreover, with the help of user data of Weibo, correlations between music preference (i.e. genre, mood) and Big Five personalities (BFPs) and basic information (e.g. gender, resident region, tags) have been comprehensively studied, building up full-scale user portraits with finer grain. Our findings indicate that people's music preference could be linked with their real social activities. For instance, people living in mountainous areas generally prefer folk music, while those in urban areas like pop music more. Interestingly, dog lovers could love sad music more than cat lovers. Moreover, our proposed cross-platform modeling approach could be adapted to other verticals, providing an online automatic way for profiling users in a more precise and comprehensive way.
* Published in IEEE International Conference on Data Mining Workshops (ICDMW) 2018
Automatic Conditional Generation of Personalized Social Media Short Texts
Jun 15, 2019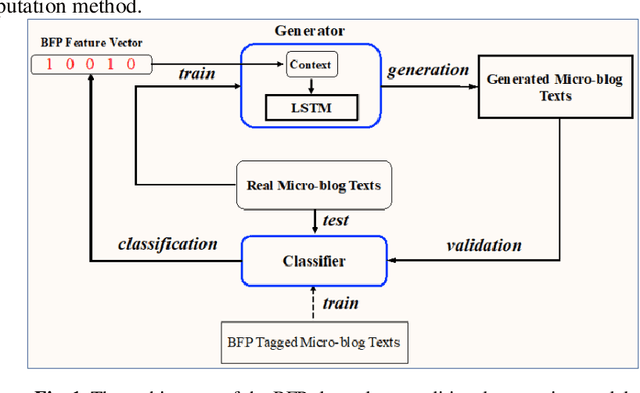
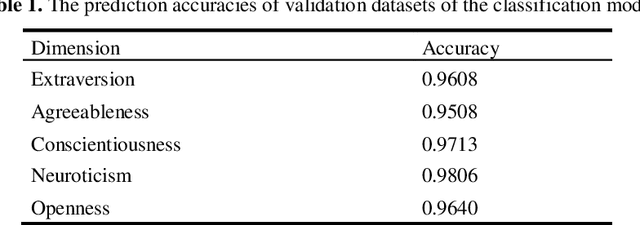
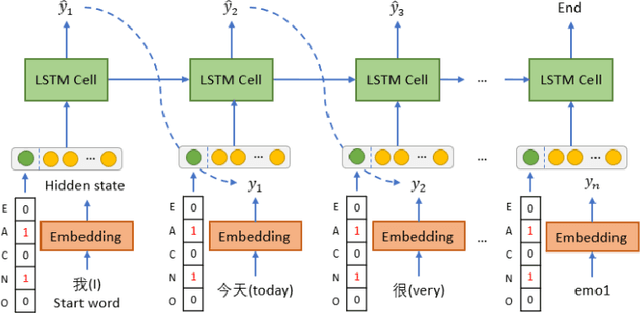

Automatic text generation has received much attention owing to rapid development of deep neural networks. In general, text generation systems based on statistical language model will not consider anthropomorphic characteristics, which results in machine-like generated texts. To fill the gap, we propose a conditional language generation model with Big Five Personality (BFP) feature vectors as input context, which writes human-like short texts. The short text generator consists of a layer of long short memory network (LSTM), where a BFP feature vector is concatenated as one part of input for each cell. To enable supervised training generation model, a text classification model based convolution neural network (CNN) has been used to prepare BFP-tagged Chinese micro-blog corpora. Validated by a BFP linguistic computational model, our generated Chinese short texts exhibit discriminative personality styles, which are also syntactically correct and semantically smooth with appropriate emoticons. With combination of natural language generation with psychological linguistics, our proposed BFP-dependent text generation model can be widely used for individualization in machine translation, image caption, dialogue generation and so on.
* published in PRICAI 2018
A Syllable-Structured, Contextually-Based Conditionally Generation of Chinese Lyrics
Jun 15, 2019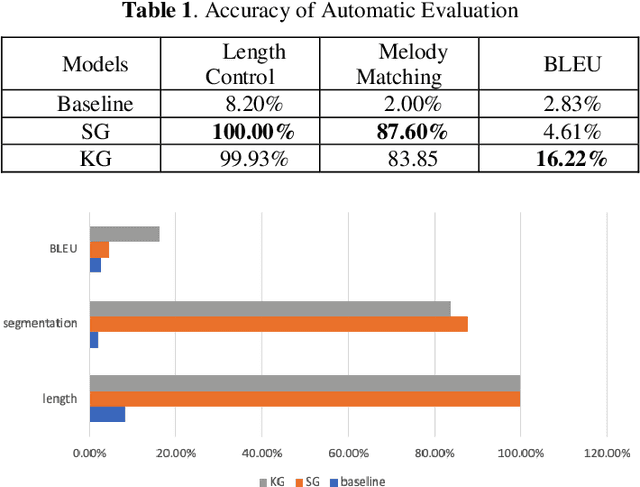
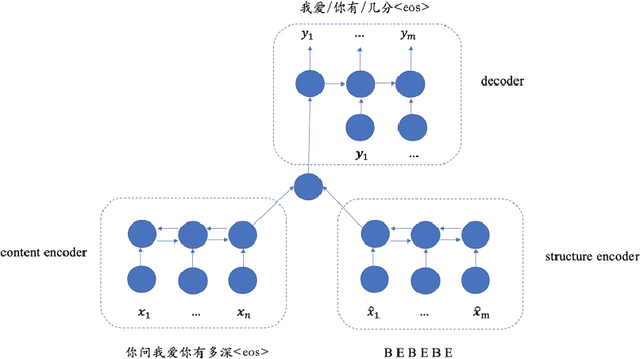


