 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree of Preferences for Diversified Recommendation
Dec 24, 2025Diversified recommendation has attracted increasing attention from both researchers and practitioners, which can effectively address the homogeneity of recommended items. Existing approaches predominantly aim to infer the diversity of user preferences from observed user feedback. Nonetheless, due to inherent data biases, the observed data may not fully reflect user interests, where underexplored preferences can be overwhelmed or remain unmanifested. Failing to capture these preferences can lead to suboptimal diversity in recommendations. To fill this gap, this work aims to study diversified recommendation from a data-bias perspective. Inspired by the outstanding performance of large language models (LLMs) in zero-shot inference leveraging world knowledge, we propose a novel approach that utilizes LLMs' expertise to uncover underexplored user preferences from observed behavior, ultimately providing diverse and relevant recommendations. To achieve this, we first introduce Tree of Preferences (ToP), an innovative structure constructed to model user preferences from coarse to fine. ToP enables LLMs to systematically reason over the user's rationale behind their behavior, thereby uncovering their underexplored preferences. To guide diversified recommendations using uncovered preferences, we adopt a data-centric approach, identifying candidate items that match user preferences and generating synthetic interactions that reflect underexplored preferences. These interactions are integrated to train a general recommender for diversification. Moreover, we scale up overall efficiency by dynamically selecting influential users during optimization. Extensive evaluations of both diversity and relevance show that our approach outperforms existing methods in most cases and achieves near-optimal performance in others, with reasonable inference latency.
Can Graph Neural Networks Expose Training Data Properties? An Efficient Risk Assessment Approach
Nov 06, 2024



Graph neural networks (GNNs) have attracted considerable attention due to their diverse applications. However, the scarcity and quality limitations of graph data present challenges to their training process in practical settings. To facilitate the development of effective GNNs, companies and researchers often seek external collaboration. Yet, directly sharing data raises privacy concerns, motivating data owners to train GNNs on their private graphs and share the trained models. Unfortunately, these models may still inadvertently disclose sensitive properties of their training graphs (e.g., average default rate in a transaction network), leading to severe consequences for data owners. In this work, we study graph property inference attack to identify the risk of sensitive property information leakage from shared models. Existing approaches typically train numerous shadow models for developing such attack, which is computationally intensive and impractical. To address this issue, we propose an efficient graph property inference attack by leveraging model approximation techniques. Our method only requires training a small set of models on graphs, while generating a sufficient number of approximated shadow models for attacks. To enhance diversity while reducing errors in the approximated models, we apply edit distance to quantify the diversity within a group of approximated models and introduce a theoretically guaranteed criterion to evaluate each model's error. Subsequently, we propose a novel selection mechanism to ensure that the retained approximated models achieve high diversity and low error. Extensive experiments across six real-world scenarios demonstrate our method's substantial improvement, with average increases of 2.7% in attack accuracy and 4.1% in ROC-AUC, while being 6.5$\times$ faster compared to the best baseline.
