 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidedVLA: Specifying Task-Relevant Factors via Plug-and-Play Action Attention Specialization
May 12, 2026Vision-Language-Action (VLA) models aim for general robot learning by aligning action as a modality within powerful Vision-Language Models (VLMs). Existing VLAs rely on end-to-end supervision to implicitly enable the action decoding process to learn task-relevant features. However, without explicit guidance, these models often overfit to spurious correlations, such as visual shortcuts or environmental noise, limiting their generalization. In this paper, we introduce GuidedVLA, a framework designed to manually guide the action generation to focus on task-relevant factors. Our core insight is to treat the action decoder not as a monolithic learner, but as an assembly of functional components. Individual attention heads are supervised by manually defined auxiliary signals to capture distinct factors. As an initial study, we instantiate this paradigm with three specialized heads: object grounding, spatial geometry, and temporal skill logic. Across simulation and real-robot experiments, GuidedVLA improves success rates in both in-domain and out-of-domain settings compared to strong VLA baselines. Finally, we show that the quality of these specialized factors correlates positively with task performance and that our mechanism yields decoupled, high-quality features. Our results suggest that explicitly guiding action-decoder learning is a promising direction for building more robust and general VLA models.
Seeing Farther and Smarter: Value-Guided Multi-Path Reflection for VLM Policy Optimization
Feb 22, 2026Solving complex, long-horizon robotic manipulation tasks requires a deep understanding of physical interactions, reasoning about their long-term consequences, and precise high-level planning. Vision-Language Models (VLMs) offer a general perceive-reason-act framework for this goal. However, previous approaches using reflective planning to guide VLMs in correcting actions encounter significant limitations. These methods rely on inefficient and often inaccurate implicit learning of state-values from noisy foresight predictions, evaluate only a single greedy future, and suffer from substantial inference latency. To address these limitations, we propose a novel test-time computation framework that decouples state evaluation from action generation. This provides a more direct and fine-grained supervisory signal for robust decision-making. Our method explicitly models the advantage of an action plan, quantified by its reduction in distance to the goal, and uses a scalable critic to estimate. To address the stochastic nature of single-trajectory evaluation, we employ beam search to explore multiple future paths and aggregate them during decoding to model their expected long-term returns, leading to more robust action generation. Additionally, we introduce a lightweight, confidence-based trigger that allows for early exit when direct predictions are reliable, invoking reflection only when necessary. Extensive experiments on diverse, unseen multi-stage robotic manipulation tasks demonstrate a 24.6% improvement in success rate over state-of-the-art baselines, while significantly reducing inference time by 56.5%.
$χ_{0}$: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
Feb 09, 2026High-reliability long-horizon robotic manipulation has traditionally relied on large-scale data and compute to understand complex real-world dynamics. However, we identify that the primary bottleneck to real-world robustness is not resource scale alone, but the distributional shift among the human demonstration distribution, the inductive bias learned by the policy, and the test-time execution distribution -- a systematic inconsistency that causes compounding errors in multi-stage tasks. To mitigate these inconsistencies, we propose $χ_{0}$, a resource-efficient framework with effective modules designated to achieve production-level robustness in robotic manipulation. Our approach builds off three technical pillars: (i) Model Arithmetic, a weight-space merging strategy that efficiently soaks up diverse distributions of different demonstrations, varying from object appearance to state variations; (ii) Stage Advantage, a stage-aware advantage estimator that provides stable, dense progress signals, overcoming the numerical instability of prior non-stage approaches; and (iii) Train-Deploy Alignment, which bridges the distribution gap via spatio-temporal augmentation, heuristic DAgger corrections, and temporal chunk-wise smoothing. $χ_{0}$ enables two sets of dual-arm robots to collaboratively orchestrate long-horizon garment manipulation, spanning tasks from flattening, folding, to hanging different clothes. Our method exhibits high-reliability autonomy; we are able to run the system from arbitrary initial state for consecutive 24 hours non-stop. Experiments validate that $χ_{0}$ surpasses the state-of-the-art $π_{0.5}$ in success rate by nearly 250%, with only 20-hour data and 8 A100 GPUs. Code, data and models will be released to facilitate the community.
WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control
Dec 15, 2025Humanoid robots require precise locomotion and dexterous manipulation to perform challenging loco-manipulation tasks. Yet existing approaches, modular or end-to-end, are deficient in manipulation-aware locomotion. This confines the robot to a limited workspace, preventing it from performing large-space loco-manipulation. We attribute this to: (1) the challenge of acquiring loco-manipulation knowledge due to the scarcity of humanoid teleoperation data, and (2) the difficulty of faithfully and reliably executing locomotion commands, stemming from the limited precision and stability of existing RL controllers. To acquire richer loco-manipulation knowledge, we propose a unified latent learning framework that enables Vision-Language-Action (VLA) system to learn from low-cost action-free egocentric videos. Moreover, an efficient human data collection pipeline is devised to augment the dataset and scale the benefits. To execute the desired locomotion commands more precisely, we present a loco-manipulation-oriented (LMO) RL policy specifically tailored for accurate and stable core loco-manipulation movements, such as advancing, turning, and squatting. Building on these components, we introduce WholeBodyVLA, a unified framework for humanoid loco-manipulation. To the best of our knowledge, WholeBodyVLA is one of its kind enabling large-space humanoid loco-manipulation. It is verified via comprehensive experiments on the AgiBot X2 humanoid, outperforming prior baseline by 21.3%. It also demonstrates strong generalization and high extensibility across a broad range of tasks.
