 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Use Graph Data in the Wild to Help Graph Anomaly Detection?
Jun 04, 2025In recent years, graph anomaly detection has found extensive applications in various domains such as social, financial, and communication networks. However, anomalies in graph-structured data present unique challenges, including label scarcity, ill-defined anomalies, and varying anomaly types, making supervised or semi-supervised methods unreliable. Researchers often adopt unsupervised approaches to address these challenges, assuming that anomalies deviate significantly from the normal data distribution. Yet, when the available data is insufficient, capturing the normal distribution accurately and comprehensively becomes difficult. To overcome this limitation, we propose to utilize external graph data (i.e., graph data in the wild) to help anomaly detection tasks. This naturally raises the question: How can we use external data to help graph anomaly detection tasks? To answer this question, we propose a framework called Wild-GAD. It is built upon a unified database, UniWildGraph, which comprises a large and diverse collection of graph data with broad domain coverage, ample data volume, and a unified feature space. Further, we develop selection criteria based on representativity and diversity to identify the most suitable external data for anomaly detection task. Extensive experiments on six real-world datasets demonstrate the effectiveness of Wild-GAD. Compared to the baseline methods, our framework has an average 18% AUCROC and 32% AUCPR improvement over the best-competing methods.
Ca2-VDM: Efficient Autoregressive Video Diffusion Model with Causal Generation and Cache Sharing
Nov 25, 2024With the advance of diffusion models, today's video generation has achieved impressive quality. To extend the generation length and facilitate real-world applications, a majority of video diffusion models (VDMs) generate videos in an autoregressive manner, i.e., generating subsequent clips conditioned on the last frame(s) of the previous clip. However, existing autoregressive VDMs are highly inefficient and redundant: The model must re-compute all the conditional frames that are overlapped between adjacent clips. This issue is exacerbated when the conditional frames are extended autoregressively to provide the model with long-term context. In such cases, the computational demands increase significantly (i.e., with a quadratic complexity w.r.t. the autoregression step). In this paper, we propose Ca2-VDM, an efficient autoregressive VDM with Causal generation and Cache sharing. For causal generation, it introduces unidirectional feature computation, which ensures that the cache of conditional frames can be precomputed in previous autoregression steps and reused in every subsequent step, eliminating redundant computations. For cache sharing, it shares the cache across all denoising steps to avoid the huge cache storage cost. Extensive experiments demonstrated that our Ca2-VDM achieves state-of-the-art quantitative and qualitative video generation results and significantly improves the generation speed. Code is available at https://github.com/Dawn-LX/CausalCache-VDM
Can Graph Neural Networks Expose Training Data Properties? An Efficient Risk Assessment Approach
Nov 06, 2024



Graph neural networks (GNNs) have attracted considerable attention due to their diverse applications. However, the scarcity and quality limitations of graph data present challenges to their training process in practical settings. To facilitate the development of effective GNNs, companies and researchers often seek external collaboration. Yet, directly sharing data raises privacy concerns, motivating data owners to train GNNs on their private graphs and share the trained models. Unfortunately, these models may still inadvertently disclose sensitive properties of their training graphs (e.g., average default rate in a transaction network), leading to severe consequences for data owners. In this work, we study graph property inference attack to identify the risk of sensitive property information leakage from shared models. Existing approaches typically train numerous shadow models for developing such attack, which is computationally intensive and impractical. To address this issue, we propose an efficient graph property inference attack by leveraging model approximation techniques. Our method only requires training a small set of models on graphs, while generating a sufficient number of approximated shadow models for attacks. To enhance diversity while reducing errors in the approximated models, we apply edit distance to quantify the diversity within a group of approximated models and introduce a theoretically guaranteed criterion to evaluate each model's error. Subsequently, we propose a novel selection mechanism to ensure that the retained approximated models achieve high diversity and low error. Extensive experiments across six real-world scenarios demonstrate our method's substantial improvement, with average increases of 2.7% in attack accuracy and 4.1% in ROC-AUC, while being 6.5$\times$ faster compared to the best baseline.
