 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes
Jun 06, 2025Constructing real-world data-to-insight pipelines often involves data extraction from data lakes, data integration across heterogeneous data sources, and diverse operations from data cleaning to analysis. The design and implementation of data science pipelines require domain knowledge, technical expertise, and even project-specific insights. AI systems have shown remarkable reasoning, coding, and understanding capabilities. However, it remains unclear to what extent these capabilities translate into successful design and execution of such complex pipelines. We introduce KRAMABENCH: a benchmark composed of 104 manually-curated real-world data science pipelines spanning 1700 data files from 24 data sources in 6 different domains. We show that these pipelines test the end-to-end capabilities of AI systems on data processing, requiring data discovery, wrangling and cleaning, efficient processing, statistical reasoning, and orchestrating data processing steps given a high-level task. Our evaluation tests 5 general models and 3 code generation models using our reference framework, DS-GURU, which instructs the AI model to decompose a question into a sequence of subtasks, reason through each step, and synthesize Python code that implements the proposed design. Our results on KRAMABENCH show that, although the models are sufficiently capable of solving well-specified data science code generation tasks, when extensive data processing and domain knowledge are required to construct real-world data science pipelines, existing out-of-box models fall short. Progress on KramaBench represents crucial steps towards developing autonomous data science agents for real-world applications. Our code, reference framework, and data are available at https://github.com/mitdbg/KramaBench.
Supervised Visual Docking Network for Unmanned Surface Vehicles Using Auto-labeling in Real-world Water Environments
Mar 05, 2025Unmanned Surface Vehicles (USVs) are increasingly applied to water operations such as environmental monitoring and river-map modeling. It faces a significant challenge in achieving precise autonomous docking at ports or stations, still relying on remote human control or external positioning systems for accuracy and safety which limits the full potential of human-out-of-loop deployment for USVs.This paper introduces a novel supervised learning pipeline with the auto-labeling technique for USVs autonomous visual docking. Firstly, we designed an auto-labeling data collection pipeline that appends relative pose and image pair to the dataset. This step does not require conventional manual labeling for supervised learning. Secondly, the Neural Dock Pose Estimator (NDPE) is proposed to achieve relative dock pose prediction without the need for hand-crafted feature engineering, camera calibration, and peripheral markers. Moreover, The NDPE can accurately predict the relative dock pose in real-world water environments, facilitating the implementation of Position-Based Visual Servo (PBVS) and low-level motion controllers for efficient and autonomous docking.Experiments show that the NDPE is robust to the disturbance of the distance and the USV velocity. The effectiveness of our proposed solution is tested and validated in real-world water environments, reflecting its capability to handle real-world autonomous docking tasks.
Improving DBMS Scheduling Decisions with Fine-grained Performance Prediction on Concurrent Queries -- Extended
Jan 27, 2025Query scheduling is a critical task that directly impacts query performance in database management systems (DBMS). Deeply integrated schedulers, which require changes to DBMS internals, are usually customized for a specific engine and can take months to implement. In contrast, non-intrusive schedulers make coarse-grained decisions, such as controlling query admission and re-ordering query execution, without requiring modifications to DBMS internals. They require much less engineering effort and can be applied across a wide range of DBMS engines, offering immediate benefits to end users. However, most existing non-intrusive scheduling systems rely on simplified cost models and heuristics that cannot accurately model query interactions under concurrency and different system states, possibly leading to suboptimal scheduling decisions. This work introduces IconqSched, a new, principled non-intrusive scheduler that optimizes the execution order and timing of queries to enhance total end-to-end runtime as experienced by the user query queuing time plus system runtime. Unlike previous approaches, IconqSched features a novel fine-grained predictor, Iconq, which treats the DBMS as a black box and accurately estimates the system runtime of concurrently executed queries under different system states. Using these predictions, IconqSched is able to capture system runtime variations across different query mixes and system loads. It then employs a greedy scheduling algorithm to effectively determine which queries to submit and when to submit them. We compare IconqSched to other schedulers in terms of end-to-end runtime using real workload traces. On Postgres, IconqSched reduces end-to-end runtime by 16.2%-28.2% on average and 33.6%-38.9% in the tail. Similarly, on Redshift, it reduces end-to-end runtime by 10.3%-14.1% on average and 14.9%-22.2% in the tail.
