 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPA++: Generalized Graph Spectral Alignment for Versatile Domain Adaptation
Aug 07, 2025Domain Adaptation (DA) aims to transfer knowledge from a labeled source domain to an unlabeled or sparsely labeled target domain under domain shifts. Most prior works focus on capturing the inter-domain transferability but largely overlook rich intra-domain structures, which empirically results in even worse discriminability. To tackle this tradeoff, we propose a generalized graph SPectral Alignment framework, SPA++. Its core is briefly condensed as follows: (1)-by casting the DA problem to graph primitives, it composes a coarse graph alignment mechanism with a novel spectral regularizer toward aligning the domain graphs in eigenspaces; (2)-we further develop a fine-grained neighbor-aware propagation mechanism for enhanced discriminability in the target domain; (3)-by incorporating data augmentation and consistency regularization, SPA++ can adapt to complex scenarios including most DA settings and even challenging distribution scenarios. Furthermore, we also provide theoretical analysis to support our method, including the generalization bound of graph-based DA and the role of spectral alignment and smoothing consistency. Extensive experiments on benchmark datasets demonstrate that SPA++ consistently outperforms existing cutting-edge methods, achieving superior robustness and adaptability across various challenging adaptation scenarios.
ALPS: Attention Localization and Pruning Strategy for Efficient Alignment of Large Language Models
May 24, 2025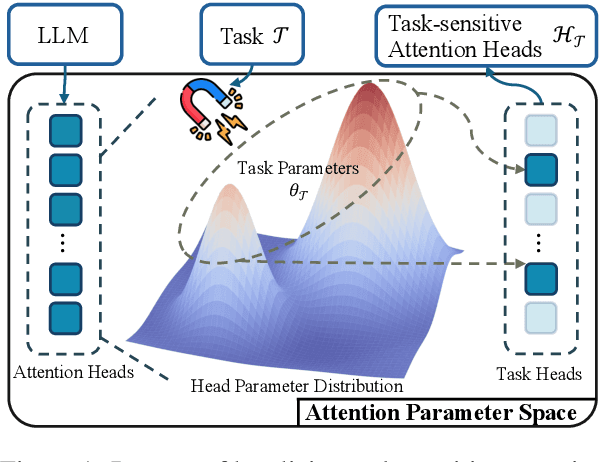
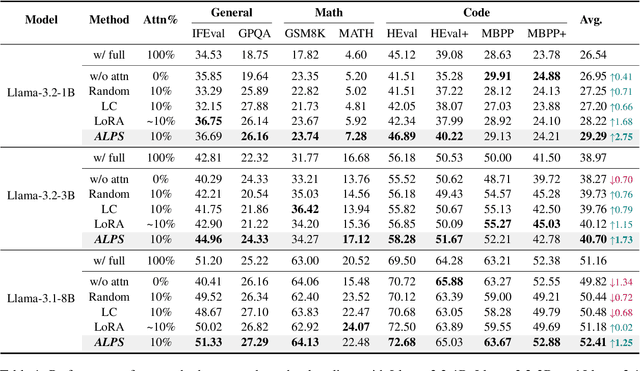