HazyDet: Open-source Benchmark for Drone-view Object Detection with Depth-cues in Hazy Scenes
Sep 30, 2024



Drone-based object detection in adverse weather conditions is crucial for enhancing drones' environmental perception, yet it remains largely unexplored due to the lack of relevant benchmarks. To bridge this gap, we introduce HazyDet, a large-scale dataset tailored for drone-based object detection in hazy scenes. It encompasses 383,000 real-world instances, collected from both naturally hazy environments and normal scenes with synthetically imposed haze effects to simulate adverse weather conditions. By observing the significant variations in object scale and clarity under different depth and haze conditions, we designed a Depth Conditioned Detector (DeCoDet) to incorporate this prior knowledge. DeCoDet features a Multi-scale Depth-aware Detection Head that seamlessly integrates depth perception, with the resulting depth cues harnessed by a dynamic Depth Condition Kernel module. Furthermore, we propose a Scale Invariant Refurbishment Loss to facilitate the learning of robust depth cues from pseudo-labels. Extensive evaluations on the HazyDet dataset demonstrate the flexibility and effectiveness of our method, yielding significant performance improvements. Our dataset and toolkit are available at https://github.com/GrokCV/HazyDet.
Unveiling Privacy Vulnerabilities: Investigating the Role of Structure in Graph Data
Jul 26, 2024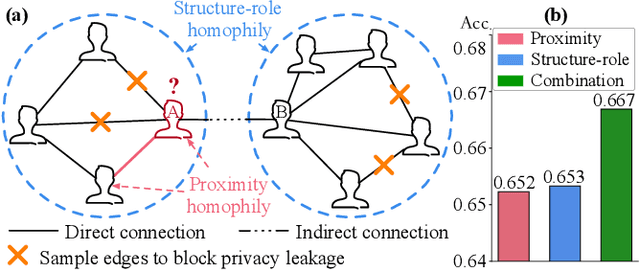
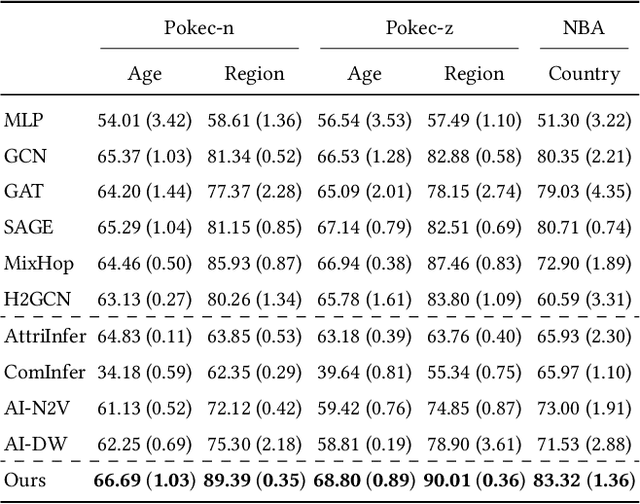
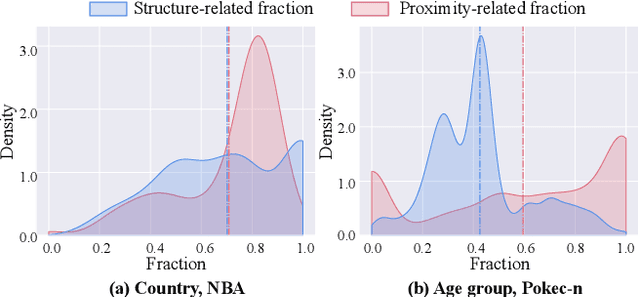
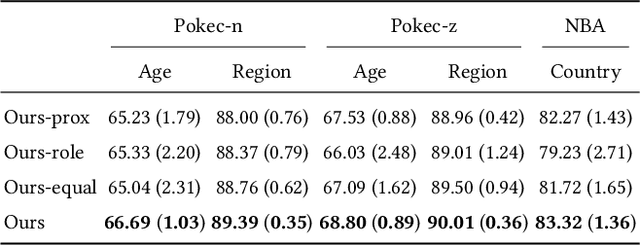
The public sharing of user information opens the door for adversaries to infer private data, leading to privacy breaches and facilitating malicious activities. While numerous studies have concentrated on privacy leakage via public user attributes, the threats associated with the exposure of user relationships, particularly through network structure, are often neglected. This study aims to fill this critical gap by advancing the understanding and protection against privacy risks emanating from network structure, moving beyond direct connections with neighbors to include the broader implications of indirect network structural patterns. To achieve this, we first investigate the problem of Graph Privacy Leakage via Structure (GPS), and introduce a novel measure, the Generalized Homophily Ratio, to quantify the various mechanisms contributing to privacy breach risks in GPS. Based on this insight, we develop a novel graph private attribute inference attack, which acts as a pivotal tool for evaluating the potential for privacy leakage through network structures under worst-case scenarios. To protect users' private data from such vulnerabilities, we propose a graph data publishing method incorporating a learnable graph sampling technique, effectively transforming the original graph into a privacy-preserving version. Extensive experiments demonstrate that our attack model poses a significant threat to user privacy, and our graph data publishing method successfully achieves the optimal privacy-utility trade-off compared to baselines.
