 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxed Triangle Inequality for Kullback-Leibler Divergence Between Multivariate Gaussian Distributions
Jan 31, 2026The Kullback-Leibler (KL) divergence is not a proper distance metric and does not satisfy the triangle inequality, posing theoretical challenges in certain practical applications. Existing work has demonstrated that KL divergence between multivariate Gaussian distributions follows a relaxed triangle inequality. Given any three multivariate Gaussian distributions $\mathcal{N}_1, \mathcal{N}_2$, and $\mathcal{N}_3$, if $KL(\mathcal{N}_1, \mathcal{N}_2)\leq ε_1$ and $KL(\mathcal{N}_2, \mathcal{N}_3)\leq ε_2$, then $KL(\mathcal{N}_1, \mathcal{N}_3)< 3ε_1+3ε_2+2\sqrt{ε_1ε_2}+o(ε_1)+o(ε_2)$. However, the supremum of $KL(\mathcal{N}_1, \mathcal{N}_3)$ is still unknown. In this paper, we investigate the relaxed triangle inequality for the KL divergence between multivariate Gaussian distributions and give the supremum of $KL(\mathcal{N}_1, \mathcal{N}_3)$ as well as the conditions when the supremum can be attained. When $ε_1$ and $ε_2$ are small, the supremum is $ε_1+ε_2+\sqrt{ε_1ε_2}+o(ε_1)+o(ε_2)$. Finally, we demonstrate several applications of our results in out-of-distribution detection with flow-based generative models and safe reinforcement learning.
AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models
Nov 18, 2025



Vision-language-action (VLA) models have recently emerged as a powerful paradigm for building generalist robots. However, traditional VLA models that generate actions through flow matching (FM) typically rely on rigid and uniform time schedules, i.e., synchronous FM (SFM). Without action context awareness and asynchronous self-correction, SFM becomes unstable in long-horizon tasks, where a single action error can cascade into failure. In this work, we propose asynchronous flow matching VLA (AsyncVLA), a novel framework that introduces temporal flexibility in asynchronous FM (AFM) and enables self-correction in action generation. AsyncVLA breaks from the vanilla SFM in VLA models by generating the action tokens in a non-uniform time schedule with action context awareness. Besides, our method introduces the confidence rater to extract confidence of the initially generated actions, enabling the model to selectively refine inaccurate action tokens before execution. Moreover, we propose a unified training procedure for SFM and AFM that endows a single model with both modes, improving KV-cache utilization. Extensive experiments on robotic manipulation benchmarks demonstrate that AsyncVLA is data-efficient and exhibits self-correction ability. AsyncVLA achieves state-of-the-art results across general embodied evaluations due to its asynchronous generation in AFM. Our code is available at https://github.com/YuhuaJiang2002/AsyncVLA.
LLM-GROP: Visually Grounded Robot Task and Motion Planning with Large Language Models
Nov 11, 2025Task planning and motion planning are two of the most important problems in robotics, where task planning methods help robots achieve high-level goals and motion planning methods maintain low-level feasibility. Task and motion planning (TAMP) methods interleave the two processes of task planning and motion planning to ensure goal achievement and motion feasibility. Within the TAMP context, we are concerned with the mobile manipulation (MoMa) of multiple objects, where it is necessary to interleave actions for navigation and manipulation. In particular, we aim to compute where and how each object should be placed given underspecified goals, such as ``set up dinner table with a fork, knife and plate.'' We leverage the rich common sense knowledge from large language models (LLMs), e.g., about how tableware is organized, to facilitate both task-level and motion-level planning. In addition, we use computer vision methods to learn a strategy for selecting base positions to facilitate MoMa behaviors, where the base position corresponds to the robot's ``footprint'' and orientation in its operating space. Altogether, this article provides a principled TAMP framework for MoMa tasks that accounts for common sense about object rearrangement and is adaptive to novel situations that include many objects that need to be moved. We performed quantitative experiments in both real-world settings and simulated environments. We evaluated the success rate and efficiency in completing long-horizon object rearrangement tasks. While the robot completed 84.4\% real-world object rearrangement trials, subjective human evaluations indicated that the robot's performance is still lower than experienced human waiters.
FastUMI-100K: Advancing Data-driven Robotic Manipulation with a Large-scale UMI-style Dataset
Oct 09, 2025Data-driven robotic manipulation learning depends on large-scale, high-quality expert demonstration datasets. However, existing datasets, which primarily rely on human teleoperated robot collection, are limited in terms of scalability, trajectory smoothness, and applicability across different robotic embodiments in real-world environments. In this paper, we present FastUMI-100K, a large-scale UMI-style multimodal demonstration dataset, designed to overcome these limitations and meet the growing complexity of real-world manipulation tasks. Collected by FastUMI, a novel robotic system featuring a modular, hardware-decoupled mechanical design and an integrated lightweight tracking system, FastUMI-100K offers a more scalable, flexible, and adaptable solution to fulfill the diverse requirements of real-world robot demonstration data. Specifically, FastUMI-100K contains over 100K+ demonstration trajectories collected across representative household environments, covering 54 tasks and hundreds of object types. Our dataset integrates multimodal streams, including end-effector states, multi-view wrist-mounted fisheye images and textual annotations. Each trajectory has a length ranging from 120 to 500 frames. Experimental results demonstrate that FastUMI-100K enables high policy success rates across various baseline algorithms, confirming its robustness, adaptability, and real-world applicability for solving complex, dynamic manipulation challenges. The source code and dataset will be released in this link https://github.com/MrKeee/FastUMI-100K.
