 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCouplformer:Rethinking Vision Transformer with Coupling Attention Map
Paper and Code
Dec 10, 2021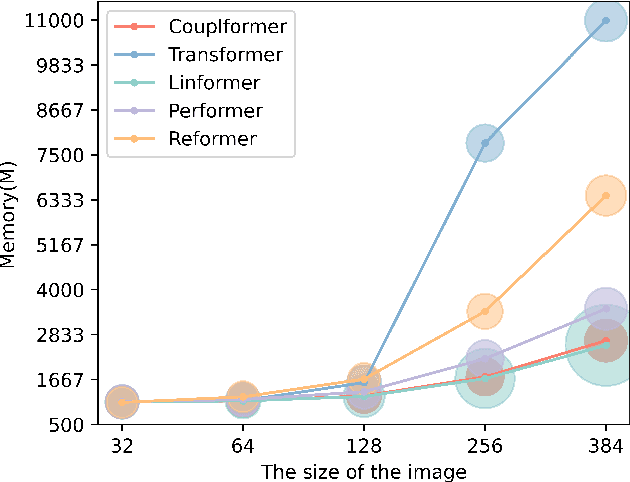

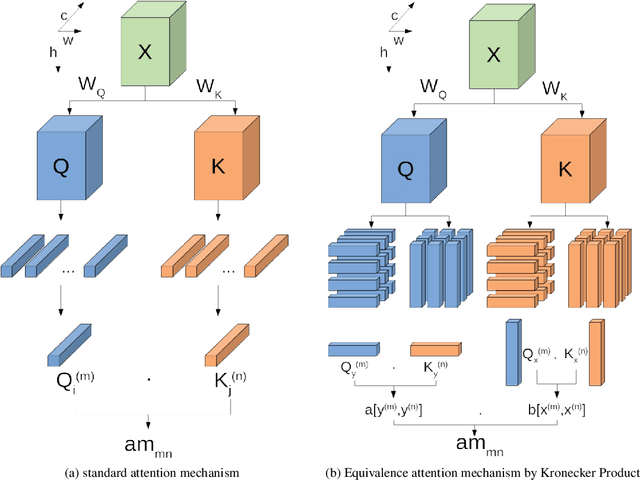
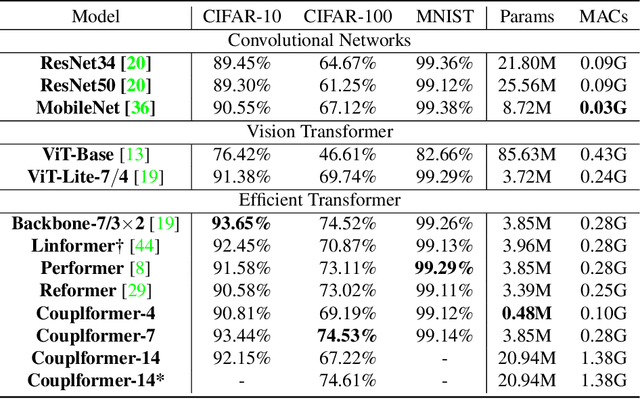
With the development of the self-attention mechanism, the Transformer model has demonstrated its outstanding performance in the computer vision domain. However, the massive computation brought from the full attention mechanism became a heavy burden for memory consumption. Sequentially, the limitation of memory reduces the possibility of improving the Transformer model. To remedy this problem, we propose a novel memory economy attention mechanism named Couplformer, which decouples the attention map into two sub-matrices and generates the alignment scores from spatial information. A series of different scale image classification tasks are applied to evaluate the effectiveness of our model. The result of experiments shows that on the ImageNet-1k classification task, the Couplformer can significantly decrease 28% memory consumption compared with regular Transformer while accessing sufficient accuracy requirements and outperforming 0.92% on Top-1 accuracy while occupying the same memory footprint. As a result, the Couplformer can serve as an efficient backbone in visual tasks, and provide a novel perspective on the attention mechanism for researchers.