 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Linguistically-informed Representations for English as a Second or Foreign Language: Review, Construction and Application
Apr 10, 2026The widespread use of English as a Second or Foreign Language (ESFL) has sparked a paradigm shift: ESFL is not seen merely as a deviation from standard English but as a distinct linguistic system in its own right. This shift highlights the need for dedicated, knowledge-intensive representations of ESFL. In response, this paper surveys existing ESFL resources, identifies their limitations, and proposes a novel solution. Grounded in constructivist theories, the paper treats constructions as the fundamental units of analysis, allowing it to model the syntax--semantics interface of both ESFL and standard English. This design captures a wide range of ESFL phenomena by referring to syntactico-semantic mappings of English while preserving ESFL's unique characteristics, resulting a gold-standard syntactico-semantic resource comprising 1643 annotated ESFL sentences. To demonstrate the sembank's practical utility, we conduct a pilot study testing the Linguistic Niche Hypothesis, highlighting its potential as a valuable tool in Second Language Acquisition research.
Attr-Int: A Simple and Effective Entity Alignment Framework for Heterogeneous Knowledge Graphs
Oct 17, 2024
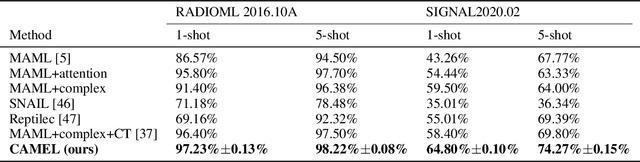

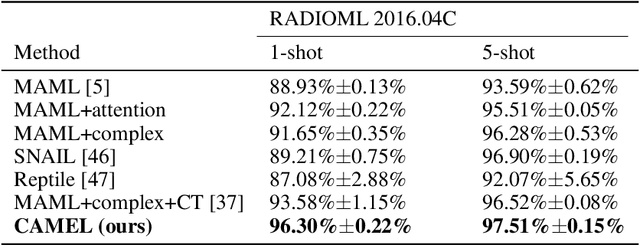
Entity alignment (EA) refers to the task of linking entities in different knowledge graphs (KGs). Existing EA methods rely heavily on structural isomorphism. However, in real-world KGs, aligned entities usually have non-isomorphic neighborhood structures, which paralyses the application of these structure-dependent methods. In this paper, we investigate and tackle the problem of entity alignment between heterogeneous KGs. First, we propose two new benchmarks to closely simulate real-world EA scenarios of heterogeneity. Then we conduct extensive experiments to evaluate the performance of representative EA methods on the new benchmarks. Finally, we propose a simple and effective entity alignment framework called Attr-Int, in which innovative attribute information interaction methods can be seamlessly integrated with any embedding encoder for entity alignment, improving the performance of existing entity alignment techniques. Experiments demonstrate that our framework outperforms the state-of-the-art approaches on two new benchmarks.
