 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Multi-Objective Bandit Algorithms under Preference-Centric Customization
Feb 19, 2025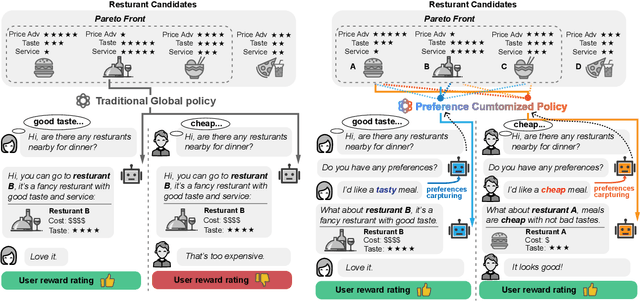
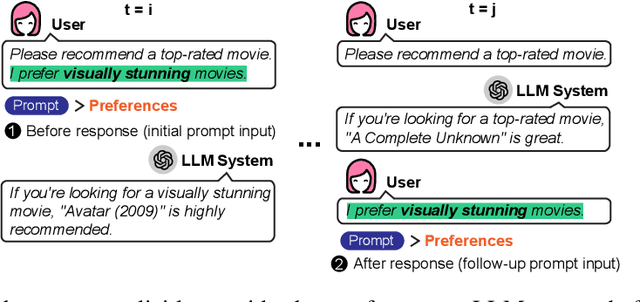
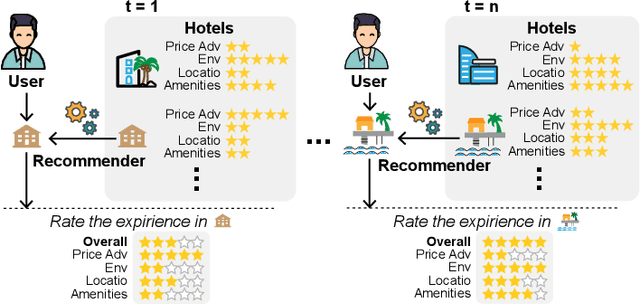
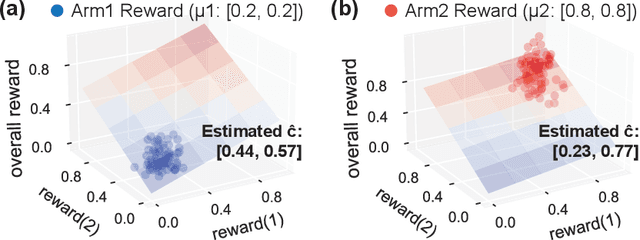
Multi-objective multi-armed bandit (MO-MAB) problems traditionally aim to achieve Pareto optimality. However, real-world scenarios often involve users with varying preferences across objectives, resulting in a Pareto-optimal arm that may score high for one user but perform quite poorly for another. This highlights the need for customized learning, a factor often overlooked in prior research. To address this, we study a preference-aware MO-MAB framework in the presence of explicit user preference. It shifts the focus from achieving Pareto optimality to further optimizing within the Pareto front under preference-centric customization. To our knowledge, this is the first theoretical study of customized MO-MAB optimization with explicit user preferences. Motivated by practical applications, we explore two scenarios: unknown preference and hidden preference, each presenting unique challenges for algorithm design and analysis. At the core of our algorithms are preference estimation and preference-aware optimization mechanisms to adapt to user preferences effectively. We further develop novel analytical techniques to establish near-optimal regret of the proposed algorithms. Strong empirical performance confirm the effectiveness of our approach.
Graph-Skeleton: ~1% Nodes are Sufficient to Represent Billion-Scale Graph
Feb 14, 2024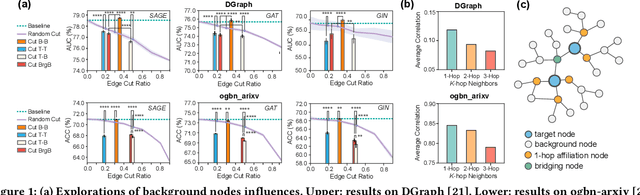
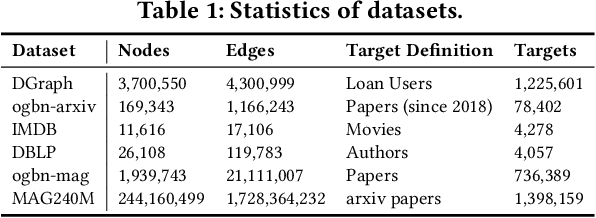
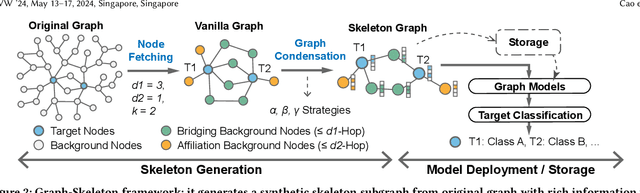
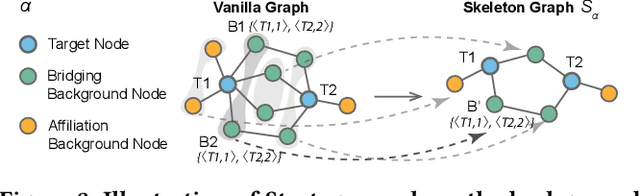
Due to the ubiquity of graph data on the web, web graph mining has become a hot research spot. Nonetheless, the prevalence of large-scale web graphs in real applications poses significant challenges to storage, computational capacity and graph model design. Despite numerous studies to enhance the scalability of graph models, a noticeable gap remains between academic research and practical web graph mining applications. One major cause is that in most industrial scenarios, only a small part of nodes in a web graph are actually required to be analyzed, where we term these nodes as target nodes, while others as background nodes. In this paper, we argue that properly fetching and condensing the background nodes from massive web graph data might be a more economical shortcut to tackle the obstacles fundamentally. To this end, we make the first attempt to study the problem of massive background nodes compression for target nodes classification. Through extensive experiments, we reveal two critical roles played by the background nodes in target node classification: enhancing structural connectivity between target nodes, and feature correlation with target nodes. Followingthis, we propose a novel Graph-Skeleton1 model, which properly fetches the background nodes, and further condenses the semantic and topological information of background nodes within similar target-background local structures. Extensive experiments on various web graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, for MAG240M dataset with 0.24 billion nodes, our generated skeleton graph achieves highly comparable performance while only containing 1.8% nodes of the original graph.