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
May 09, 2025A generalist robot should perform effectively across various environments. However, most existing approaches heavily rely on scaling action-annotated data to enhance their capabilities. Consequently, they are often limited to single physical specification and struggle to learn transferable knowledge across different embodiments and environments. To confront these limitations, we propose UniVLA, a new framework for learning cross-embodiment vision-language-action (VLA) policies. Our key innovation is to derive task-centric action representations from videos with a latent action model. This enables us to exploit extensive data across a wide spectrum of embodiments and perspectives. To mitigate the effect of task-irrelevant dynamics, we incorporate language instructions and establish a latent action model within the DINO feature space. Learned from internet-scale videos, the generalist policy can be deployed to various robots through efficient latent action decoding. We obtain state-of-the-art results across multiple manipulation and navigation benchmarks, as well as real-robot deployments. UniVLA achieves superior performance over OpenVLA with less than 1/20 of pretraining compute and 1/10 of downstream data. Continuous performance improvements are observed as heterogeneous data, even including human videos, are incorporated into the training pipeline. The results underscore UniVLA's potential to facilitate scalable and efficient robot policy learning.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Towards Synergistic, Generalized, and Efficient Dual-System for Robotic Manipulation
Oct 10, 2024

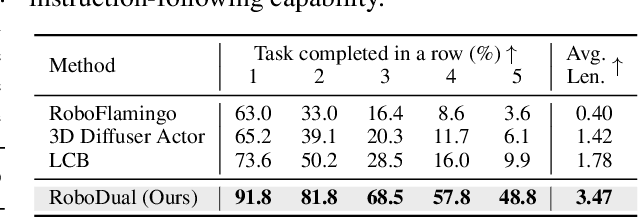

The increasing demand for versatile robotic systems to operate in diverse and dynamic environments has emphasized the importance of a generalist policy, which leverages a large cross-embodiment data corpus to facilitate broad adaptability and high-level reasoning. However, the generalist would struggle with inefficient inference and cost-expensive training. The specialist policy, instead, is curated for specific domain data and excels at task-level precision with efficiency. Yet, it lacks the generalization capacity for a wide range of applications. Inspired by these observations, we introduce RoboDual, a synergistic dual-system that supplements the merits of both generalist and specialist policy. A diffusion transformer-based specialist is devised for multi-step action rollouts, exquisitely conditioned on the high-level task understanding and discretized action output of a vision-language-action (VLA) based generalist. Compared to OpenVLA, RoboDual achieves 26.7% improvement in real-world setting and 12% gain on CALVIN by introducing a specialist policy with merely 20M trainable parameters. It maintains strong performance with 5% of demonstration data only, and enables a 3.8 times higher control frequency in real-world deployment. Code would be made publicly available. Our project page is hosted at: https://opendrivelab.com/RoboDual/
Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulation
Sep 13, 2024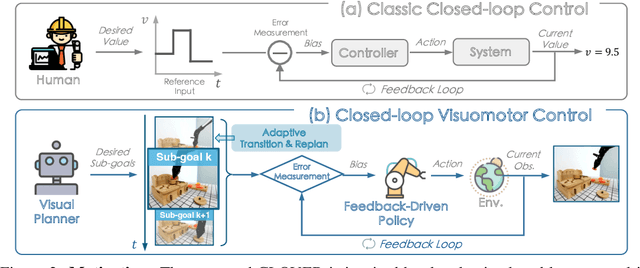
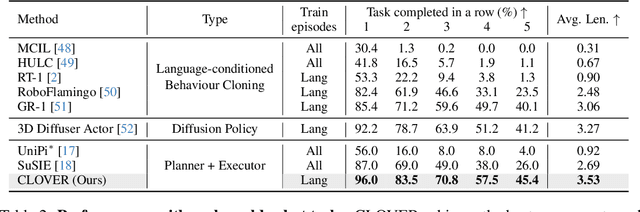
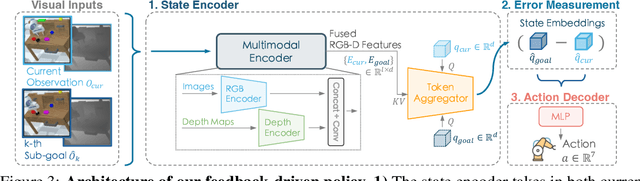
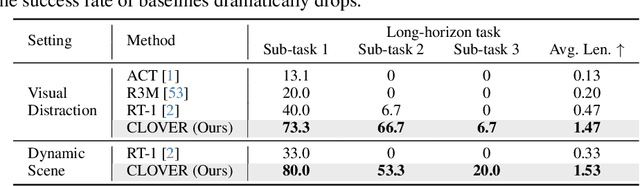
Despite significant progress in robotics and embodied AI in recent years, deploying robots for long-horizon tasks remains a great challenge. Majority of prior arts adhere to an open-loop philosophy and lack real-time feedback, leading to error accumulation and undesirable robustness. A handful of approaches have endeavored to establish feedback mechanisms leveraging pixel-level differences or pre-trained visual representations, yet their efficacy and adaptability have been found to be constrained. Inspired by classic closed-loop control systems, we propose CLOVER, a closed-loop visuomotor control framework that incorporates feedback mechanisms to improve adaptive robotic control. CLOVER consists of a text-conditioned video diffusion model for generating visual plans as reference inputs, a measurable embedding space for accurate error quantification, and a feedback-driven controller that refines actions from feedback and initiates replans as needed. Our framework exhibits notable advancement in real-world robotic tasks and achieves state-of-the-art on CALVIN benchmark, improving by 8% over previous open-loop counterparts. Code and checkpoints are maintained at https://github.com/OpenDriveLab/CLOVER.
