 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONCUR: A Framework for Continual Constrained and Unconstrained Routing
Dec 10, 2025AI tasks differ in complexity and are best addressed with different computation strategies (e.g., combinations of models and decoding methods). Hence, an effective routing system that maps tasks to the appropriate strategies is crucial. Most prior methods build the routing framework by training a single model across all strategies, which demands full retraining whenever new strategies appear and leads to high overhead. Attempts at such continual routing, however, often face difficulties with generalization. Prior models also typically use a single input representation, limiting their ability to capture the full complexity of the routing problem and leading to sub-optimal routing decisions. To address these gaps, we propose CONCUR, a continual routing framework that supports both constrained and unconstrained routing (i.e., routing with or without a budget). Our modular design trains a separate predictor model for each strategy, enabling seamless incorporation of new strategies with low additional training cost. Our predictors also leverage multiple representations of both tasks and computation strategies to better capture overall problem complexity. Experiments on both in-distribution and out-of-distribution, knowledge- and reasoning-intensive tasks show that our method outperforms the best single strategy and strong existing routing techniques with higher end-to-end accuracy and lower inference cost in both continual and non-continual settings, while also reducing training cost in the continual setting.
Log-Augmented Generation: Scaling Test-Time Reasoning with Reusable Computation
May 20, 2025While humans naturally learn and adapt from past experiences, large language models (LLMs) and their agentic counterparts struggle to retain reasoning from previous tasks and apply them in future contexts. To address this limitation, we propose a novel framework, log-augmented generation (LAG) that directly reuses prior computation and reasoning from past logs at test time to enhance model's ability to learn from previous tasks and perform better on new, unseen challenges, all while keeping the system efficient and scalable. Specifically, our system represents task logs using key-value (KV) caches, encoding the full reasoning context of prior tasks while storing KV caches for only a selected subset of tokens. When a new task arises, LAG retrieves the KV values from relevant logs to augment generation. Our approach differs from reflection-based memory mechanisms by directly reusing prior reasoning and computations without requiring additional steps for knowledge extraction or distillation. Our method also goes beyond existing KV caching techniques, which primarily target efficiency gains rather than improving accuracy. Experiments on knowledge- and reasoning-intensive datasets demonstrate that our method significantly outperforms standard agentic systems that do not utilize logs, as well as existing solutions based on reflection and KV cache techniques.
EnrichIndex: Using LLMs to Enrich Retrieval Indices Offline
Apr 04, 2025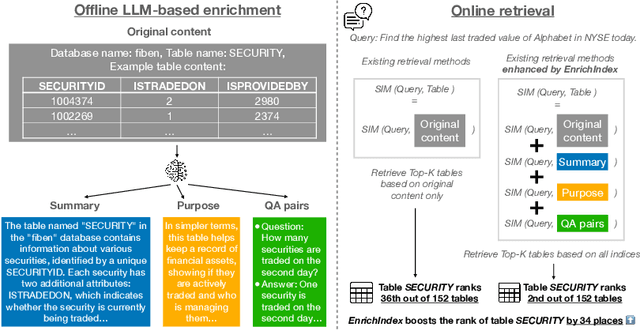
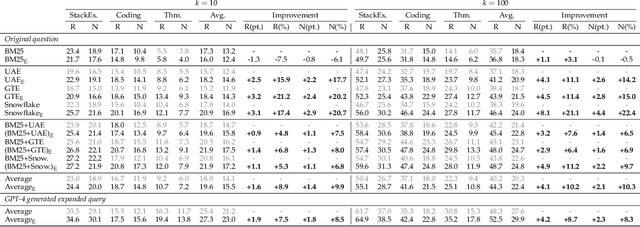
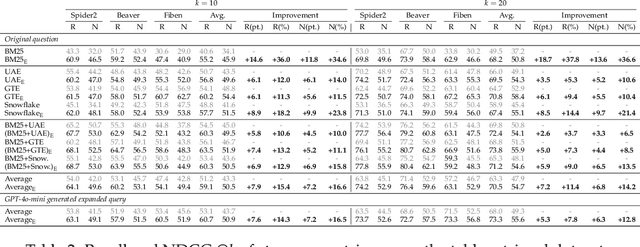
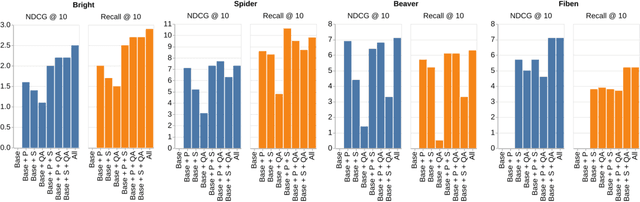
Existing information retrieval systems excel in cases where the language of target documents closely matches that of the user query. However, real-world retrieval systems are often required to implicitly reason whether a document is relevant. For example, when retrieving technical texts or tables, their relevance to the user query may be implied through a particular jargon or structure, rather than explicitly expressed in their content. Large language models (LLMs) hold great potential in identifying such implied relevance by leveraging their reasoning skills. Nevertheless, current LLM-augmented retrieval is hindered by high latency and computation cost, as the LLM typically computes the query-document relevance online, for every query anew. To tackle this issue we introduce EnrichIndex, a retrieval approach which instead uses the LLM offline to build semantically-enriched retrieval indices, by performing a single pass over all documents in the retrieval corpus once during ingestion time. Furthermore, the semantically-enriched indices can complement existing online retrieval approaches, boosting the performance of LLM re-rankers. We evaluated EnrichIndex on five retrieval tasks, involving passages and tables, and found that it outperforms strong online LLM-based retrieval systems, with an average improvement of 11.7 points in recall @ 10 and 10.6 points in NDCG @ 10 compared to strong baselines. In terms of online calls to the LLM, it processes 293.3 times fewer tokens which greatly reduces the online latency and cost. Overall, EnrichIndex is an effective way to build better retrieval indices offline by leveraging the strong reasoning skills of LLMs.