This paper presents a novel, syllable-structured Chinese lyrics generation model given a piece of original melody. Most previously reported lyrics generation models fail to include the relationship between lyrics and melody. In this work, we propose to interpret lyrics-melody alignments as syllable structural information and use a multi-channel sequence-to-sequence model with considering both phrasal structures and semantics. Two different RNN encoders are applied, one of which is for encoding syllable structures while the other for semantic encoding with contextual sentences or input keywords. Moreover, a large Chinese lyrics corpus for model training is leveraged. With automatic and human evaluations, results demonstrate the effectiveness of our proposed lyrics generation model. To the best of our knowledge, there is few previous reports on lyrics generation considering both music and linguistic perspectives.
A Hierarchical Attention Based Seq2seq Model for Chinese Lyrics Generation
Jun 15, 2019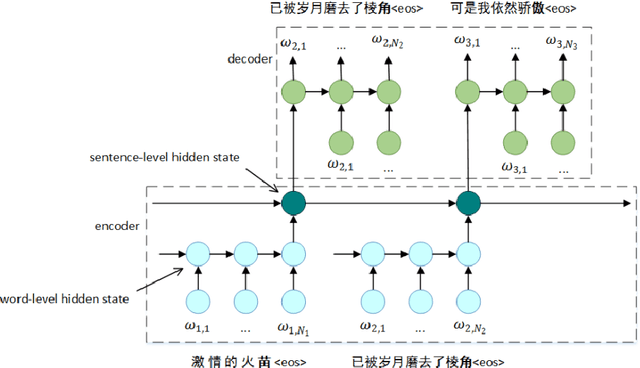

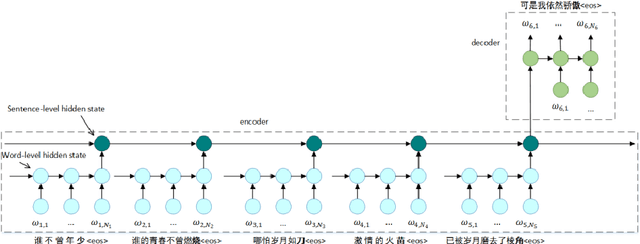

In this paper, we comprehensively study on context-aware generation of Chinese song lyrics. Conventional text generative models generate a sequence or sentence word by word, failing to consider the contextual relationship between sentences. Taking account into the characteristics of lyrics, a hierarchical attention based Seq2Seq (Sequence-to-Sequence) model is proposed for Chinese lyrics generation. With encoding of word-level and sentence-level contextual information, this model promotes the topic relevance and consistency of generation. A large Chinese lyrics corpus is also leveraged for model training. Eventually, results of automatic and human evaluations demonstrate that our model is able to compose complete Chinese lyrics with one united topic constraint.
Automatic Acrostic Couplet Generation with Three-Stage Neural Network Pipelines
Jun 15, 2019

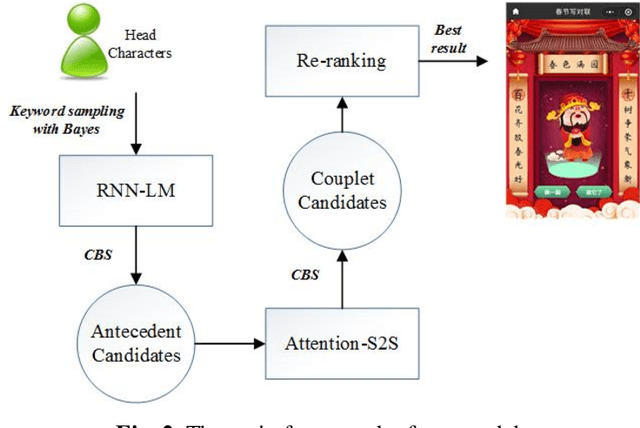

As one of the quintessence of Chinese traditional culture, couplet compromises two syntactically symmetric clauses equal in length, namely, an antecedent and subsequent clause. Moreover, corresponding characters and phrases at the same position of the two clauses are paired with each other under certain constraints of semantic and/or syntactic relatedness. Automatic couplet generation is recognized as a challenging problem even in the Artificial Intelligence field. In this paper, we comprehensively study on automatic generation of acrostic couplet with the first characters defined by users. The complete couplet generation is mainly divided into three stages, that is, antecedent clause generation pipeline, subsequent clause generation pipeline and clause re-ranker. To realize semantic and/or syntactic relatedness between two clauses, attention-based Sequence-to-Sequence (S2S) neural network is employed. Moreover, to provide diverse couplet candidates for re-ranking, a cluster-based beam search approach is incorporated into the S2S network. Both BLEU metrics and human judgments have demonstrated the effectiveness of our proposed method. Eventually, a mini-program based on this generation system is developed and deployed on Wechat for real users.
Deep Inferential Spatial-Temporal Network for Forecasting Air Pollution Concentrations
Sep 11, 2018



Air pollution poses a serious threat to human health as well as economic development around the world. To meet the increasing demand for accurate predictions for air pollutions, we proposed a Deep Inferential Spatial-Temporal Network to deal with the complicated non-linear spatial and temporal correlations. We forecast three air pollutants (i.e., PM2.5, PM10 and O3) of monitoring stations over the next 48 hours, using a hybrid deep learning model consists of inferential predictor (inference for regions without air pollution readings), spatial predictor (capturing spatial correlations using CNN) and temporal predictor (capturing temporal relationship using sequence-to-sequence model with simplified attention mechanism). Our proposed model considers historical air pollution records and historical meteorological data. We evaluate our model on a large-scale dataset containing air pollution records of 35 monitoring stations and grid meteorological data in Beijing, China. Our model outperforms other state-of-art methods in terms of SMAPE and RMSE.