 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed Prompting Does Not Fix Knowledge Gaps, But Helps Models Say "I Don't Know"
Feb 04, 2026Large language models often struggle to recognize their knowledge limits in closed-book question answering, leading to confident hallucinations. While decomposed prompting is typically used to improve accuracy, we investigate its impact on reliability. We evaluate three task-equivalent prompting regimes: Direct, Assistive, and Incremental, across different model scales and multi-hop QA benchmarks. We find that although accuracy gains from decomposition diminish in frontier models, disagreements between prompting regimes remain highly indicative of potential errors. Because factual knowledge is stable while hallucinations are stochastic, cross-regime agreement provides a precise signal of internal uncertainty. We leverage this signal to implement a training-free abstention policy that requires no retrieval or fine-tuning. Our results show that disagreement-based abstention outperforms standard uncertainty baselines as an error detector, improving both F1 and AUROC across settings. This demonstrates that decomposition-based prompting can serve as a practical diagnostic probe for model reliability in closed-book QA.
EnrichIndex: Using LLMs to Enrich Retrieval Indices Offline
Apr 04, 2025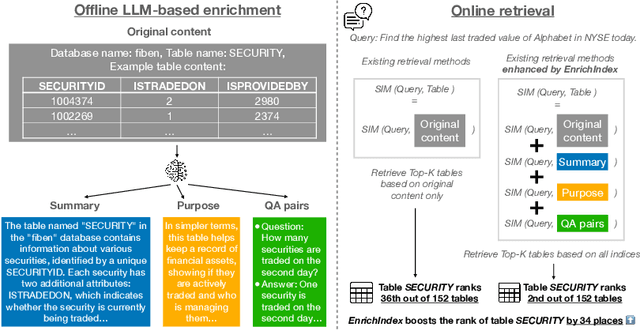
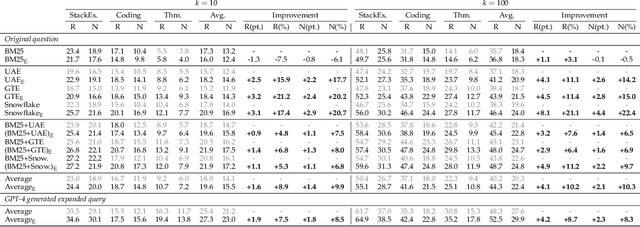
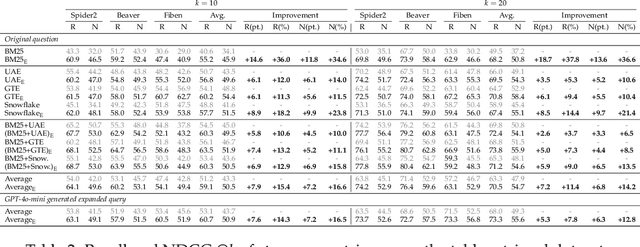
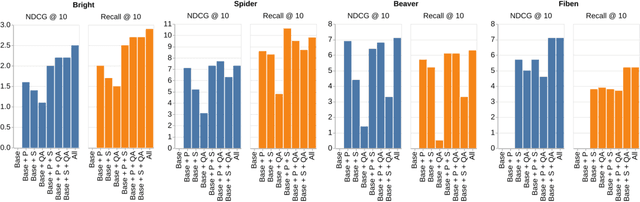
Existing information retrieval systems excel in cases where the language of target documents closely matches that of the user query. However, real-world retrieval systems are often required to implicitly reason whether a document is relevant. For example, when retrieving technical texts or tables, their relevance to the user query may be implied through a particular jargon or structure, rather than explicitly expressed in their content. Large language models (LLMs) hold great potential in identifying such implied relevance by leveraging their reasoning skills. Nevertheless, current LLM-augmented retrieval is hindered by high latency and computation cost, as the LLM typically computes the query-document relevance online, for every query anew. To tackle this issue we introduce EnrichIndex, a retrieval approach which instead uses the LLM offline to build semantically-enriched retrieval indices, by performing a single pass over all documents in the retrieval corpus once during ingestion time. Furthermore, the semantically-enriched indices can complement existing online retrieval approaches, boosting the performance of LLM re-rankers. We evaluated EnrichIndex on five retrieval tasks, involving passages and tables, and found that it outperforms strong online LLM-based retrieval systems, with an average improvement of 11.7 points in recall @ 10 and 10.6 points in NDCG @ 10 compared to strong baselines. In terms of online calls to the LLM, it processes 293.3 times fewer tokens which greatly reduces the online latency and cost. Overall, EnrichIndex is an effective way to build better retrieval indices offline by leveraging the strong reasoning skills of LLMs.