Learning Manipulation by Predicting Interaction
Jun 01, 2024



Representation learning approaches for robotic manipulation have boomed in recent years. Due to the scarcity of in-domain robot data, prevailing methodologies tend to leverage large-scale human video datasets to extract generalizable features for visuomotor policy learning. Despite the progress achieved, prior endeavors disregard the interactive dynamics that capture behavior patterns and physical interaction during the manipulation process, resulting in an inadequate understanding of the relationship between objects and the environment. To this end, we propose a general pre-training pipeline that learns Manipulation by Predicting the Interaction (MPI) and enhances the visual representation.Given a pair of keyframes representing the initial and final states, along with language instructions, our algorithm predicts the transition frame and detects the interaction object, respectively. These two learning objectives achieve superior comprehension towards "how-to-interact" and "where-to-interact". We conduct a comprehensive evaluation of several challenging robotic tasks.The experimental results demonstrate that MPI exhibits remarkable improvement by 10% to 64% compared with previous state-of-the-art in real-world robot platforms as well as simulation environments. Code and checkpoints are publicly shared at https://github.com/OpenDriveLab/MPI.
Embodied Understanding of Driving Scenarios
Mar 07, 2024
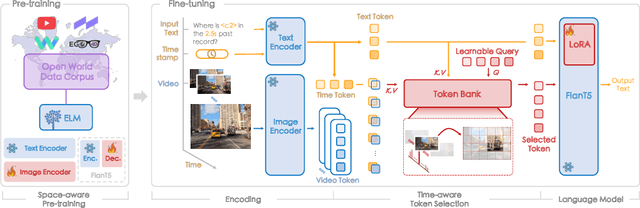
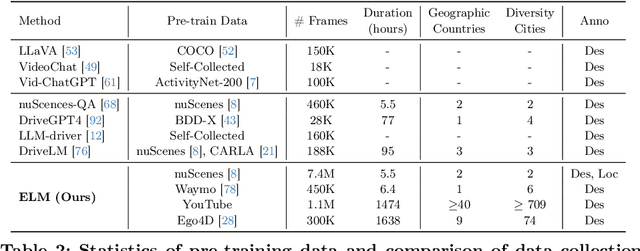
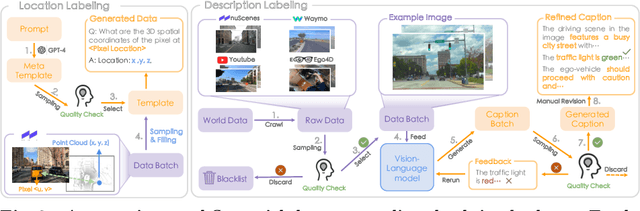
Embodied scene understanding serves as the cornerstone for autonomous agents to perceive, interpret, and respond to open driving scenarios. Such understanding is typically founded upon Vision-Language Models (VLMs). Nevertheless, existing VLMs are restricted to the 2D domain, devoid of spatial awareness and long-horizon extrapolation proficiencies. We revisit the key aspects of autonomous driving and formulate appropriate rubrics. Hereby, we introduce the Embodied Language Model (ELM), a comprehensive framework tailored for agents' understanding of driving scenes with large spatial and temporal spans. ELM incorporates space-aware pre-training to endow the agent with robust spatial localization capabilities. Besides, the model employs time-aware token selection to accurately inquire about temporal cues. We instantiate ELM on the reformulated multi-faced benchmark, and it surpasses previous state-of-the-art approaches in all aspects. All code, data, and models will be publicly shared.