Cross from Left to Right Brain: Adaptive Text Dreamer for Vision-and-Language Navigation
May 27, 2025Vision-and-Language Navigation (VLN) requires the agent to navigate by following natural instructions under partial observability, making it difficult to align perception with language. Recent methods mitigate this by imagining future scenes, yet they rely on vision-based synthesis, leading to high computational cost and redundant details. To this end, we propose to adaptively imagine key environmental semantics via \textit{language} form, enabling a more reliable and efficient strategy. Specifically, we introduce a novel Adaptive Text Dreamer (ATD), a dual-branch self-guided imagination policy built upon a large language model (LLM). ATD is designed with a human-like left-right brain architecture, where the left brain focuses on logical integration, and the right brain is responsible for imaginative prediction of future scenes. To achieve this, we fine-tune only the Q-former within both brains to efficiently activate domain-specific knowledge in the LLM, enabling dynamic updates of logical reasoning and imagination during navigation. Furthermore, we introduce a cross-interaction mechanism to regularize the imagined outputs and inject them into a navigation expert module, allowing ATD to jointly exploit both the reasoning capacity of the LLM and the expertise of the navigation model. We conduct extensive experiments on the R2R benchmark, where ATD achieves state-of-the-art performance with fewer parameters. The code is \href{https://github.com/zhangpingrui/Adaptive-Text-Dreamer}{here}.
Think Small, Act Big: Primitive Prompt Learning for Lifelong Robot Manipulation
Apr 01, 2025Building a lifelong robot that can effectively leverage prior knowledge for continuous skill acquisition remains significantly challenging. Despite the success of experience replay and parameter-efficient methods in alleviating catastrophic forgetting problem, naively applying these methods causes a failure to leverage the shared primitives between skills. To tackle these issues, we propose Primitive Prompt Learning (PPL), to achieve lifelong robot manipulation via reusable and extensible primitives. Within our two stage learning scheme, we first learn a set of primitive prompts to represent shared primitives through multi-skills pre-training stage, where motion-aware prompts are learned to capture semantic and motion shared primitives across different skills. Secondly, when acquiring new skills in lifelong span, new prompts are appended and optimized with frozen pretrained prompts, boosting the learning via knowledge transfer from old skills to new ones. For evaluation, we construct a large-scale skill dataset and conduct extensive experiments in both simulation and real-world tasks, demonstrating PPL's superior performance over state-of-the-art methods.
MoMa-Kitchen: A 100K+ Benchmark for Affordance-Grounded Last-Mile Navigation in Mobile Manipulation
Mar 14, 2025In mobile manipulation, navigation and manipulation are often treated as separate problems, resulting in a significant gap between merely approaching an object and engaging with it effectively. Many navigation approaches primarily define success by proximity to the target, often overlooking the necessity for optimal positioning that facilitates subsequent manipulation. To address this, we introduce MoMa-Kitchen, a benchmark dataset comprising over 100k samples that provide training data for models to learn optimal final navigation positions for seamless transition to manipulation. Our dataset includes affordance-grounded floor labels collected from diverse kitchen