Fast-UMI: A Scalable and Hardware-Independent Universal Manipulation Interface
Sep 29, 2024



Collecting real-world manipulation trajectory data involving robotic arms is essential for developing general-purpose action policies in robotic manipulation, yet such data remains scarce. Existing methods face limitations such as high costs, labor intensity, hardware dependencies, and complex setup requirements involving SLAM algorithms. In this work, we introduce Fast-UMI, an interface-mediated manipulation system comprising two key components: a handheld device operated by humans for data collection and a robot-mounted device used during policy inference. Our approach employs a decoupled design compatible with a wide range of grippers while maintaining consistent observation perspectives, allowing models trained on handheld-collected data to be directly applied to real robots. By directly obtaining the end-effector pose using existing commercial hardware products, we eliminate the need for complex SLAM deployment and calibration, streamlining data processing. Fast-UMI provides supporting software tools for efficient robot learning data collection and conversion, facilitating rapid, plug-and-play functionality. This system offers an efficient and user-friendly tool for robotic learning data acquisition.
AlignBot: Aligning VLM-powered Customized Task Planning with User Reminders Through Fine-Tuning for Household Robots
Sep 18, 2024



This paper presents AlignBot, a novel framework designed to optimize VLM-powered customized task planning for household robots by effectively aligning with user reminders. In domestic settings, aligning task planning with user reminders poses significant challenges due to the limited quantity, diversity, and multimodal nature of the reminders. To address these challenges, AlignBot employs a fine-tuned LLaVA-7B model, functioning as an adapter for GPT-4o. This adapter model internalizes diverse forms of user reminders-such as personalized preferences, corrective guidance, and contextual assistance-into structured instruction-formatted cues that prompt GPT-4o in generating customized task plans. Additionally, AlignBot integrates a dynamic retrieval mechanism that selects task-relevant historical successes as prompts for GPT-4o, further enhancing task planning accuracy. To validate the effectiveness of AlignBot, experiments are conducted in real-world household environments, which are constructed within the laboratory to replicate typical household settings. A multimodal dataset with over 1,500 entries derived from volunteer reminders is used for training and evaluation. The results demonstrate that AlignBot significantly improves customized task planning, outperforming existing LLM- and VLM-powered planners by interpreting and aligning with user reminders, achieving 86.8% success rate compared to the vanilla GPT-4o baseline at 21.6%, reflecting a 65% improvement and over four times greater effectiveness. Supplementary materials are available at: https://yding25.com/AlignBot/
CascadeServe: Unlocking Model Cascades for Inference Serving
Jun 20, 2024Machine learning (ML) models are increasingly deployed to production, calling for efficient inference serving systems. Efficient inference serving is complicated by two challenges: (i) ML models incur high computational costs, and (ii) the request arrival rates of practical applications have frequent, high, and sudden variations which make it hard to correctly provision hardware. Model cascades are positioned to tackle both of these challenges, as they (i) save work while maintaining accuracy, and (ii) expose a high-resolution trade-off between work and accuracy, allowing for fine-grained adjustments to request arrival rates. Despite their potential, model cascades haven't been used inside an online serving system. This comes with its own set of challenges, including workload adaption, model replication onto hardware, inference scheduling, request batching, and more. In this work, we propose CascadeServe, which automates and optimizes end-to-end inference serving with cascades. CascadeServe operates in an offline and online phase. In the offline phase, the system pre-computes a gear plan that specifies how to serve inferences online. In the online phase, the gear plan allows the system to serve inferences while making near-optimal adaptations to the query load at negligible decision overheads. We find that CascadeServe saves 2-3x in cost across a wide spectrum of the latency-accuracy space when compared to state-of-the-art baselines on different workloads.
