 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Dec 30, 2025General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.
Act2Goal: From World Model To General Goal-conditioned Policy
Dec 29, 2025Specifying robotic manipulation tasks in a manner that is both expressive and precise remains a central challenge. While visual goals provide a compact and unambiguous task specification, existing goal-conditioned policies often struggle with long-horizon manipulation due to their reliance on single-step action prediction without explicit modeling of task progress. We propose Act2Goal, a general goal-conditioned manipulation policy that integrates a goal-conditioned visual world model with multi-scale temporal control. Given a current observation and a target visual goal, the world model generates a plausible sequence of intermediate visual states that captures long-horizon structure. To translate this visual plan into robust execution, we introduce Multi-Scale Temporal Hashing (MSTH), which decomposes the imagined trajectory into dense proximal frames for fine-grained closed-loop control and sparse distal frames that anchor global task consistency. The policy couples these representations with motor control through end-to-end cross-attention, enabling coherent long-horizon behavior while remaining reactive to local disturbances. Act2Goal achieves strong zero-shot generalization to novel objects, spatial layouts, and environments. We further enable reward-free online adaptation through hindsight goal relabeling with LoRA-based finetuning, allowing rapid autonomous improvement without external supervision. Real-robot experiments demonstrate that Act2Goal improves success rates from 30% to 90% on challenging out-of-distribution tasks within minutes of autonomous interaction, validating that goal-conditioned world models with multi-scale temporal control provide structured guidance necessary for robust long-horizon manipulation. Project page: https://act2goal.github.io/
Real2Edit2Real: Generating Robotic Demonstrations via a 3D Control Interface
Dec 22, 2025Recent progress in robot learning has been driven by large-scale datasets and powerful visuomotor policy architectures, yet policy robustness remains limited by the substantial cost of collecting diverse demonstrations, particularly for spatial generalization in manipulation tasks. To reduce repetitive data collection, we present Real2Edit2Real, a framework that generates new demonstrations by bridging 3D editability with 2D visual data through a 3D control interface. Our approach first reconstructs scene geometry from multi-view RGB observations with a metric-scale 3D reconstruction model. Based on the reconstructed geometry, we perform depth-reliable 3D editing on point clouds to generate new manipulation trajectories while geometrically correcting the robot poses to recover physically consistent depth, which serves as a reliable condition for synthesizing new demonstrations. Finally, we propose a multi-conditional video generation model guided by depth as the primary control signal, together with action, edge, and ray maps, to synthesize spatially augmented multi-view manipulation videos. Experiments on four real-world manipulation tasks demonstrate that policies trained on data generated from only 1-5 source demonstrations can match or outperform those trained on 50 real-world demonstrations, improving data efficiency by up to 10-50x. Moreover, experimental results on height and texture editing demonstrate the framework's flexibility and extensibility, indicating its potential to serve as a unified data generation framework.
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025

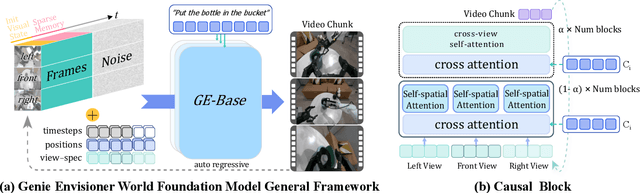
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
EWMBench: Evaluating Scene, Motion, and Semantic Quality in Embodied World Models
May 14, 2025Recent advances in creative AI have enabled the synthesis of high-fidelity images and videos conditioned on language instructions. Building on these developments, text-to-video diffusion models have evolved into embodied world models (EWMs) capable of generating physically plausible scenes from language commands, effectively bridging vision and action in embodied AI applications. This work addresses the critical challenge of evaluating EWMs beyond general perceptual metrics to ensure the generation of physically grounded and action-consistent behaviors. We propose the Embodied World Model Benchmark (EWMBench), a dedicated framework designed to evaluate EWMs based on three key aspects: visual scene consistency, motion correctness, and semantic alignment. Our approach leverages a meticulously curated dataset encompassing diverse scenes and motion patterns, alongside a comprehensive multi-dimensional evaluation toolkit, to assess and compare candidate models. The proposed benchmark not only identifies the limitations of existing video generation models in meeting the unique requirements of embodied tasks but also provides valuable insights to guide future advancements in the field. The dataset and evaluation tools are publicly available at https://github.com/AgibotTech/EWMBench.
EnerVerse-AC: Envisioning Embodied Environments with Action Condition
May 14, 2025Robotic imitation learning has advanced from solving static tasks to addressing dynamic interaction scenarios, but testing and evaluation remain costly and challenging due to the need for real-time interaction with dynamic environments. We propose EnerVerse-AC (EVAC), an action-conditional world model that generates future visual observations based on an agent's predicted actions, enabling realistic and controllable robotic inference. Building on prior architectures, EVAC introduces a multi-level action-conditioning mechanism and ray map encoding for dynamic multi-view image generation while expanding training data with diverse failure trajectories to improve generalization. As both a data engine and evaluator, EVAC augments human-collected trajectories into diverse datasets and generates realistic, action-conditioned video observations for policy testing, eliminating the need for physical robots or complex simulations. This approach significantly reduces costs while maintaining high fidelity in robotic manipulation evaluation. Extensive experiments validate the effectiveness of our method. Code, checkpoints, and datasets can be found at <https://annaj2178.github.io/EnerverseAC.github.io>.
EnerVerse: Envisioning Embodied Future Space for Robotics Manipulation
Jan 03, 2025