Generating Tables from the Parametric Knowledge of Language Models
Jun 16, 2024We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Oct 02, 2023Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Answering Questions by Meta-Reasoning over Multiple Chains of Thought
Apr 25, 2023



Modern systems for multi-hop question answering (QA) typically break questions into a sequence of reasoning steps, termed chain-of-thought (CoT), before arriving at a final answer. Often, multiple chains are sampled and aggregated through a voting mechanism over the final answers, but the intermediate steps themselves are discarded. While such approaches improve performance, they do not consider the relations between intermediate steps across chains and do not provide a unified explanation for the predicted answer. We introduce Multi-Chain Reasoning (MCR), an approach which prompts large language models to meta-reason over multiple chains of thought, rather than aggregating their answers. MCR examines different reasoning chains, mixes information between them and selects the most relevant facts in generating an explanation and predicting the answer. MCR outperforms strong baselines on 7 multi-hop QA datasets. Moreover, our analysis reveals that MCR explanations exhibit high quality, enabling humans to verify its answers.
QAMPARI: : An Open-domain Question Answering Benchmark for Questions with Many Answers from Multiple Paragraphs
May 26, 2022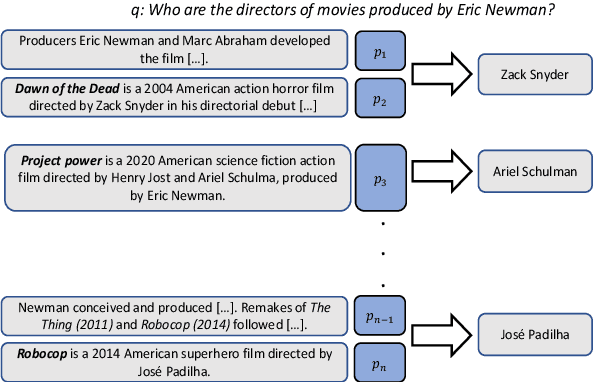

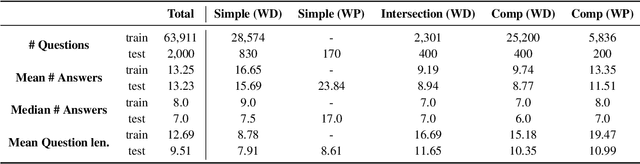
Existing benchmarks for open-domain question answering (ODQA) typically focus on questions whose answers can be extracted from a single paragraph. By contrast, many natural questions, such as "What players were drafted by the Brooklyn Nets?" have a list of answers. Answering such questions requires retrieving and reading from many passages, in a large corpus. We introduce QAMPARI, an ODQA benchmark, where question answers are lists of entities, spread across many paragraphs. We created QAMPARI by (a) generating questions with multiple answers from Wikipedia's knowledge graph and tables, (b) automatically pairing answers with supporting evidence in Wikipedia paragraphs, and (c) manually paraphrasing questions and validating each answer. We train ODQA models from the retrieve-and-read family and find that QAMPARI is challenging in terms of both passage retrieval and answer generation, reaching an F1 score of 26.6 at best. Our results highlight the need for developing ODQA models that handle a broad range of question types, including single and multi-answer questions.
