 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossHuman: Learning Cross-Guidance from Multi-Frame Images for Human Reconstruction
Paper and Code
Jul 20, 2022
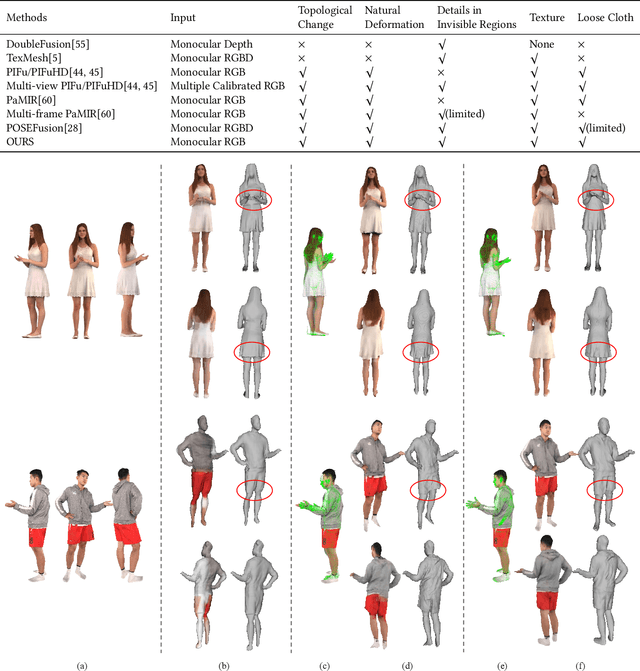
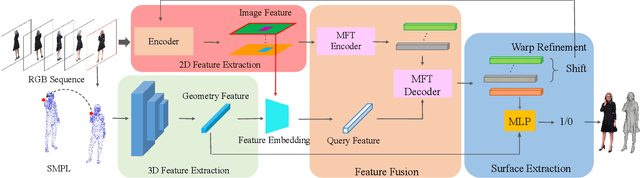
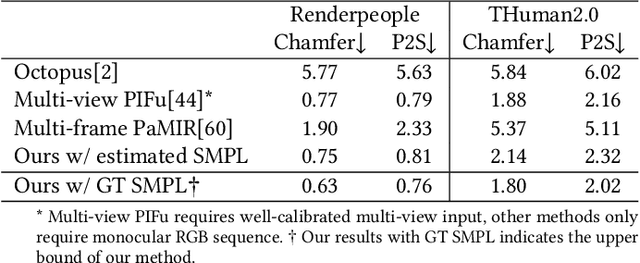
We propose CrossHuman, a novel method that learns cross-guidance from parametric human model and multi-frame RGB images to achieve high-quality 3D human reconstruction. To recover geometry details and texture even in invisible regions, we design a reconstruction pipeline combined with tracking-based methods and tracking-free methods. Given a monocular RGB sequence, we track the parametric human model in the whole sequence, the points (voxels) corresponding to the target frame are warped to reference frames by the parametric body motion. Guided by the geometry priors of the parametric body and spatially aligned features from RGB sequence, the robust implicit surface is fused. Moreover, a multi-frame transformer (MFT) and a self-supervised warp refinement module are integrated to the framework to relax the requirements of parametric body and help to deal with very loose cloth. Compared with previous works, our CrossHuman enables high-fidelity geometry details and texture in both visible and invisible regions and improves the accuracy of the human reconstruction even under estimated inaccurate parametric human models. The experiments demonstrate that our method achieves state-of-the-art (SOTA) performance.