ViD-GPT: Introducing GPT-style Autoregressive Generation in Video Diffusion Models
Jun 16, 2024



With the advance of diffusion models, today's video generation has achieved impressive quality. But generating temporal consistent long videos is still challenging. A majority of video diffusion models (VDMs) generate long videos in an autoregressive manner, i.e., generating subsequent clips conditioned on last frames of previous clip. However, existing approaches all involve bidirectional computations, which restricts the receptive context of each autoregression step, and results in the model lacking long-term dependencies. Inspired from the huge success of large language models (LLMs) and following GPT (generative pre-trained transformer), we bring causal (i.e., unidirectional) generation into VDMs, and use past frames as prompt to generate future frames. For Causal Generation, we introduce causal temporal attention into VDM, which forces each generated frame to depend on its previous frames. For Frame as Prompt, we inject the conditional frames by concatenating them with noisy frames (frames to be generated) along the temporal axis. Consequently, we present Video Diffusion GPT (ViD-GPT). Based on the two key designs, in each autoregression step, it is able to acquire long-term context from prompting frames concatenated by all previously generated frames. Additionally, we bring the kv-cache mechanism to VDMs, which eliminates the redundant computation from overlapped frames, significantly boosting the inference speed. Extensive experiments demonstrate that our ViD-GPT achieves state-of-the-art performance both quantitatively and qualitatively on long video generation. Code will be available at https://github.com/Dawn-LX/Causal-VideoGen.
$\text{Di}^2\text{Pose}$: Discrete Diffusion Model for Occluded 3D Human Pose Estimation
May 27, 2024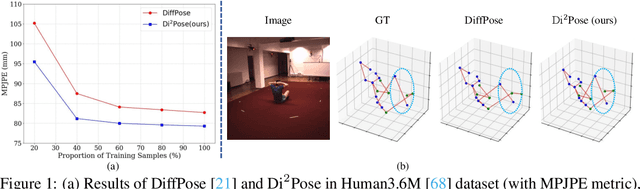
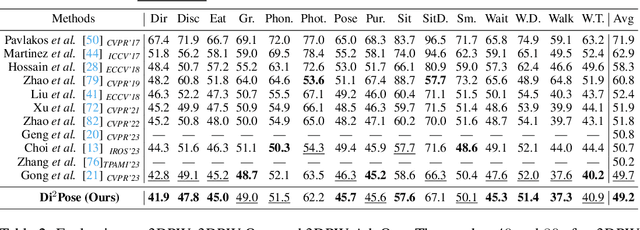
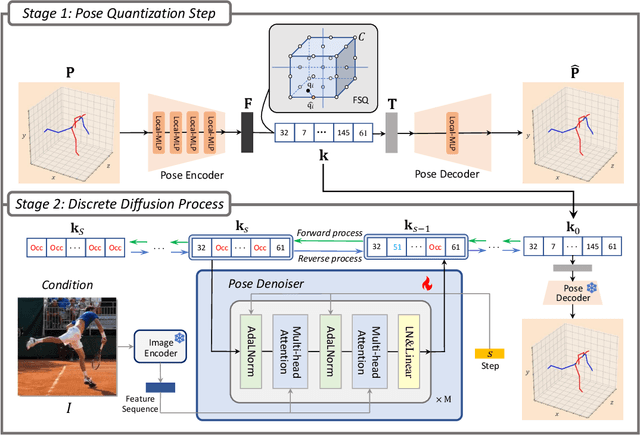
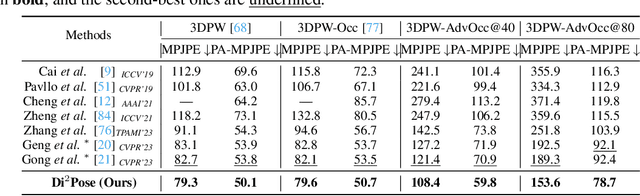
Continuous diffusion models have demonstrated their effectiveness in addressing the inherent uncertainty and indeterminacy in monocular 3D human pose estimation (HPE). Despite their strengths, the need for large search spaces and the corresponding demand for substantial training data make these models prone to generating biomechanically unrealistic poses. This challenge is particularly noticeable in occlusion scenarios, where the complexity of inferring 3D structures from 2D images intensifies. In response to these limitations, we introduce the Discrete Diffusion Pose ($\text{Di}^2\text{Pose}$), a novel