Extract-Transform-Load for Video Streams
Oct 07, 2023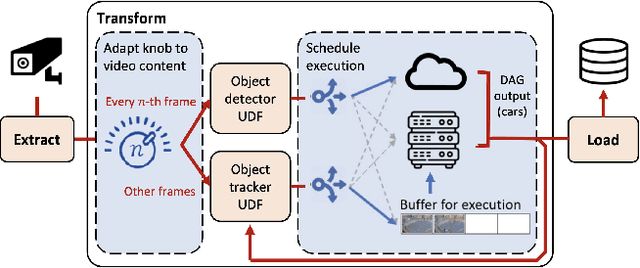
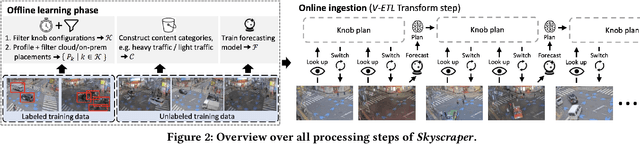
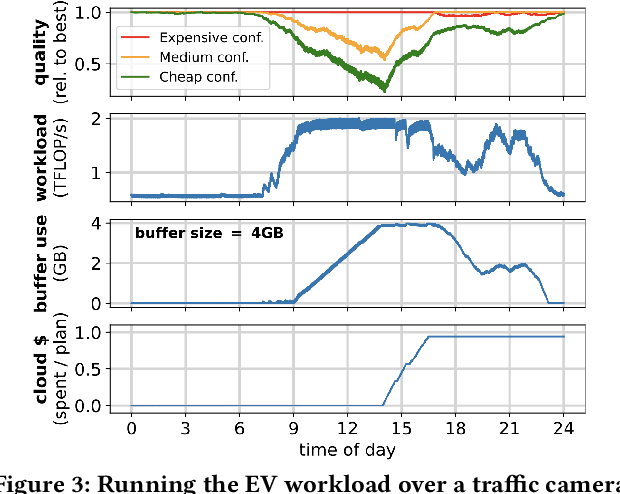
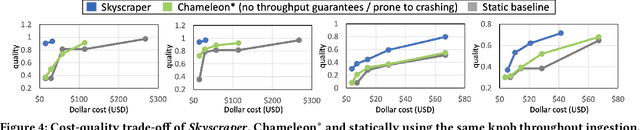
Social media, self-driving cars, and traffic cameras produce video streams at large scales and cheap cost. However, storing and querying video at such scales is prohibitively expensive. We propose to treat large-scale video analytics as a data warehousing problem: Video is a format that is easy to produce but needs to be transformed into an application-specific format that is easy to query. Analogously, we define the problem of Video Extract-Transform-Load (V-ETL). V-ETL systems need to reduce the cost of running a user-defined V-ETL job while also giving throughput guarantees to keep up with the rate at which data is produced. We find that no current system sufficiently fulfills both needs and therefore propose Skyscraper, a system tailored to V-ETL. Skyscraper can execute arbitrary video ingestion pipelines and adaptively tunes them to reduce cost at minimal or no quality degradation, e.g., by adjusting sampling rates and resolutions to the ingested content. Skyscraper can hereby be provisioned with cheap on-premises compute and uses a combination of buffering and cloud bursting to deal with peaks in workload caused by expensive processing configurations. In our experiments, we find that Skyscraper significantly reduces the cost of V-ETL ingestion compared to adaptions of current SOTA systems, while at the same time giving robustness guarantees that these systems are lacking.
* 26 pages, 23 figures
Lero: A Learning-to-Rank Query Optimizer
Feb 20, 2023A recent line of works apply machine learning techniques to assist or rebuild cost-based query optimizers in DBMS. While exhibiting superiority in some benchmarks, their deficiencies, e.g., unstable performance, high training cost, and slow model updating, stem from the inherent hardness of predicting the cost or latency of execution plans using machine learning models. In this paper, we introduce a learning-to-rank query optimizer, called Lero, which builds on top of a native query optimizer and continuously learns to improve the optimization performance. The key observation is that the relative order or rank of plans, rather than the exact cost or latency, is sufficient for query optimization. Lero employs a pairwise approach to train a classifier to compare any two plans and tell which one is better. Such a binary classification task is much easier than the regression task to predict the cost or latency, in terms of model efficiency and accuracy. Rather than building a learned optimizer from scratch, Lero is designed to leverage decades of wisdom of databases and improve the native query optimizer. With its non-intrusive design, Lero can be implemented on top of any existing DBMS with minimal integration efforts. We implement Lero and demonstrate its outstanding performance using PostgreSQL. In our experiments, Lero achieves near optimal performance on several benchmarks. It reduces the plan execution time of the native optimizer in PostgreSQL by up to 70% and other learned query optimizers by up to 37%. Meanwhile, Lero continuously learns and automatically adapts to query workloads and changes in data.