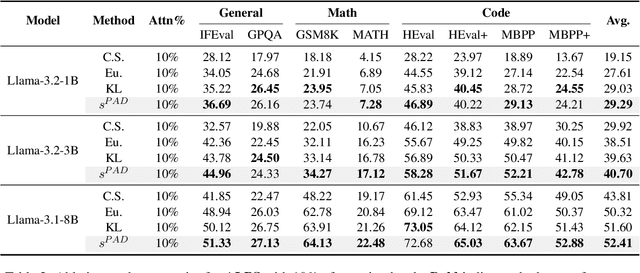
Aligning general-purpose large language models (LLMs) to downstream tasks often incurs significant costs, including constructing task-specific instruction pairs and extensive training adjustments. Prior research has explored various avenues to enhance alignment efficiency, primarily through minimal-data training or data-driven activations to identify key attention heads. However, these approaches inherently introduce data dependency, which hinders generalization and reusability. To address this issue and enhance model alignment efficiency, we propose the \textit{\textbf{A}ttention \textbf{L}ocalization and \textbf{P}runing \textbf{S}trategy (\textbf{ALPS})}, an efficient algorithm that localizes the most task-sensitive attention heads and prunes by restricting attention training updates to these heads, thereby reducing alignment costs. Experimental results demonstrate that our method activates only \textbf{10\%} of attention parameters during fine-tuning while achieving a \textbf{2\%} performance improvement over baselines on three tasks. Moreover, the identified task-specific heads are transferable across datasets and mitigate knowledge forgetting. Our work and findings provide a novel perspective on efficient LLM alignment.
D.Va: Validate Your Demonstration First Before You Use It
Feb 19, 2025In-context learning (ICL) has demonstrated significant potential in enhancing the capabilities of large language models (LLMs) during inference. It's well-established that ICL heavily relies on selecting effective demonstrations to generate outputs that better align with the expected results. As for demonstration selection, previous approaches have typically relied on intuitive metrics to evaluate the effectiveness of demonstrations, which often results in limited robustness and poor cross-model generalization capabilities. To tackle these challenges, we propose a novel method, \textbf{D}emonstration \textbf{VA}lidation (\textbf{D.Va}), which integrates a demonstration validation perspective into this field. By introducing the demonstration validation mechanism, our method effectively identifies demonstrations that are both effective and highly generalizable. \textbf{D.Va} surpasses all existing demonstration selection techniques across both natural language understanding (NLU) and natural language generation (NLG) tasks. Additionally, we demonstrate the robustness and generalizability of our approach across various language models with different retrieval models.
AIGT: AI Generative Table Based on Prompt
Dec 24, 2024



Tabular data, which accounts for over 80% of enterprise data assets, is vital in various fields. With growing concerns about privacy protection and data-sharing restrictions, generating high-quality synthetic tabular data has become essential. Recent advancements show that large language models (LLMs) can effectively gener-ate realistic tabular data by leveraging semantic information and overcoming the challenges of high-dimensional data that arise from one-hot encoding. However, current methods do not fully utilize the rich information available in tables. To address this, we introduce AI Generative Table (AIGT) based on prompt enhancement, a novel approach that utilizes meta data information, such as table descriptions and schemas, as prompts to generate ultra-high quality synthetic data. To overcome the token limit constraints of LLMs, we propose long-token partitioning algorithms that enable AIGT to model tables of any scale. AIGT achieves state-of-the-art performance on 14 out of 20 public datasets and two real industry datasets within the Alipay risk control system.
From Laws to Motivation: Guiding Exploration through Law-Based Reasoning and Rewards
Nov 24, 2024



Large Language Models (LLMs) and Reinforcement Learning (RL) are two powerful approaches for building autonomous agents. However, due to limited understanding of the game environment, agents often resort to inefficient exploration and trial-and-error, struggling to develop long-term strategies or make decisions. We propose a method that extracts experience from interaction records to model the underlying laws of the game environment, using these experience as internal motivation to guide agents. These experience, expressed in language, are highly flexible and can either assist agents in reasoning directly or be transformed into rewards for guiding training. Our evaluation results in Crafter demonstrate that both RL and LLM agents benefit from these experience, leading to improved overall performance.
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Nov 04, 2024The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact.
Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Apr 02, 2024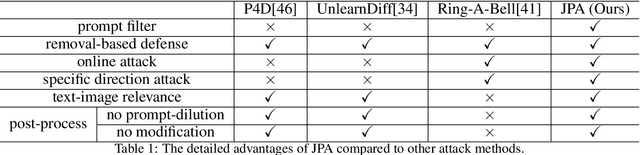



