 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
Jan 16, 2026Vision-Language-Action (VLA) models have emerged as essential generalist robot policies for diverse manipulation tasks, conventionally relying on directly translating multimodal inputs into actions via Vision-Language Model (VLM) embeddings. Recent advancements have introduced explicit intermediary reasoning, such as sub-task prediction (language) or goal image synthesis (vision), to guide action generation. However, these intermediate reasoning are often indirect and inherently limited in their capacity to convey the full, granular information required for precise action execution. Instead, we posit that the most effective form of reasoning is one that deliberates directly in the action space. We introduce Action Chain-of-Thought (ACoT), a paradigm where the reasoning process itself is formulated as a structured sequence of coarse action intents that guide the final policy. In this paper, we propose ACoT-VLA, a novel architecture that materializes the ACoT paradigm. Specifically, we introduce two complementary components: an Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR). The former proposes coarse reference trajectories as explicit action-level reasoning steps, while the latter extracts latent action priors from internal representations of multimodal input, co-forming an ACoT that conditions the downstream action head to enable grounded policy learning. Extensive experiments in real-world and simulation environments demonstrate the superiority of our proposed method, which achieves 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus and VLABench, respectively.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Jan 05, 2026The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a large language model (LLM)-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-Language Model (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Dec 30, 2025General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.
FieldGen: From Teleoperated Pre-Manipulation Trajectories to Field-Guided Data Generation
Oct 23, 2025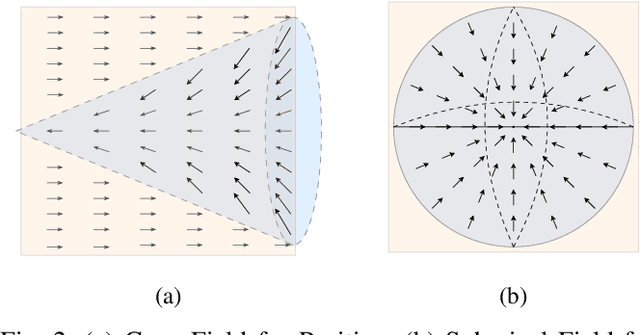

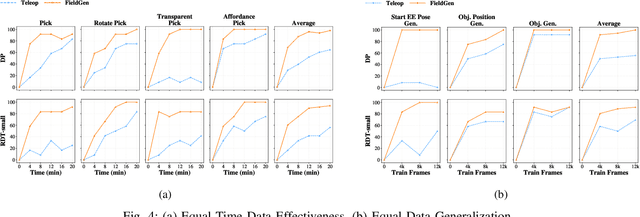

Large-scale and diverse datasets are vital for training robust robotic manipulation policies, yet existing data collection methods struggle to balance scale, diversity, and quality. Simulation offers scalability but suffers from sim-to-real gaps, while teleoperation yields high-quality demonstrations with limited diversity and high labor cost. We introduce FieldGen, a field-guided data generation framework that enables scalable, diverse, and high-quality real-world data collection with minimal human supervision. FieldGen decomposes manipulation into two stages: a pre-manipulation phase, allowing trajectory diversity, and a fine manipulation phase requiring expert precision. Human demonstrations capture key contact and pose information, after which an attraction field automatically generates diverse trajectories converging to successful configurations. This decoupled design combines scalable trajectory diversity with precise supervision. Moreover, FieldGen-Reward augments generated data with reward annotations to further enhance policy learning. Experiments demonstrate that policies trained with FieldGen achieve higher success rates and improved stability compared to teleoperation-based baselines, while significantly reducing human effort in long-term real-world data collection. Webpage is available at https://fieldgen.github.io/.
EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
Aug 28, 2025The human ability to seamlessly perform multimodal reasoning and physical interaction in the open world is a core goal for general-purpose embodied intelligent systems. Recent vision-language-action (VLA) models, which are co-trained on large-scale robot and visual-text data, have demonstrated notable progress in general robot control. However, they still fail to achieve human-level flexibility in interleaved reasoning and interaction. In this work, introduce EO-Robotics, consists of EO-1 model and EO-Data1.5M dataset. EO-1 is a unified embodied foundation model that achieves superior performance in multimodal embodied reasoning and robot control through interleaved vision-text-action pre-training. The development of EO-1 is based on two key pillars: (i) a unified architecture that processes multimodal inputs indiscriminately (image, text, video, and action), and (ii) a massive, high-quality multimodal embodied reasoning dataset, EO-Data1.5M, which contains over 1.5 million samples with emphasis on interleaved vision-text-action comprehension. EO-1 is trained through synergies between auto-regressive decoding and flow matching denoising on EO-Data1.5M, enabling seamless robot action generation and multimodal embodied reasoning. Extensive experiments demonstrate the effectiveness of interleaved vision-text-action learning for open-world understanding and generalization, validated through a variety of long-horizon, dexterous manipulation tasks across multiple embodiments. This paper details the architecture of EO-1, the data construction strategy of EO-Data1.5M, and the training methodology, offering valuable insights for developing advanced embodied foundation models.
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Aug 07, 2025