DuEqNet: Dual-Equivariance Network in Outdoor 3D Object Detection for Autonomous Driving
Feb 27, 2023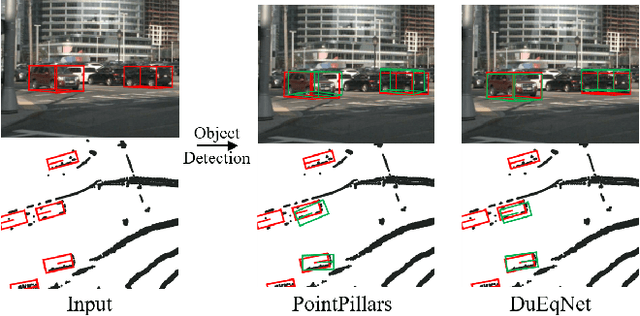
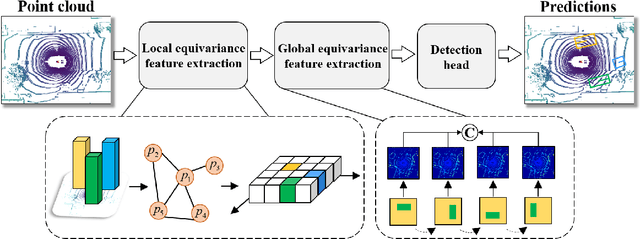
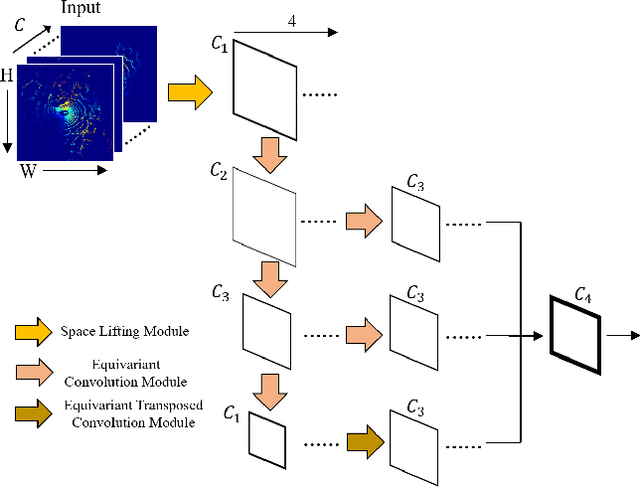
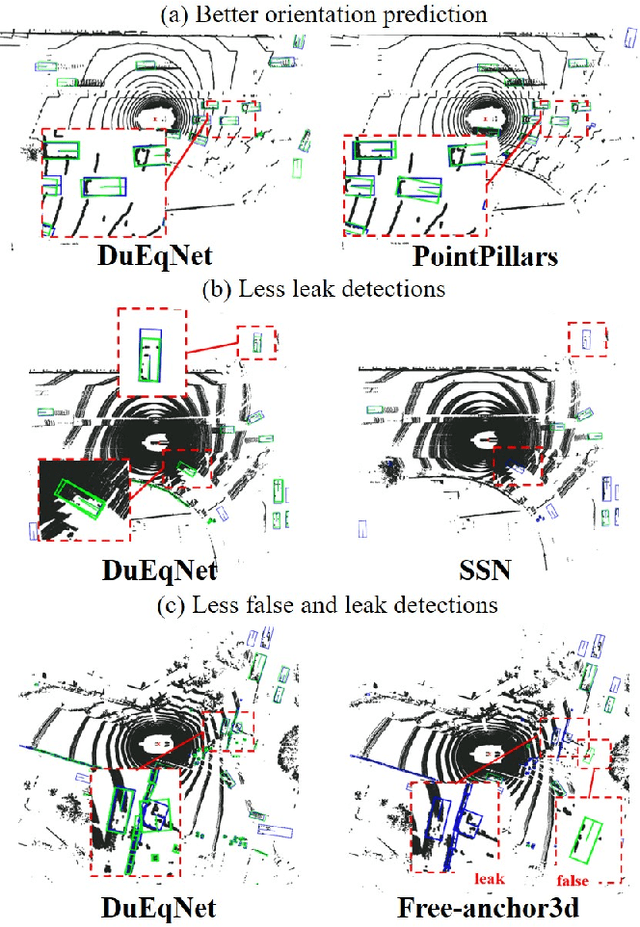
Outdoor 3D object detection has played an essential role in the environment perception of autonomous driving. In complicated traffic situations, precise object recognition provides indispensable information for prediction and planning in the dynamic system, improving self-driving safety and reliability. However, with the vehicle's veering, the constant rotation of the surrounding scenario makes a challenge for the perception systems. Yet most existing methods have not focused on alleviating the detection accuracy impairment brought by the vehicle's rotation, especially in outdoor 3D detection. In this paper, we propose DuEqNet, which first introduces the concept of equivariance into 3D object detection network by leveraging a hierarchical embedded framework. The dual-equivariance of our model can extract the equivariant features at both local and global levels, respectively. For the local feature, we utilize the graph-based strategy to guarantee the equivariance of the feature in point cloud pillars. In terms of the global feature, the group equivariant convolution layers are adopted to aggregate the local feature to achieve the global equivariance. In the experiment part, we evaluate our approach with different baselines in 3D object detection tasks and obtain State-Of-The-Art performance. According to the results, our model presents higher accuracy on orientation and better prediction efficiency. Moreover, our dual-equivariance strategy exhibits the satisfied plug-and-play ability on various popular object detection frameworks to improve their performance.
UnconFuse: Avatar Reconstruction from Unconstrained Images
Nov 18, 2022


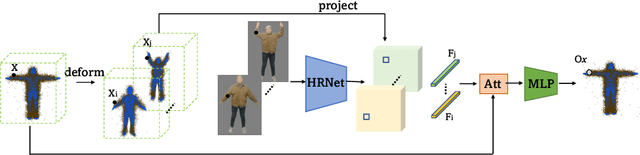
The report proposes an effective solution about 3D human body reconstruction from multiple unconstrained frames for ECCV 2022 WCPA Challenge: From Face, Body and Fashion to 3D Virtual avatars I (track1: Multi-View Based 3D Human Body Reconstruction). We reproduce the reconstruction method presented in MVP-Human as our baseline, and make some improvements for the particularity of this challenge. We finally achieve the score 0.93 on the official testing set, getting the 1st place on the leaderboard.
