 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnrichIndex: Using LLMs to Enrich Retrieval Indices Offline
Paper and Code
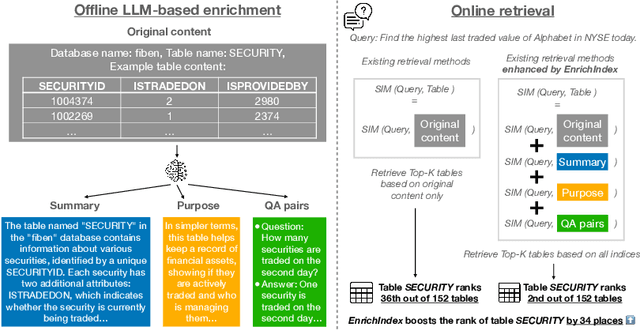
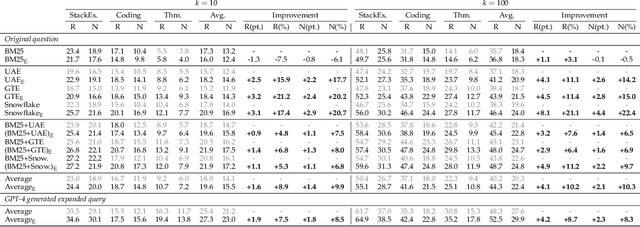
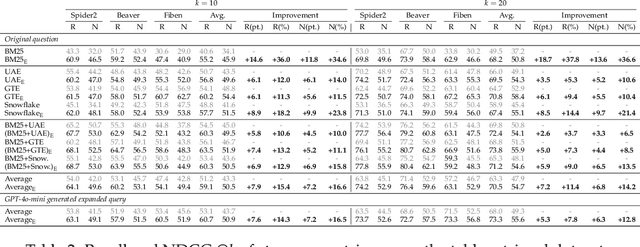
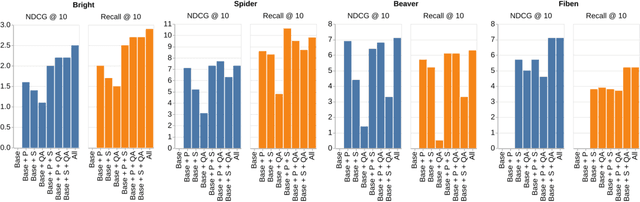
Existing information retrieval systems excel in cases where the language of target documents closely matches that of the user query. However, real-world retrieval systems are often required to implicitly reason whether a document is relevant. For example, when retrieving technical texts or tables, their relevance to the user query may be implied through a particular jargon or structure, rather than explicitly expressed in their content. Large language models (LLMs) hold great potential in identifying such implied relevance by leveraging their reasoning skills. Nevertheless, current LLM-augmented retrieval is hindered by high latency and computation cost, as the LLM typically computes the query-document relevance online, for every query anew. To tackle this issue we introduce EnrichIndex, a retrieval approach which instead uses the LLM offline to build semantically-enriched retrieval indices, by performing a single pass over all documents in the retrieval corpus once during ingestion time. Furthermore, the semantically-enriched indices can complement existing online retrieval approaches, boosting the performance of LLM re-rankers. We evaluated EnrichIndex on five retrieval tasks, involving passages and tables, and found that it outperforms strong online LLM-based retrieval systems, with an average improvement of 11.7 points in recall @ 10 and 10.6 points in NDCG @ 10 compared to strong baselines. In terms of online calls to the LLM, it processes 293.3 times fewer tokens which greatly reduces the online latency and cost. Overall, EnrichIndex is an effective way to build better retrieval indices offline by leveraging the strong reasoning skills of LLMs.