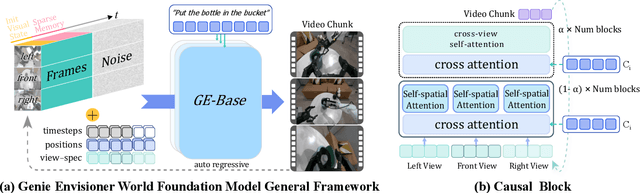
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.
Is Diversity All You Need for Scalable Robotic Manipulation?
Jul 08, 2025Data scaling has driven remarkable success in foundation models for Natural Language Processing (NLP) and Computer Vision (CV), yet the principles of effective data scaling in robotic manipulation remain insufficiently understood. In this work, we investigate the nuanced role of data diversity in robot learning by examining three critical dimensions-task (what to do), embodiment (which robot to use), and expert (who demonstrates)-challenging the conventional intuition of "more diverse is better". Throughout extensive experiments on various robot platforms, we reveal that (1) task diversity proves more critical than per-task demonstration quantity, benefiting transfer from diverse pre-training tasks to novel downstream scenarios; (2) multi-embodiment pre-training data is optional for cross-embodiment transfer-models trained on high-quality single-embodiment data can efficiently transfer to different platforms, showing more desirable scaling property during fine-tuning than multi-embodiment pre-trained models; and (3) expert diversity, arising from individual operational preferences and stochastic variations in human demonstrations, can be confounding to policy learning, with velocity multimodality emerging as a key contributing factor. Based on this insight, we propose a distribution debiasing method to mitigate velocity ambiguity, the yielding GO-1-Pro achieves substantial performance gains of 15%, equivalent to using 2.5 times pre-training data. Collectively, these findings provide new perspectives and offer practical guidance on how to scale robotic manipulation datasets effectively.
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
May 29, 2025


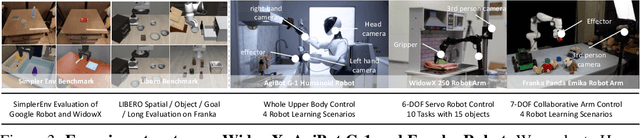
Humans practice slow thinking before performing actual actions when handling complex tasks in the physical world. This thinking paradigm, recently, has achieved remarkable advancement in boosting Large Language Models (LLMs) to solve complex tasks in digital domains. However, the potential of slow thinking remains largely unexplored for robotic foundation models interacting with the physical world. In this work, we propose Hume: a dual-system Vision-Language-Action (VLA) model with value-guided System-2 thinking and cascaded action denoising, exploring human-like thinking capabilities of Vision-Language-Action models for dexterous robot control. System 2 of Hume implements value-Guided thinking by extending a Vision-Language-Action Model backbone with a novel value-query head to estimate the state-action value of predicted actions. The value-guided thinking is conducted by repeat sampling multiple action candidates and selecting one according to state-action value. System 1 of Hume is a lightweight reactive visuomotor policy that takes System 2 selected action and performs cascaded action denoising for dexterous robot control. At deployment time, System 2 performs value-guided thinking at a low frequency while System 1 asynchronously receives the System 2 selected action candidate and predicts fluid actions in real time. We show that Hume outperforms the existing state-of-the-art Vision-Language-Action models across multiple simulation benchmark and real-robot deployments.
Genie Centurion: Accelerating Scalable Real-World Robot Training with Human Rewind-and-Refine Guidance
May 24, 2025



While Vision-Language-Action (VLA) models show strong generalizability in various tasks, real-world deployment of robotic policy still requires large-scale, high-quality human expert demonstrations. However, passive data collection via human teleoperation is costly, hard to scale, and often biased toward passive demonstrations with limited diversity. To address this, we propose Genie Centurion (GCENT), a scalable and general data collection paradigm based on human rewind-and-refine guidance. When the robot execution failures occur, GCENT enables the system revert to a previous state with a rewind mechanism, after which a teleoperator provides corrective demonstrations to refine the policy. This framework supports a one-human-to-many-robots supervision scheme with a Task Sentinel module, which autonomously predicts task success and solicits human intervention when necessary, enabling scalable supervision. Empirical results show that GCENT achieves up to 40% higher task success rates than state-of-the-art data collection methods, and reaches comparable performance using less than half the data. We also quantify the data yield-to-effort ratio under multi-robot scenarios, demonstrating GCENT's potential for scalable and cost-efficient robot policy training in real-world environments.
Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)
May 22, 2025Reinforcement Learning (RL) can mitigate the causal confusion and distribution shift inherent to imitation learning (IL). However, applying RL to end-to-end autonomous driving (E2E-AD) remains an open problem for its training difficulty, and IL is still the mainstream paradigm in both academia and industry. Recently Model-based Reinforcement Learning (MBRL) have demonstrated promising results in neural planning; however, these methods typically require privileged information as input rather than raw sensor data. We fill this gap by designing Raw2Drive, a dual-stream MBRL approach. Initially, we efficiently train an auxiliary privileged world model paired with a neural planner that uses privileged information as input. Subsequently, we introduce a raw sensor world model trained via our proposed Guidance Mechanism, which ensures consistency between the raw sensor world model and the privileged world model during rollouts. Finally, the raw sensor world model combines the prior knowledge embedded in the heads of the privileged world model to effectively guide the training of the raw sensor policy. Raw2Drive is so far the only RL based end-to-end method on CARLA Leaderboard 2.0, and Bench2Drive and it achieves state-of-the-art performance.