Hand and Arm Gesture-based Human-Robot Interaction: A Review
Sep 17, 2022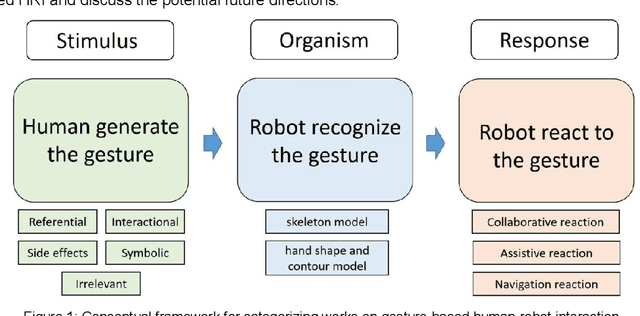
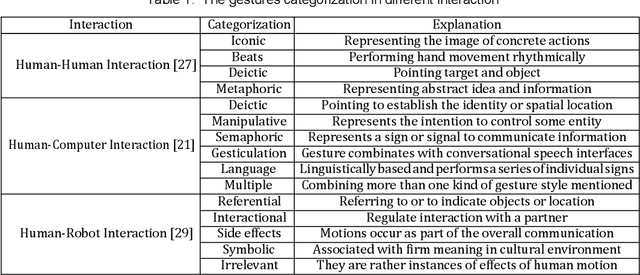
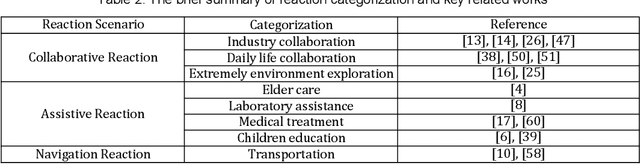
The study of Human-Robot Interaction (HRI) aims to create close and friendly communication between humans and robots. In the human-center HRI, an essential aspect of implementing a successful and effective HRI is building a natural and intuitive interaction, including verbal and nonverbal. As a prevalent nonverbally communication approach, hand and arm gesture communication happen ubiquitously in our daily life. A considerable amount of work on gesture-based HRI is scattered in various research domains. However, a systematic understanding of the works on gesture-based HRI is still lacking. This paper intends to provide a comprehensive review of gesture-based HRI and focus on the advanced finding in this area. Following the stimulus-organism-response framework, this review consists of: (i) Generation of human gesture(stimulus). (ii) Robot recognition of human gesture(organism). (iii) Robot reaction to human gesture(response). Besides, this review summarizes the research status of each element in the framework and analyze the advantages and disadvantages of related works. Toward the last part, this paper discusses the current research challenges on gesture-based HRI and provides possible future directions.
Continual Learning for Pose-Agnostic Object Recognition in 3D Point Clouds
Sep 11, 2022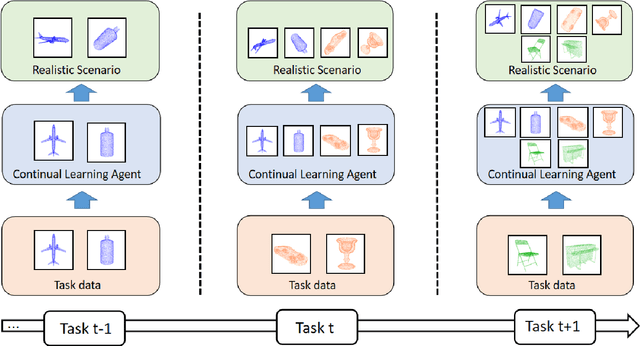
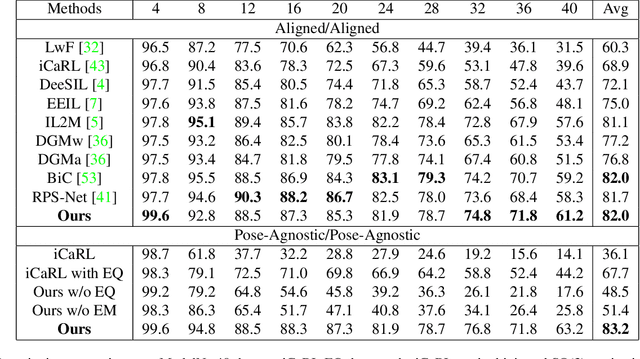
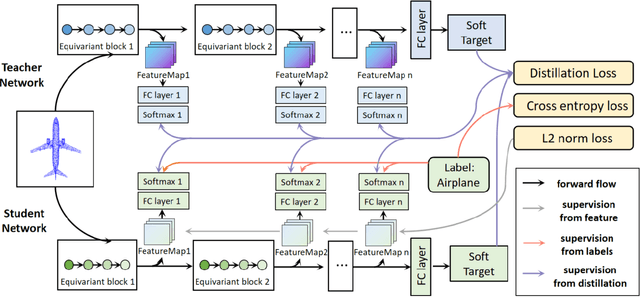
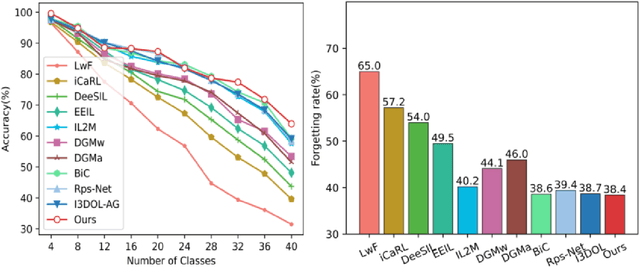
Continual Learning aims to learn multiple incoming new tasks continually, and to keep the performance of learned tasks at a consistent level. However, existing research on continual learning assumes the pose of the object is pre-defined and well-aligned. For practical application, this work focuses on pose-agnostic continual learning tasks, where the object's pose changes dynamically and unpredictably. The point cloud