environments, in which robotic mobile manipulators of different models attempt to grasp target objects amidst clutter. Using a fully automated pipeline, we simulate diverse real-world scenarios and generate affordance labels for optimal manipulation positions. Visual data are collected from RGB-D inputs captured by a first-person view camera mounted on the robotic arm, ensuring consistency in viewpoint during data collection. We also develop a lightweight baseline model, NavAff, for navigation affordance grounding that demonstrates promising performance on the MoMa-Kitchen benchmark. Our approach enables models to learn affordance-based final positioning that accommodates different arm types and platform heights, thereby paving the way for more robust and generalizable integration of navigation and manipulation in embodied AI. Project page: \href{https://momakitchen.github.io/}{https://momakitchen.github.io/}.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Unlocking a New Rust Programming Experience: Fast and Slow Thinking with LLMs to Conquer Undefined Behaviors
Mar 04, 2025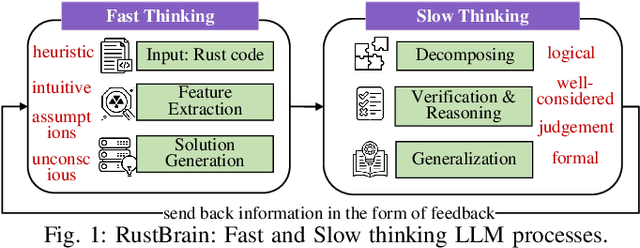
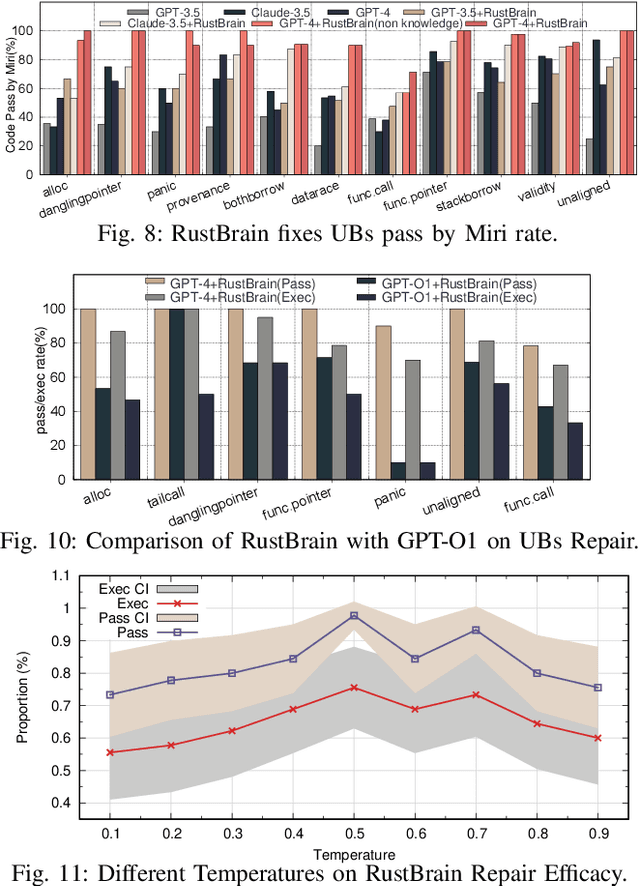
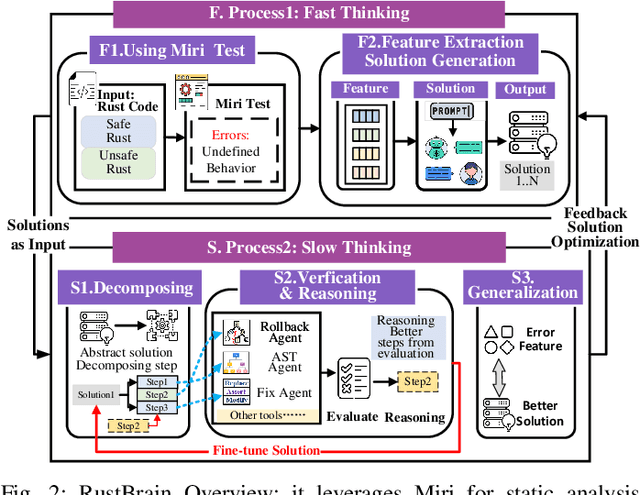

To provide flexibility and low-level interaction capabilities, the unsafe tag in Rust is essential in many projects, but undermines memory safety and introduces Undefined Behaviors (UBs) that reduce safety. Eliminating these UBs requires a deep understanding of Rust's safety rules and strong typing. Traditional methods require depth analysis of code, which is laborious and depends on knowledge design. The powerful semantic understanding capabilities of LLM offer new opportunities to solve this problem. Although existing large model debugging frameworks excel in semantic tasks, limited by fixed processes and lack adaptive and dynamic adjustment capabilities. Inspired by the dual process theory of decision-making (Fast and Slow Thinking), we present a LLM-based framework called RustBrain that automatically and flexibly minimizes UBs in Rust projects. Fast thinking extracts features to generate solutions, while slow thinking decomposes, verifies, and generalizes them abstractly. To apply verification and generalization results to solution generation, enabling dynamic adjustments and precise outputs, RustBrain integrates two thinking through a feedback mechanism. Experimental results on Miri dataset show a 94.3% pass rate and 80.4% execution rate, improving flexibility and Rust projects safety.
OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
Feb 25, 2025Vision-Language Navigation (VLN) aims to guide agents through an environment by leveraging both language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising a versatile toolchain and large-scale benchmark for aerial VLN. Firstly, we develop a highly automated toolchain for data collection, enabling automatic point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Secondly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. The corresponding visual data are generated using various rendering engines and advanced techniques, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). All data exhibit high visual quality. Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of the dataset. Thirdly, we propose OpenFly-Agent, a keyframe-aware VLN model, which takes language instructions, current observations, and historical keyframes as input, and outputs flight actions directly. Extensive analyses and experiments are conducted, showcasing the superiority of our OpenFly platform and OpenFly-Agent. The toolchain, dataset, and codes will be open-sourced.