We introduce EnerVerse, a comprehensive framework for embodied future space generation specifically designed for robotic manipulation tasks. EnerVerse seamlessly integrates convolutional and bidirectional attention mechanisms for inner-chunk space modeling, ensuring low-level consistency and continuity. Recognizing the inherent redundancy in video data, we propose a sparse memory context combined with a chunkwise unidirectional generative paradigm to enable the generation of infinitely long sequences. To further augment robotic capabilities, we introduce the Free Anchor View (FAV) space, which provides flexible perspectives to enhance observation and analysis. The FAV space mitigates motion modeling ambiguity, removes physical constraints in confined environments, and significantly improves the robot's generalization and adaptability across various tasks and settings. To address the prohibitive costs and labor intensity of acquiring multi-camera observations, we present a data engine pipeline that integrates a generative model with 4D Gaussian Splatting (4DGS). This pipeline leverages the generative model's robust generalization capabilities and the spatial constraints provided by 4DGS, enabling an iterative enhancement of data quality and diversity, thus creating a data flywheel effect that effectively narrows the sim-to-real gap. Finally, our experiments demonstrate that the embodied future space generation prior substantially enhances policy predictive capabilities, resulting in improved overall performance, particularly in long-range robotic manipulation tasks.
UnconFuse: Avatar Reconstruction from Unconstrained Images
Nov 18, 2022


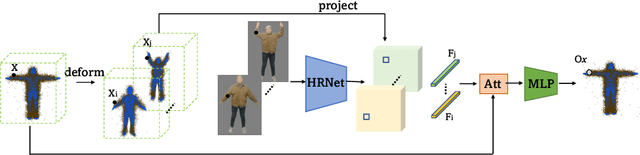
The report proposes an effective solution about 3D human body reconstruction from multiple unconstrained frames for ECCV 2022 WCPA Challenge: From Face, Body and Fashion to 3D Virtual avatars I (track1: Multi-View Based 3D Human Body Reconstruction). We reproduce the reconstruction method presented in MVP-Human as our baseline, and make some improvements for the particularity of this challenge. We finally achieve the score 0.93 on the official testing set, getting the 1st place on the leaderboard.
CrossHuman: Learning Cross-Guidance from Multi-Frame Images for Human Reconstruction
Jul 20, 2022
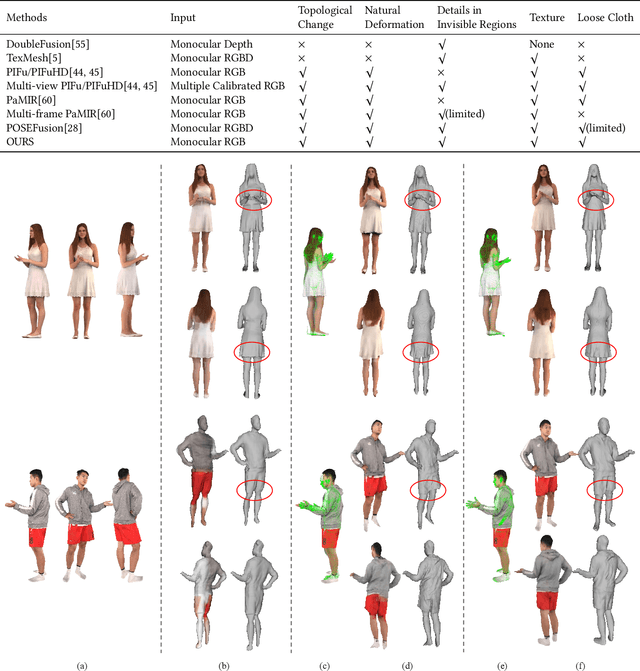
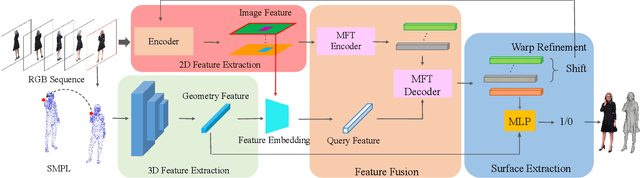
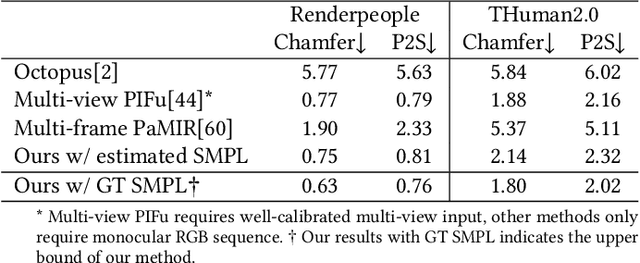
We propose CrossHuman, a novel method that learns cross-guidance from parametric human model and multi-frame RGB images to achieve high-quality 3D human reconstruction. To recover geometry details and texture even in invisible regions, we design a reconstruction pipeline combined with tracking-based methods and tracking-free methods. Given a monocular RGB sequence, we track the parametric human model in the whole sequence, the points (voxels) corresponding to the target frame are warped to reference frames by the parametric body motion. Guided by the geometry priors of the parametric body and spatially aligned features from RGB sequence, the robust implicit surface is fused. Moreover, a multi-frame transformer (MFT) and a self-supervised warp refinement module are integrated to the framework to relax the requirements of parametric body and help to deal with very loose cloth. Compared with previous works, our CrossHuman enables high-fidelity geometry details and texture in both visible and invisible regions and improves the accuracy of the human reconstruction even under estimated inaccurate parametric human models. The experiments demonstrate that our method achieves state-of-the-art (SOTA) performance.