augmentation adopted from past approaches would sharply rise with the task increment in the continual learning process. To address this problem, we inject the equivariance as the additional prior knowledge into the networks. We proposed a novel continual learning model that effectively distillates previous tasks' geometric equivariance information. The experiments show that our method overcomes the challenge of pose-agnostic scenarios in several mainstream point cloud datasets. We further conduct ablation studies to evaluate the validation of each component of our approach.
Synthesizing Tensor Transformations for Visual Self-attention
Jan 05, 2022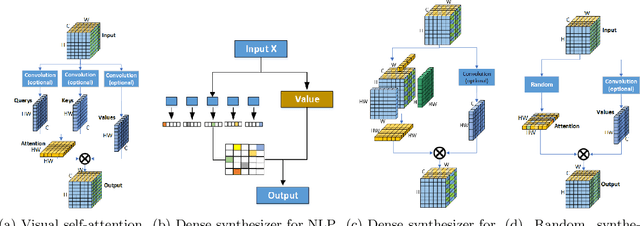
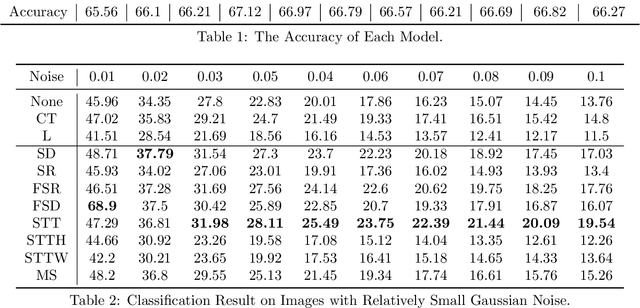
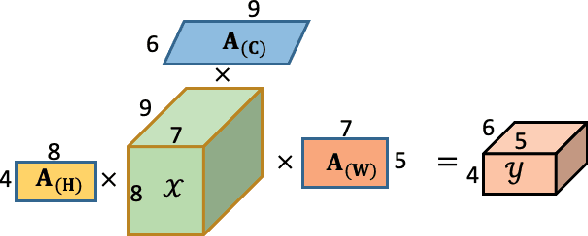
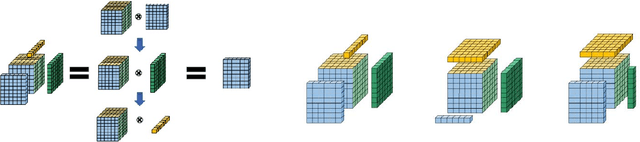
Self-attention shows outstanding competence in capturing long-range relationships while enhancing performance on vision tasks, such as image classification and image captioning. However, the self-attention module highly relies on the dot product multiplication and dimension alignment among query-key-value features, which cause two problems: (1) The dot product multiplication results in exhaustive and redundant computation. (2) Due to the visual feature map often appearing as a multi-dimensional tensor, reshaping the scale of the tensor feature to adapt to the dimension alignment might destroy the internal structure of the tensor feature map. To address these problems, this paper proposes a self-attention plug-in module with its variants, namely, Synthesizing Tensor Transformations (STT), for directly processing image tensor features. Without computing the dot-product multiplication among query-key-value, the basic STT is composed of the tensor transformation to learn the synthetic attention weight from visual information. The effectiveness of STT series is validated on the image classification and image caption. Experiments show that the proposed STT achieves competitive performance while keeping robustness compared to self-attention based above vision tasks.
