 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{H}^2$em: Learning Hierarchical Hyperbolic Embeddings for Compositional Zero-Shot Learning
Dec 23, 2025Compositional zero-shot learning (CZSL) aims to recognize unseen state-object compositions by generalizing from a training set of their primitives (state and object). Current methods often overlook the rich hierarchical structures, such as the semantic hierarchy of primitives (e.g., apple fruit) and the conceptual hierarchy between primitives and compositions (e.g, sliced apple apple). A few recent efforts have shown effectiveness in modeling these hierarchies through loss regularization within Euclidean space. In this paper, we argue that they fail to scale to the large-scale taxonomies required for real-world CZSL: the space's polynomial volume growth in flat geometry cannot match the exponential structure, impairing generalization capacity. To this end, we propose H2em, a new framework that learns Hierarchical Hyperbolic EMbeddings for CZSL. H2em leverages the unique properties of hyperbolic geometry, a space naturally suited for embedding tree-like structures with low distortion. However, a naive hyperbolic mapping may suffer from hierarchical collapse and poor fine-grained discrimination. We further design two learning objectives to structure this space: a Dual-Hierarchical Entailment Loss that uses hyperbolic entailment cones to enforce the predefined hierarchies, and a Discriminative Alignment Loss with hard negative mining to establish a large geodesic distance between semantically similar compositions. Furthermore, we devise Hyperbolic Cross-Modal Attention to realize instance-aware cross-modal infusion within hyperbolic geometry. Extensive ablations on three benchmarks demonstrate that H2em establishes a new state-of-the-art in both closed-world and open-world scenarios. Our codes will be released.
Seeing Beyond Classes: Zero-Shot Grounded Situation Recognition via Language Explainer
Apr 24, 2024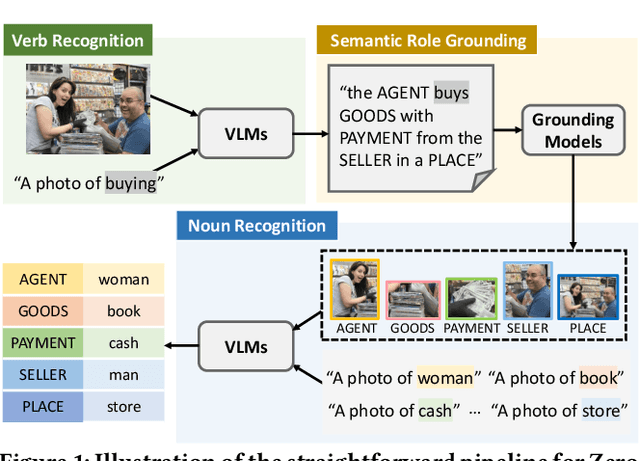

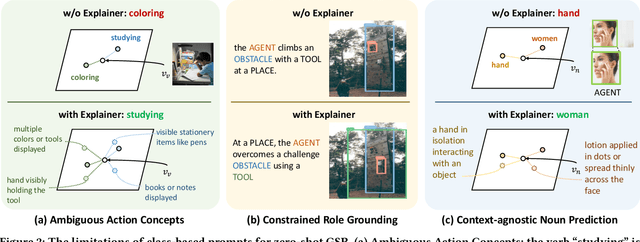
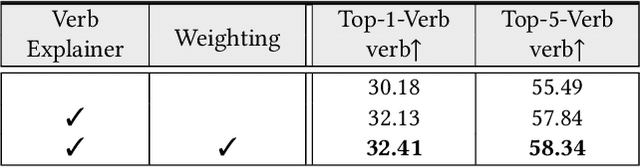
Benefiting from strong generalization ability, pre-trained vision language models (VLMs), e.g., CLIP, have been widely utilized in zero-shot scene understanding. Unlike simple recognition tasks, grounded situation recognition (GSR) requires the model not only to classify salient activity (verb) in the image, but also to detect all semantic roles that participate in the action. This complex task usually involves three steps: verb recognition, semantic role grounding, and noun recognition. Directly employing class-based prompts with VLMs and grounding models for this task suffers from several limitations, e.g., it struggles to distinguish ambiguous verb concepts, accurately localize roles with fixed verb-centric template1 input, and achieve context-aware noun predictions. In this paper, we argue that these limitations stem from the mode's poor understanding of verb/noun classes. To this end, we introduce a new approach for zero-shot GSR via Language EXplainer (LEX), which significantly boosts the model's comprehensive capabilities through three explainers: 1) verb explainer, which generates general verb-centric descriptions to enhance the discriminability of different verb classes; 2) grounding explainer, which rephrases verb-centric templates for clearer understanding, thereby enhancing precise semantic role localization; and 3) noun explainer, which creates scene-specific noun descriptions to ensure context-aware noun recognition. By equipping each step of the GSR process with an auxiliary explainer, LEX facilitates complex scene understanding in real-world scenarios. Our extensive validations on the SWiG dataset demonstrate LEX's effectiveness and interoperability in zero-shot GSR.