FactorJoin: A New Cardinality Estimation Framework for Join Queries
Dec 11, 2022
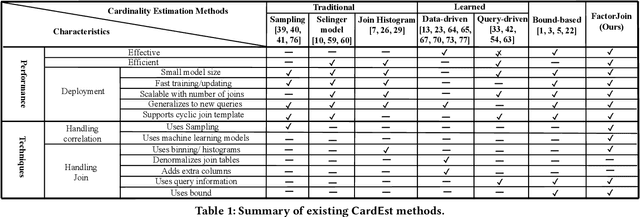
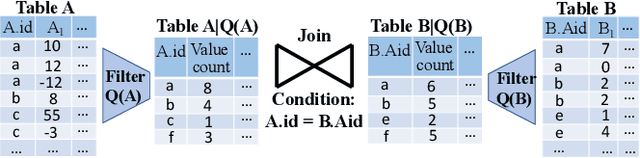
Cardinality estimation is one of the most fundamental and challenging problems in query optimization. Neither classical nor learning-based methods yield satisfactory performance when estimating the cardinality of the join queries. They either rely on simplified assumptions leading to ineffective cardinality estimates or build large models to understand the data distributions, leading to long planning times and a lack of generalizability across queries. In this paper, we propose a new framework FactorJoin for estimating join queries. FactorJoin combines the idea behind the classical join-histogram method to efficiently handle joins with the learning-based methods to accurately capture attribute correlation. Specifically, FactorJoin scans every table in a DB and builds single-table conditional distributions during an offline preparation phase. When a join query comes, FactorJoin translates it into a factor graph model over the learned distributions to effectively and efficiently estimate its cardinality. Unlike existing learning-based methods, FactorJoin does not need to de-normalize joins upfront or require executed query workloads to train the model. Since it only relies on single-table statistics, FactorJoin has small space overhead and is extremely easy to train and maintain. In our evaluation, FactorJoin can produce more effective estimates than the previous state-of-the-art learning-based methods, with 40x less estimation latency, 100x smaller model size, and 100x faster training speed at comparable or better accuracy. In addition, FactorJoin can estimate 10,000 sub-plan queries within one second to optimize the query plan, which is very close to the traditional cardinality estimators in commercial DBMS.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021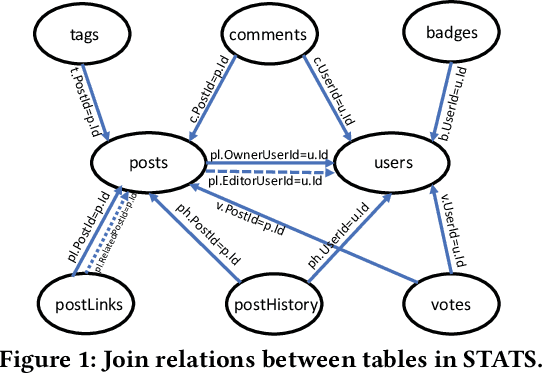
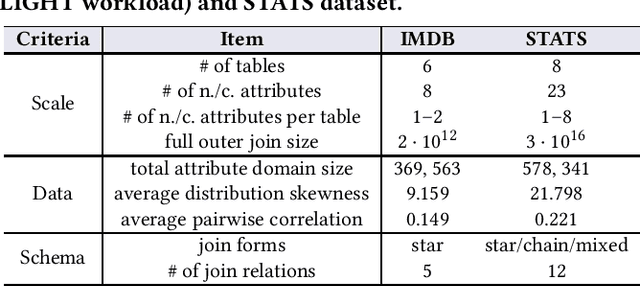
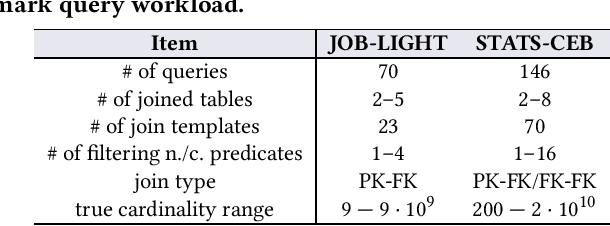
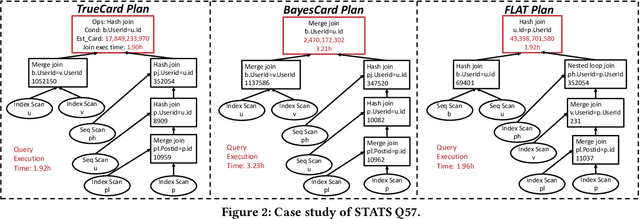
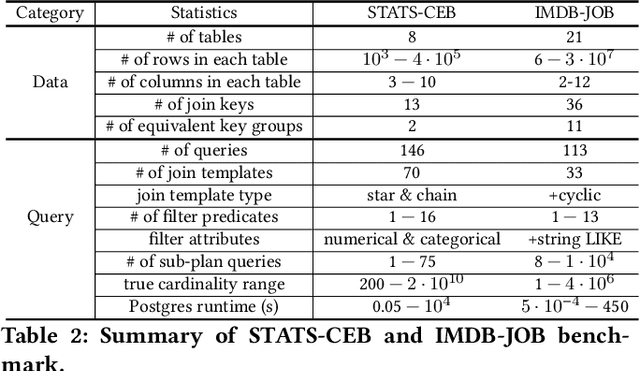
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.