 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Beyond Classes: Zero-Shot Grounded Situation Recognition via Language Explainer
Paper and Code
Apr 24, 2024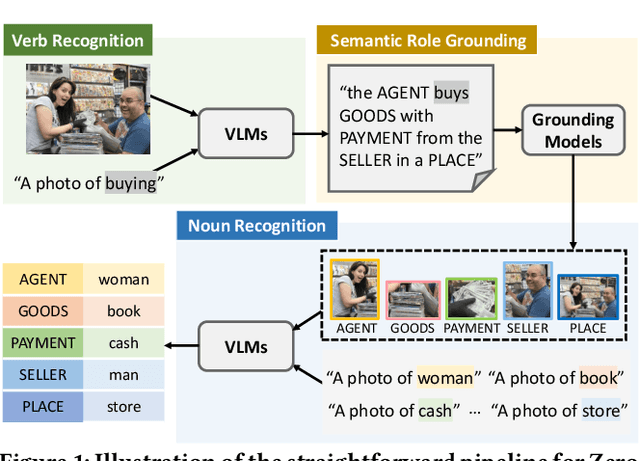

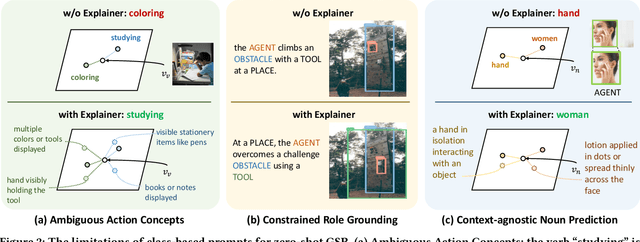
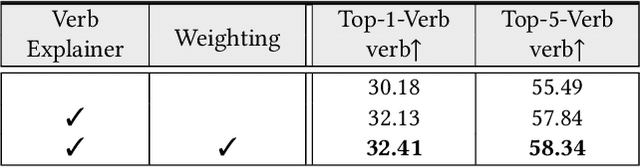
Benefiting from strong generalization ability, pre-trained vision language models (VLMs), e.g., CLIP, have been widely utilized in zero-shot scene understanding. Unlike simple recognition tasks, grounded situation recognition (GSR) requires the model not only to classify salient activity (verb) in the image, but also to detect all semantic roles that participate in the action. This complex task usually involves three steps: verb recognition, semantic role grounding, and noun recognition. Directly employing class-based prompts with VLMs and grounding models for this task suffers from several limitations, e.g., it struggles to distinguish ambiguous verb concepts, accurately localize roles with fixed verb-centric template1 input, and achieve context-aware noun predictions. In this paper, we argue that these limitations stem from the mode's poor understanding of verb/noun classes. To this end, we introduce a new approach for zero-shot GSR via Language EXplainer (LEX), which significantly boosts the model's comprehensive capabilities through three explainers: 1) verb explainer, which generates general verb-centric descriptions to enhance the discriminability of different verb classes; 2) grounding explainer, which rephrases verb-centric templates for clearer understanding, thereby enhancing precise semantic role localization; and 3) noun explainer, which creates scene-specific noun descriptions to ensure context-aware noun recognition. By equipping each step of the GSR process with an auxiliary explainer, LEX facilitates complex scene understanding in real-world scenarios. Our extensive validations on the SWiG dataset demonstrate LEX's effectiveness and interoperability in zero-shot GSR.