 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropMessage: Unifying Random Dropping for Graph Neural Networks
Paper and Code
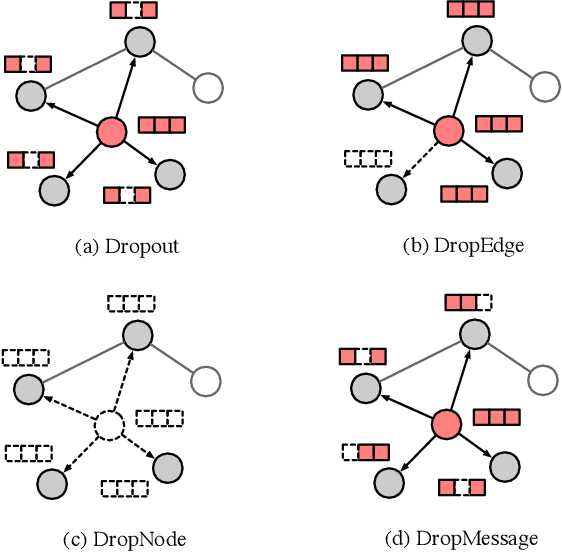

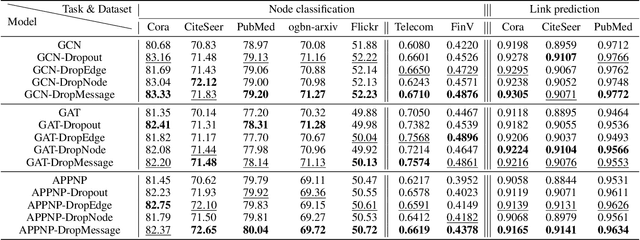
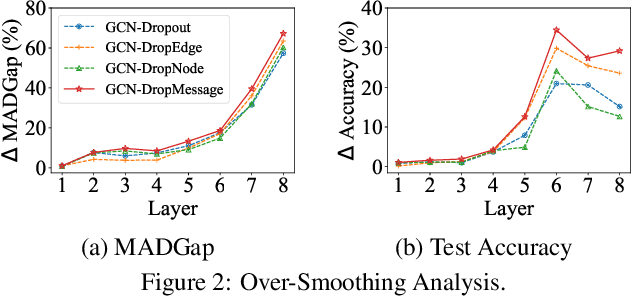
Graph Neural Networks (GNNs) are powerful tools for graph representation learning. Despite their rapid development, GNNs also faces some challenges, such as over-fitting, over-smoothing, and non-robustness. Previous works indicate that these problems can be alleviated by random dropping methods, which integrate noises into models by randomly masking parts of the input. However, some open-ended problems of random dropping on GNNs remain to solve. First, it is challenging to find a universal method that are suitable for all cases considering the divergence of different datasets and models. Second, random noises introduced to GNNs cause the incomplete coverage of parameters and unstable training process. In this paper, we propose a novel random dropping method called DropMessage, which performs dropping operations directly on the message matrix and can be applied to any message-passing GNNs. Furthermore, we elaborate the superiority of DropMessage: it stabilizes the training process by reducing sample variance; it keeps information diversity from the perspective of information theory, which makes it a theoretical upper bound of other methods. Also, we unify existing random dropping methods into our framework and analyze their effects on GNNs. To evaluate our proposed method, we conduct experiments that aims for multiple tasks on five public datasets and two industrial datasets with various backbone models. The experimental results show that DropMessage has both advantages of effectiveness and generalization.