Couplformer:Rethinking Vision Transformer with Coupling Attention Map
Dec 10, 2021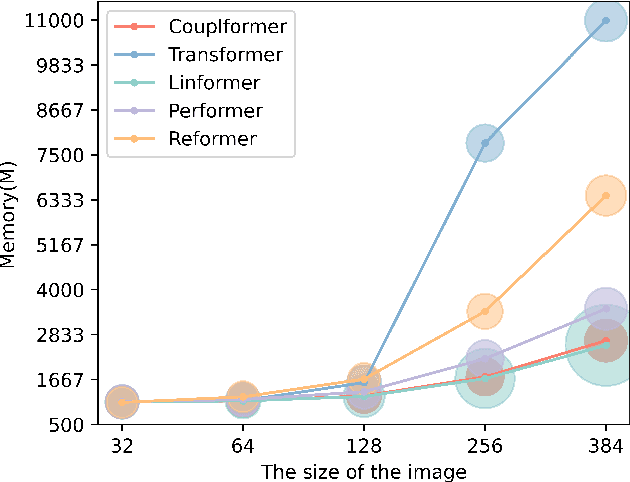

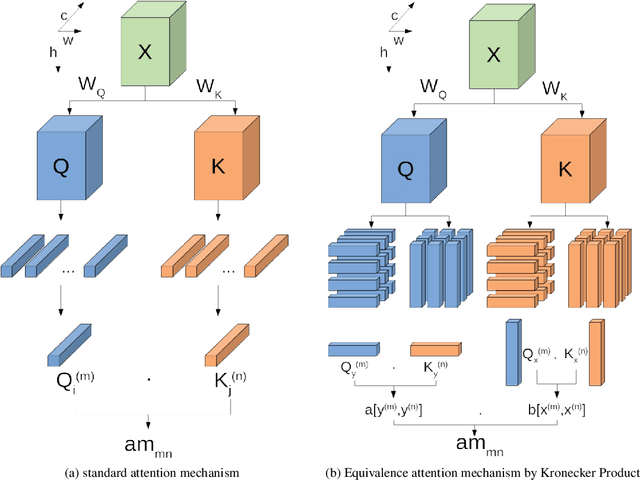
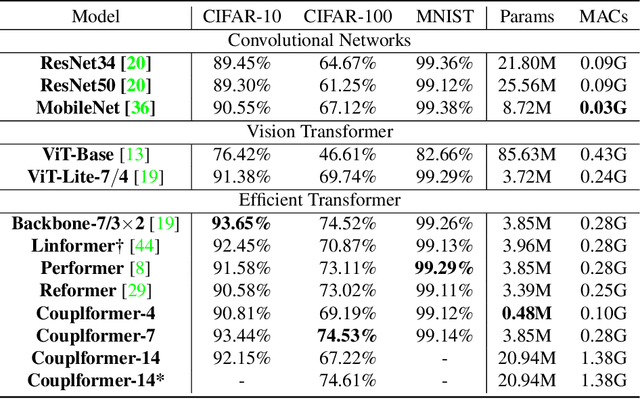
With the development of the self-attention mechanism, the Transformer model has demonstrated its outstanding performance in the computer vision domain. However, the massive computation brought from the full attention mechanism became a heavy burden for memory consumption. Sequentially, the limitation of memory reduces the possibility of improving the Transformer model. To remedy this problem, we propose a novel memory economy attention mechanism named Couplformer, which decouples the attention map into two sub-matrices and generates the alignment scores from spatial information. A series of different scale image classification tasks are applied to evaluate the effectiveness of our model. The result of experiments shows that on the ImageNet-1k classification task, the Couplformer can significantly decrease 28% memory consumption compared with regular Transformer while accessing sufficient accuracy requirements and outperforming 0.92% on Top-1 accuracy while occupying the same memory footprint. As a result, the Couplformer can serve as an efficient backbone in visual tasks, and provide a novel perspective on the attention mechanism for researchers.