Unveiling Privacy Vulnerabilities: Investigating the Role of Structure in Graph Data
Jul 26, 2024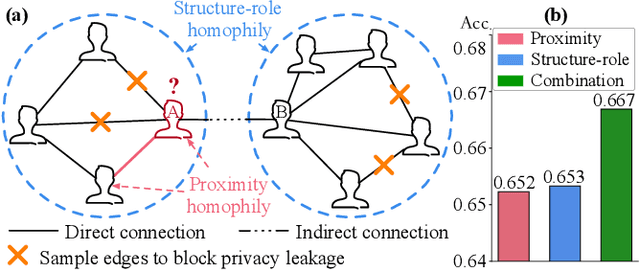
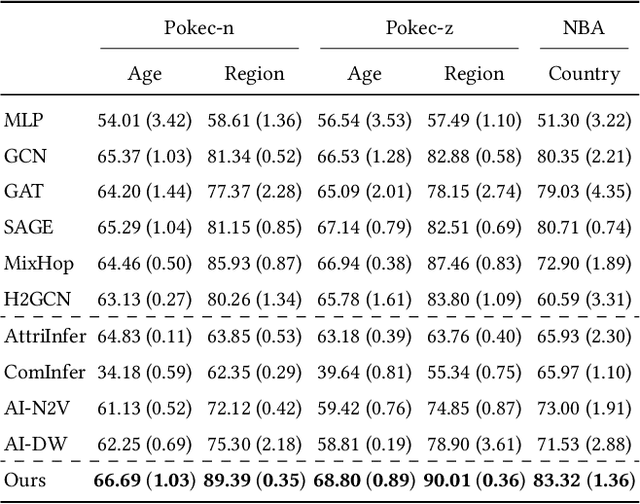
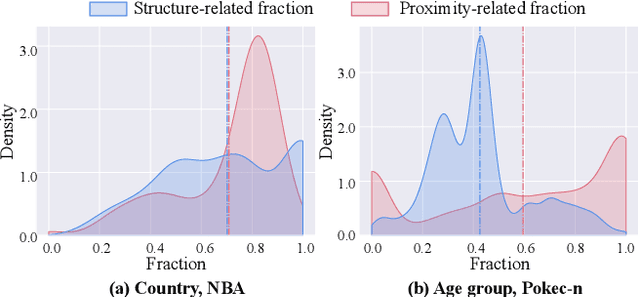
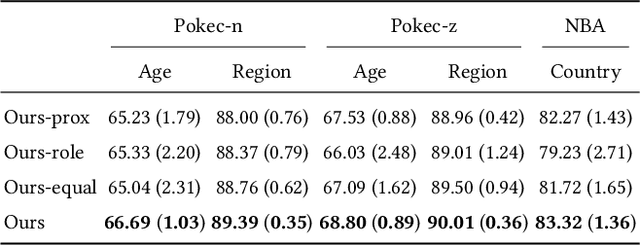
The public sharing of user information opens the door for adversaries to infer private data, leading to privacy breaches and facilitating malicious activities. While numerous studies have concentrated on privacy leakage via public user attributes, the threats associated with the exposure of user relationships, particularly through network structure, are often neglected. This study aims to fill this critical gap by advancing the understanding and protection against privacy risks emanating from network structure, moving beyond direct connections with neighbors to include the broader implications of indirect network structural patterns. To achieve this, we first investigate the problem of Graph Privacy Leakage via Structure (GPS), and introduce a novel measure, the Generalized Homophily Ratio, to quantify the various mechanisms contributing to privacy breach risks in GPS. Based on this insight, we develop a novel graph private attribute inference attack, which acts as a pivotal tool for evaluating the potential for privacy leakage through network structures under worst-case scenarios. To protect users' private data from such vulnerabilities, we propose a graph data publishing method incorporating a learnable graph sampling technique, effectively transforming the original graph into a privacy-preserving version. Extensive experiments demonstrate that our attack model poses a significant threat to user privacy, and our graph data publishing method successfully achieves the optimal privacy-utility trade-off compared to baselines.
Unsupervised Distance Metric Learning for Anomaly Detection Over Multivariate Time Series
Mar 04, 2024
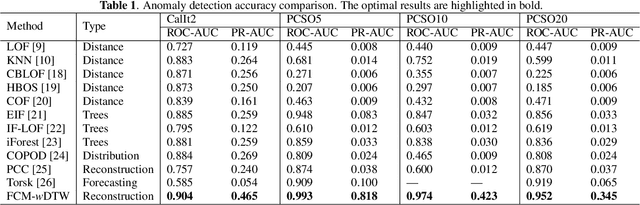

Distance-based time series anomaly detection methods are prevalent due to their relative non-parametric nature and interpretability. However, the commonly used Euclidean distance is sensitive to noise. While existing works have explored dynamic time warping (DTW) for its robustness, they only support supervised tasks over multivariate time series (MTS), leaving a scarcity of unsupervised methods. In this work, we propose FCM-wDTW, an unsupervised distance metric learning method for anomaly detection over MTS, which encodes raw data into latent space and reveals normal dimension relationships through cluster centers. FCM-wDTW introduces locally weighted DTW into fuzzy C-means clustering and learns the optimal latent space efficiently, enabling anomaly identification via data reconstruction. Experiments with 11 different types of benchmarks demonstrate our method's competitive accuracy and efficiency.