Can we Retrieve Everything All at Once? ARM: An Alignment-Oriented LLM-based Retrieval Method
Jan 30, 2025Real-world open-domain questions can be complicated, particularly when answering them involves information from multiple information sources. LLMs have demonstrated impressive performance in decomposing complex tasks into simpler steps, and previous work has used it for better retrieval in support of complex questions. However, LLM's decomposition of questions is unaware of what data is available and how data is organized, often leading to a sub-optimal retrieval performance. Recent effort in agentic RAG proposes to perform retrieval in an iterative fashion, where a followup query is derived as an action based on previous rounds of retrieval. While this provides one way of interacting with the data collection, agentic RAG's exploration of data is inefficient because successive queries depend on previous results rather than being guided by the organization of available data in the collection. To address this problem, we propose an LLM-based retrieval method -- ARM, that aims to better align the question with the organization of the data collection by exploring relationships among data objects beyond matching the utterance of the query, thus leading to a retrieve-all-at-once solution for complex queries. We evaluated ARM on two datasets, Bird and OTT-QA. On Bird, it outperforms standard RAG with query decomposition by up to 5.2 pt in execution accuracy and agentic RAG (ReAct) by up to 15.9 pt. On OTT-QA, it achieves up to 5.5 pt and 19.3 pt higher F1 match scores compared to these approaches.
Improving DBMS Scheduling Decisions with Fine-grained Performance Prediction on Concurrent Queries -- Extended
Jan 27, 2025Query scheduling is a critical task that directly impacts query performance in database management systems (DBMS). Deeply integrated schedulers, which require changes to DBMS internals, are usually customized for a specific engine and can take months to implement. In contrast, non-intrusive schedulers make coarse-grained decisions, such as controlling query admission and re-ordering query execution, without requiring modifications to DBMS internals. They require much less engineering effort and can be applied across a wide range of DBMS engines, offering immediate benefits to end users. However, most existing non-intrusive scheduling systems rely on simplified cost models and heuristics that cannot accurately model query interactions under concurrency and different system states, possibly leading to suboptimal scheduling decisions. This work introduces IconqSched, a new, principled non-intrusive scheduler that optimizes the execution order and timing of queries to enhance total end-to-end runtime as experienced by the user query queuing time plus system runtime. Unlike previous approaches, IconqSched features a novel fine-grained predictor, Iconq, which treats the DBMS as a black box and accurately estimates the system runtime of concurrently executed queries under different system states. Using these predictions, IconqSched is able to capture system runtime variations across different query mixes and system loads. It then employs a greedy scheduling algorithm to effectively determine which queries to submit and when to submit them. We compare IconqSched to other schedulers in terms of end-to-end runtime using real workload traces. On Postgres, IconqSched reduces end-to-end runtime by 16.2%-28.2% on average and 33.6%-38.9% in the tail. Similarly, on Redshift, it reduces end-to-end runtime by 10.3%-14.1% on average and 14.9%-22.2% in the tail.
BEAVER: An Enterprise Benchmark for Text-to-SQL
Sep 03, 2024Existing text-to-SQL benchmarks have largely been constructed using publicly available tables from the web with human-generated tests containing question and SQL statement pairs. They typically show very good results and lead people to think that LLMs are effective at text-to-SQL tasks. In this paper, we apply off-the-shelf LLMs to a benchmark containing enterprise data warehouse data. In this environment, LLMs perform poorly, even when standard prompt engineering and RAG techniques are utilized. As we will show, the reasons for poor performance are largely due to three characteristics: (1) public LLMs cannot train on enterprise data warehouses because they are largely in the "dark web", (2) schemas of enterprise tables are more complex than the schemas in public data, which leads the SQL-generation task innately harder, and (3) business-oriented questions are often more complex, requiring joins over multiple tables and aggregations. As a result, we propose a new dataset BEAVER, sourced from real enterprise data warehouses together with natural language queries and their correct SQL statements which we collected from actual user history. We evaluated this dataset using recent LLMs and demonstrated their poor performance on this task. We hope this dataset will facilitate future researchers building more sophisticated text-to-SQL systems which can do better on this important class of data.