The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.
SPA: A Graph Spectral Alignment Perspective for Domain Adaptation
Oct 27, 2023Unsupervised domain adaptation (UDA) is a pivotal form in machine learning to extend the in-domain model to the distinctive target domains where the data distributions differ. Most prior works focus on capturing the inter-domain transferability but largely overlook rich intra-domain structures, which empirically results in even worse discriminability. In this work, we introduce a novel graph SPectral Alignment (SPA) framework to tackle the tradeoff. The core of our method is briefly condensed as follows: (i)-by casting the DA problem to graph primitives, SPA composes a coarse graph alignment mechanism with a novel spectral regularizer towards aligning the domain graphs in eigenspaces; (ii)-we further develop a fine-grained message propagation module -- upon a novel neighbor-aware self-training mechanism -- in order for enhanced discriminability in the target domain. On standardized benchmarks, the extensive experiments of SPA demonstrate that its performance has surpassed the existing cutting-edge DA methods. Coupled with dense model analysis, we conclude that our approach indeed possesses superior efficacy, robustness, discriminability, and transferability. Code and data are available at: https://github.com/CrownX/SPA.
DropMessage: Unifying Random Dropping for Graph Neural Networks
Apr 21, 2022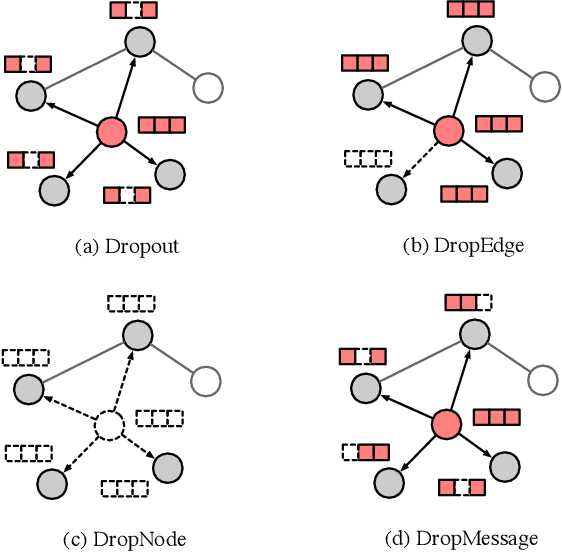

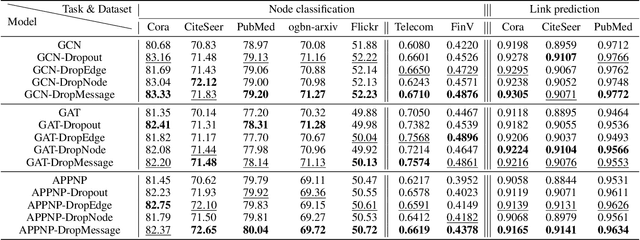
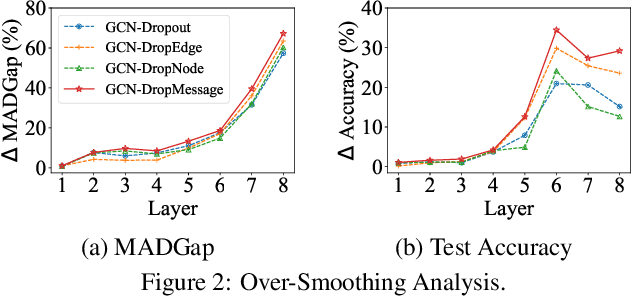
Graph Neural Networks (GNNs) are powerful tools for graph representation learning. Despite their rapid development, GNNs also faces some challenges, such as over-fitting, over-smoothing, and non-robustness. Previous works indicate that these problems can be alleviated by random dropping methods, which integrate noises into models by randomly masking parts of the input. However, some open-ended problems of random dropping on GNNs remain to solve. First, it is challenging to find a universal method that are suitable for all cases considering the divergence of different datasets and models. Second, random noises introduced to GNNs cause the incomplete coverage of parameters and unstable training process. In this paper, we propose a novel random dropping method called DropMessage, which performs dropping operations directly on the message matrix and can be applied to any message-passing GNNs. Furthermore, we elaborate the superiority of DropMessage: it stabilizes the training process by reducing sample variance; it keeps information diversity from the perspective of information theory, which makes it a theoretical upper bound of other methods. Also, we unify existing random dropping methods into our framework and analyze their effects on GNNs. To evaluate our proposed method, we conduct experiments that aims for multiple tasks on five public datasets and two industrial datasets with various backbone models. The experimental results show that DropMessage has both advantages of effectiveness and generalization.