framework designed for occluded 3D HPE that capitalizes on the benefits of a discrete diffusion model. Specifically, $\text{Di}^2\text{Pose}$ employs a two-stage process: it first converts 3D poses into a discrete representation through a \emph{pose quantization step}, which is subsequently modeled in latent space through a \emph{discrete diffusion process}. This methodological innovation restrictively confines the search space towards physically viable configurations and enhances the model's capability to comprehend how occlusions affect human pose within the latent space. Extensive evaluations conducted on various benchmarks (e.g., Human3.6M, 3DPW, and 3DPW-Occ) have demonstrated its effectiveness.
Seeing Beyond Classes: Zero-Shot Grounded Situation Recognition via Language Explainer
Apr 24, 2024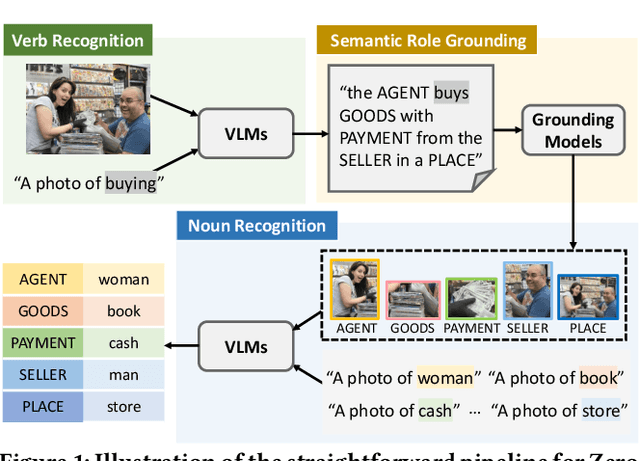

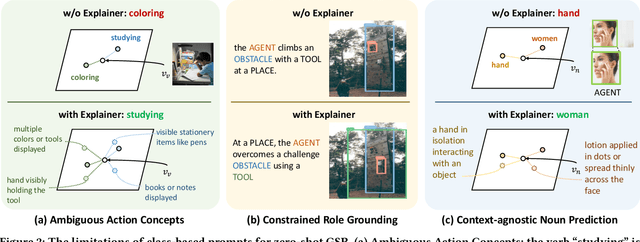
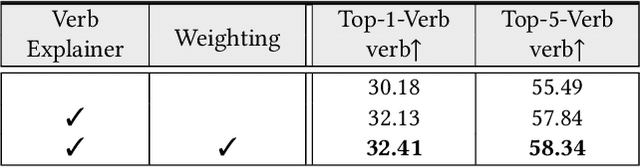
Benefiting from strong generalization ability, pre-trained vision language models (VLMs), e.g., CLIP, have been widely utilized in zero-shot scene understanding. Unlike simple recognition tasks, grounded situation recognition (GSR) requires the model not only to classify salient activity (verb) in the image, but also to detect all semantic roles that participate in the action. This complex task usually involves three steps: verb recognition, semantic role grounding, and noun recognition. Directly employing class-based prompts with VLMs and grounding models for this task suffers from several limitations, e.g., it struggles to distinguish ambiguous verb concepts, accurately localize roles with fixed verb-centric template1 input, and achieve context-aware noun predictions. In this paper, we argue that these limitations stem from the mode's poor understanding of verb/noun classes. To this end, we introduce a new approach for zero-shot GSR via Language EXplainer (LEX), which significantly boosts the model's comprehensive capabilities through three explainers: 1) verb explainer, which generates general verb-centric descriptions to enhance the discriminability of different verb classes; 2) grounding explainer, which rephrases verb-centric templates for clearer understanding, thereby enhancing precise semantic role localization; and 3) noun explainer, which creates scene-specific noun descriptions to ensure context-aware noun recognition. By equipping each step of the GSR process with an auxiliary explainer, LEX facilitates complex scene understanding in real-world scenarios. Our extensive validations on the SWiG dataset demonstrate LEX's effectiveness and interoperability in zero-shot GSR.