DuEqNet: Dual-Equivariance Network in Outdoor 3D Object Detection for Autonomous Driving
Feb 27, 2023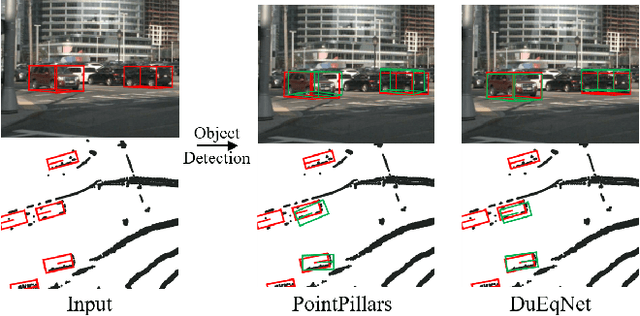
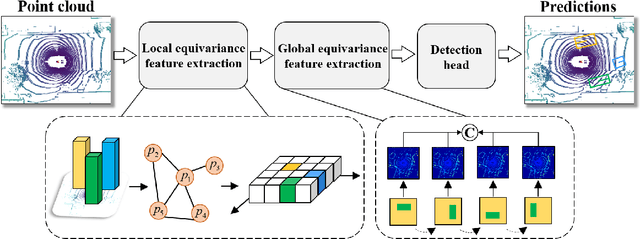
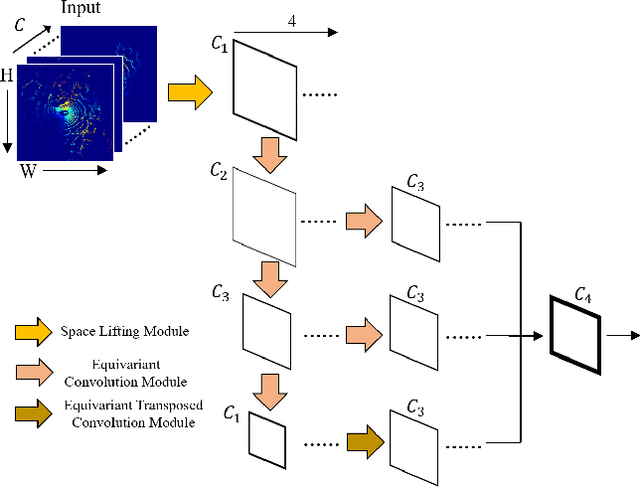
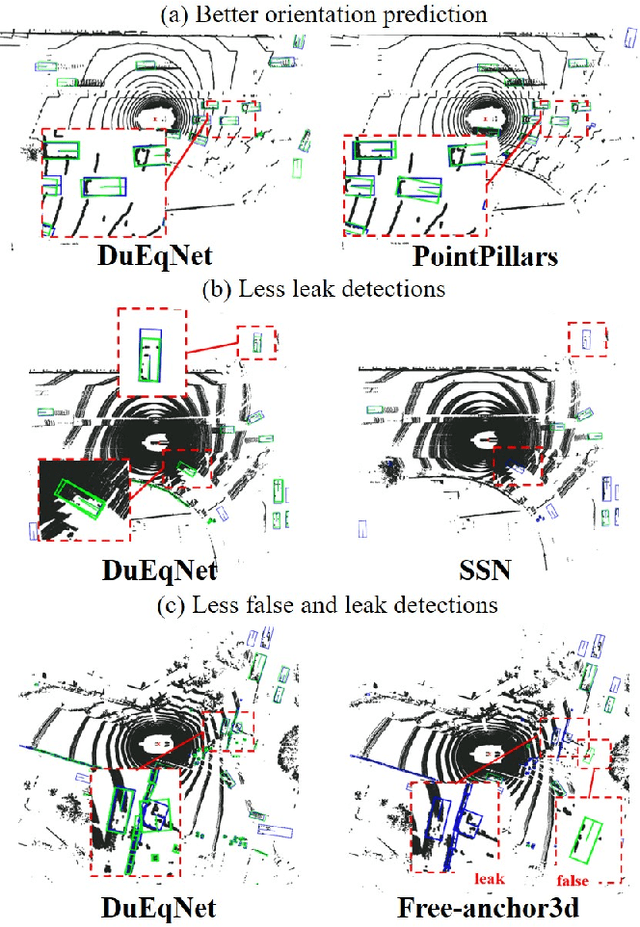
Outdoor 3D object detection has played an essential role in the environment perception of autonomous driving. In complicated traffic situations, precise object recognition provides indispensable information for prediction and planning in the dynamic system, improving self-driving safety and reliability. However, with the vehicle's veering, the constant rotation of the surrounding scenario makes a challenge for the perception systems. Yet most existing methods have not focused on alleviating the detection accuracy impairment brought by the vehicle's rotation, especially in outdoor 3D detection. In this paper, we propose DuEqNet, which first introduces the concept of equivariance into 3D object detection network by leveraging a hierarchical embedded framework. The dual-equivariance of our model can extract the equivariant features at both local and global levels, respectively. For the local feature, we utilize the graph-based strategy to guarantee the equivariance of the feature in point cloud pillars. In terms of the global feature, the group equivariant convolution layers are adopted to aggregate the local feature to achieve the global equivariance. In the experiment part, we evaluate our approach with different baselines in 3D object detection tasks and obtain State-Of-The-Art performance. According to the results, our model presents higher accuracy on orientation and better prediction efficiency. Moreover, our dual-equivariance strategy exhibits the satisfied plug-and-play ability on various popular object detection frameworks to improve their performance.