 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Geometry-aware Transformer for 3D Point Cloud Classification
Apr 12, 2023Self-attention modules have demonstrated remarkable capabilities in capturing long-range relationships and improving the performance of point cloud tasks. However, point cloud objects are typically characterized by complex, disordered, and non-Euclidean spatial structures with multiple scales, and their behavior is often dynamic and unpredictable. The current self-attention modules mostly rely on dot product multiplication and dimension alignment among query-key-value features, which cannot adequately capture the multi-scale non-Euclidean structures of point cloud objects. To address these problems, this paper proposes a self-attention plug-in module with its variants, Multi-scale Geometry-aware Transformer (MGT). MGT processes point cloud data with multi-scale local and global geometric information in the following three aspects. At first, the MGT divides point cloud data into patches with multiple scales. Secondly, a local feature extractor based on sphere mapping is proposed to explore the geometry inner each patch and generate a fixed-length representation for each patch. Thirdly, the fixed-length representations are fed into a novel geodesic-based self-attention to capture the global non-Euclidean geometry between patches. Finally, all the modules are integrated into the framework of MGT with an end-to-end training scheme. Experimental results demonstrate that the MGT vastly increases the capability of capturing multi-scale geometry using the self-attention mechanism and achieves strong competitive performance on mainstream point cloud benchmarks.
DuEqNet: Dual-Equivariance Network in Outdoor 3D Object Detection for Autonomous Driving
Feb 27, 2023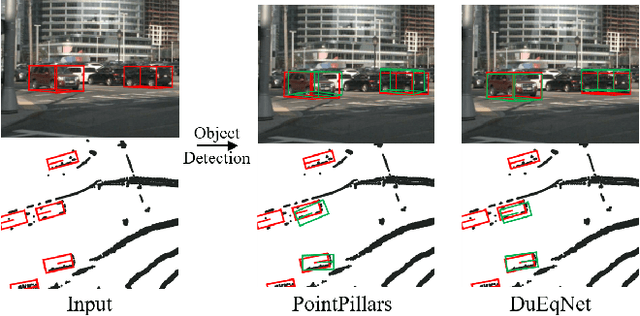
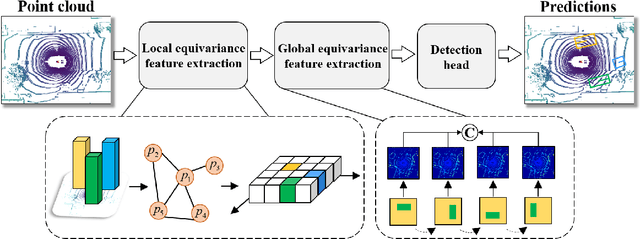
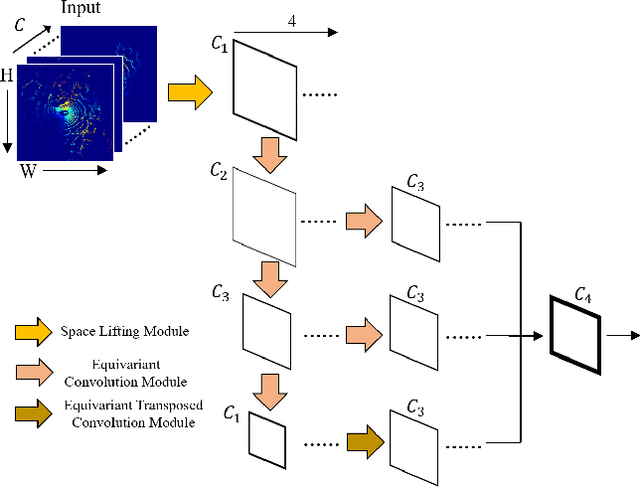
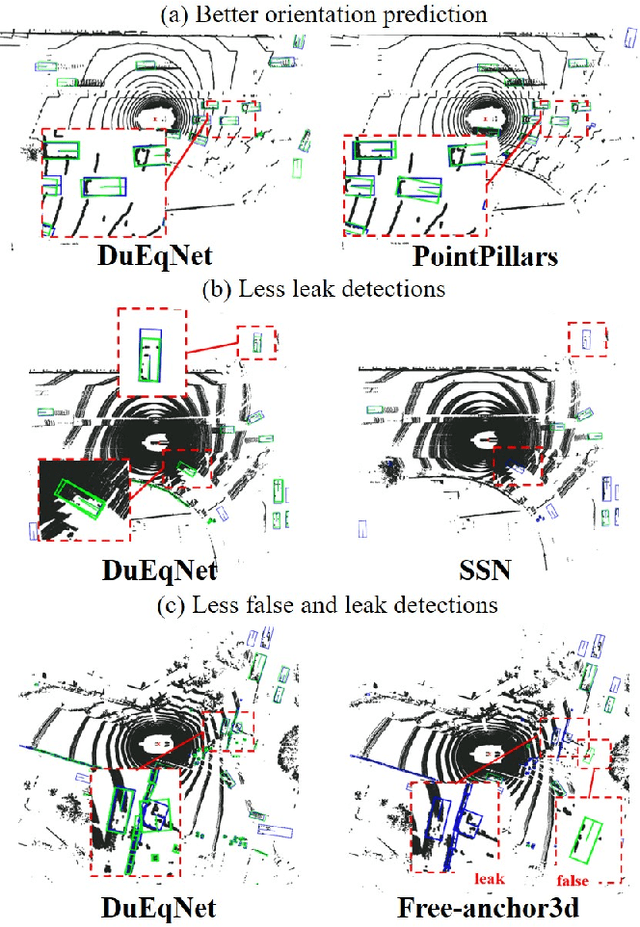
Outdoor 3D object detection has played an essential role in the environment perception of autonomous driving. In complicated traffic situations, precise object recognition provides indispensable information for prediction and planning in the dynamic system, improving self-driving safety and reliability. However, with the vehicle's veering, the constant rotation of the surrounding scenario makes a challenge for the perception systems. Yet most existing methods have not focused on alleviating the detection accuracy impairment brought by the vehicle's rotation, especially in outdoor 3D detection. In this paper, we propose DuEqNet, which first introduces the concept of equivariance into 3D object detection network by leveraging a hierarchical embedded framework. The dual-equivariance of our model can extract the equivariant features at both local and global levels, respectively. For the local feature, we utilize the graph-based strategy to guarantee the equivariance of the feature in point cloud pillars. In terms of the global feature, the group equivariant convolution layers are adopted to aggregate the local feature to achieve the global equivariance. In the experiment part, we evaluate our approach with different baselines in 3D object detection tasks and obtain State-Of-The-Art performance. According to the results, our model presents higher accuracy on orientation and better prediction efficiency. Moreover, our dual-equivariance strategy exhibits the satisfied plug-and-play ability on various popular object detection frameworks to improve their performance.