Graph-Skeleton: ~1% Nodes are Sufficient to Represent Billion-Scale Graph
Feb 14, 2024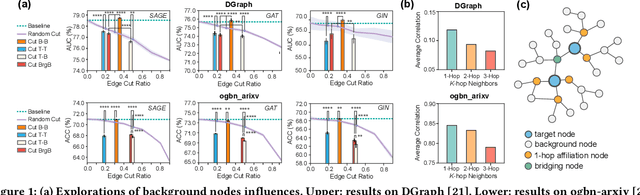
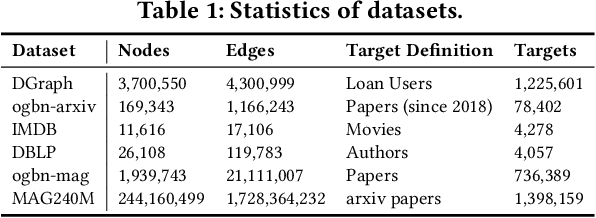
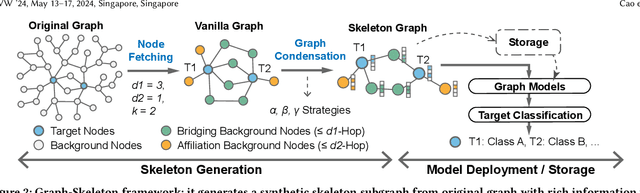
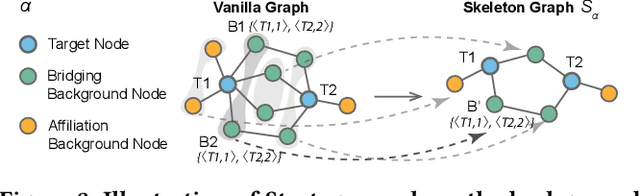
Due to the ubiquity of graph data on the web, web graph mining has become a hot research spot. Nonetheless, the prevalence of large-scale web graphs in real applications poses significant challenges to storage, computational capacity and graph model design. Despite numerous studies to enhance the scalability of graph models, a noticeable gap remains between academic research and practical web graph mining applications. One major cause is that in most industrial scenarios, only a small part of nodes in a web graph are actually required to be analyzed, where we term these nodes as target nodes, while others as background nodes. In this paper, we argue that properly fetching and condensing the background nodes from massive web graph data might be a more economical shortcut to tackle the obstacles fundamentally. To this end, we make the first attempt to study the problem of massive background nodes compression for target nodes classification. Through extensive experiments, we reveal two critical roles played by the background nodes in target node classification: enhancing structural connectivity between target nodes, and feature correlation with target nodes. Followingthis, we propose a novel Graph-Skeleton1 model, which properly fetches the background nodes, and further condenses the semantic and topological information of background nodes within similar target-background local structures. Extensive experiments on various web graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, for MAG240M dataset with 0.24 billion nodes, our generated skeleton graph achieves highly comparable performance while only containing 1.8% nodes of the original graph.
One Graph Model for Cross-domain Dynamic Link Prediction
Feb 03, 2024



This work proposes DyExpert, a dynamic graph model for cross-domain link prediction. It can explicitly model historical evolving processes to learn the evolution pattern of a specific downstream graph and subsequently make pattern-specific link predictions. DyExpert adopts a decode-only transformer and is capable of efficiently parallel training and inference by \textit{conditioned link generation} that integrates both evolution modeling and link prediction. DyExpert is trained by extensive dynamic graphs across diverse domains, comprising 6M dynamic edges. Extensive experiments on eight untrained graphs demonstrate that DyExpert achieves state-of-the-art performance in cross-domain link prediction. Compared to the advanced baseline under the same setting, DyExpert achieves an average of 11.40% improvement Average Precision across eight graphs. More impressive, it surpasses the fully supervised performance of 8 advanced baselines on 6 untrained graphs.