Making LLMs Work for Enterprise Data Tasks
Jul 22, 2024Large language models (LLMs) know little about enterprise database tables in the private data ecosystem, which substantially differ from web text in structure and content. As LLMs' performance is tied to their training data, a crucial question is how useful they can be in improving enterprise database management and analysis tasks. To address this, we contribute experimental results on LLMs' performance for text-to-SQL and semantic column-type detection tasks on enterprise datasets. The performance of LLMs on enterprise data is significantly lower than on benchmark datasets commonly used. Informed by our findings and feedback from industry practitioners, we identify three fundamental challenges -- latency, cost, and quality -- and propose potential solutions to use LLMs in enterprise data workflows effectively.
MDCR: A Dataset for Multi-Document Conditional Reasoning
Jun 17, 2024The same real-life questions posed to different individuals may lead to different answers based on their unique situations. For instance, whether a student is eligible for a scholarship depends on eligibility conditions, such as major or degree required. ConditionalQA was proposed to evaluate models' capability of reading a document and answering eligibility questions, considering unmentioned conditions. However, it is limited to questions on single documents, neglecting harder cases that may require cross-document reasoning and optimization, for example, "What is the maximum number of scholarships attainable?" Such questions over multiple documents are not only more challenging due to more context having to understand, but also because the model has to (1) explore all possible combinations of unmentioned conditions and (2) understand the relationship between conditions across documents, to reason about the optimal outcome. To evaluate models' capability of answering such questions, we propose a new dataset MDCR, which can reflect real-world challenges and serve as a new test bed for complex conditional reasoning that requires optimization. We evaluate this dataset using the most recent LLMs and demonstrate their limitations in solving this task. We believe this dataset will facilitate future research in answering optimization questions with unknown conditions.
Is Table Retrieval a Solved Problem? Join-Aware Multi-Table Retrieval
Apr 15, 2024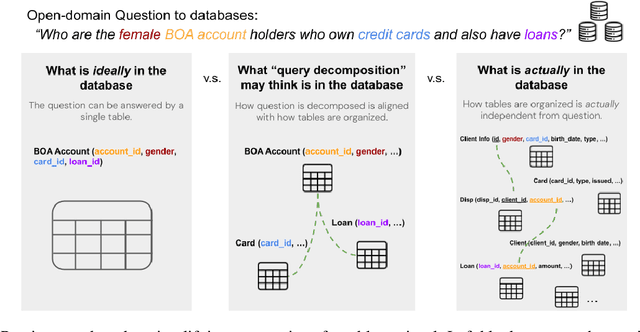
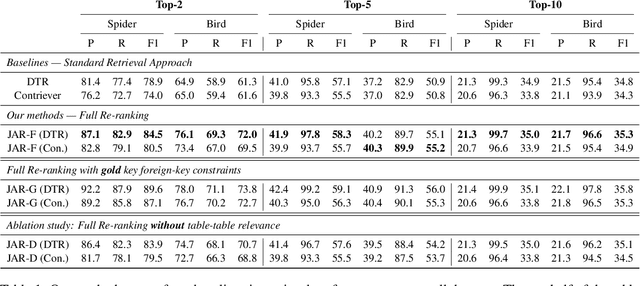

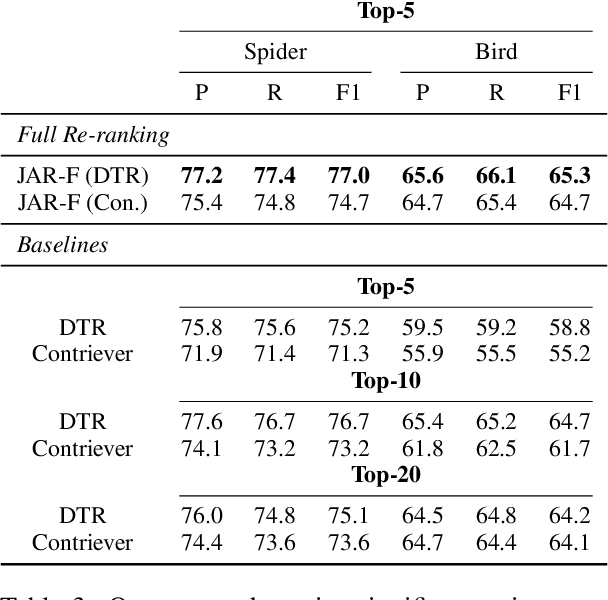
Retrieving relevant tables containing the necessary information to accurately answer a given question over tables is critical to open-domain question-answering (QA) systems. Previous methods assume the answer to such a question can be found either in a single table or multiple tables identified through question decomposition or rewriting. However, neither of these approaches is sufficient, as many questions require retrieving multiple tables and joining them through a join plan that cannot be discerned from the user query itself. If the join plan is not considered in the retrieval stage, the subsequent steps of reasoning and answering based on those retrieved tables are likely to be incorrect. To address this problem, we introduce a method that uncovers useful join relations for any query and database during table retrieval. We use a novel re-ranking method formulated as a mixed-integer program that considers not only table-query relevance but also table-table relevance that requires inferring join relationships. Our method outperforms the state-of-the-art approaches for table retrieval by up to 9.3% in F1 score and for end-to-end QA by up to 5.4% in accuracy.