Weakly Supervised Mapping of Natural Language to SQL through Question Decomposition
Dec 12, 2021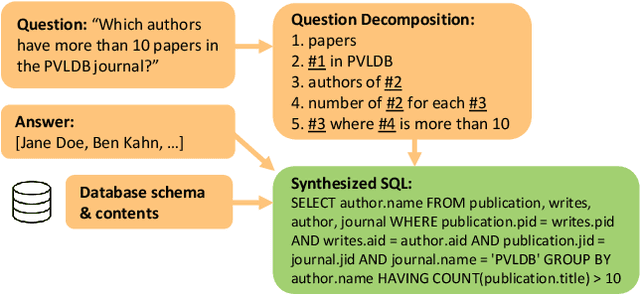
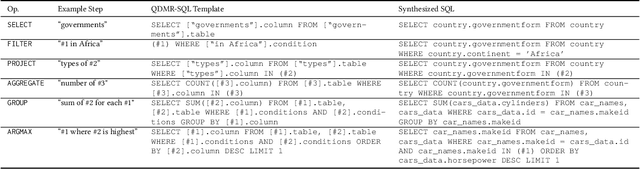
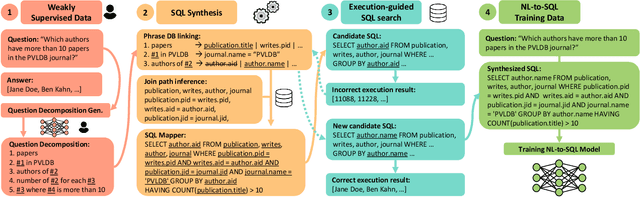

Natural Language Interfaces to Databases (NLIDBs), where users pose queries in Natural Language (NL), are crucial for enabling non-experts to gain insights from data. Developing such interfaces, by contrast, is dependent on experts who often code heuristics for mapping NL to SQL. Alternatively, NLIDBs based on machine learning models rely on supervised examples of NL to SQL mappings (NL-SQL pairs) used as training data. Such examples are again procured using experts, which typically involves more than a one-off interaction. Namely, each data domain in which the NLIDB is deployed may have different characteristics and therefore require either dedicated heuristics or domain-specific training examples. To this end, we propose an alternative approach for training machine learning-based NLIDBs, using weak supervision. We use the recently proposed question decomposition representation called QDMR, an intermediate between NL and formal query languages. Recent work has shown that non-experts are generally successful in translating NL to QDMR. We consequently use NL-QDMR pairs, along with the question answers, as supervision for automatically synthesizing SQL queries. The NL questions and synthesized SQL are then used to train NL-to-SQL models, which we test on five benchmark datasets. Extensive experiments show that our solution, requiring zero expert annotations, performs competitively with models trained on expert annotated data.
Break, Perturb, Build: Automatic Perturbation of Reasoning Paths through Question Decomposition
Jul 29, 2021
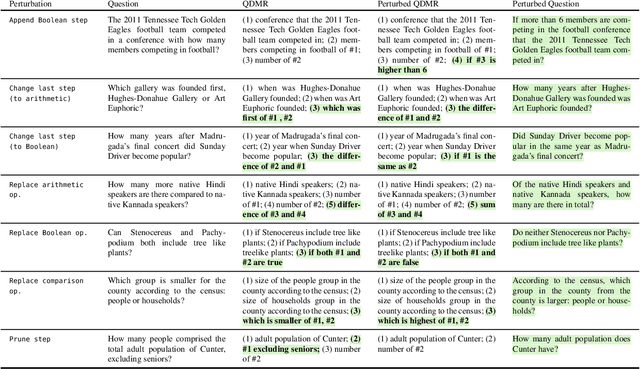


Recent efforts to create challenge benchmarks that test the abilities of natural language understanding models have largely depended on human annotations. In this work, we introduce the "Break, Perturb, Build" (BPB) framework for automatic reasoning-oriented perturbation of question-answer pairs. BPB represents a question by decomposing it into the reasoning steps that are required to answer it, symbolically perturbs the decomposition, and then generates new question-answer pairs. We demonstrate the effectiveness of BPB by creating evaluation sets for three reading comprehension (RC) benchmarks, generating thousands of high-quality examples without human intervention. We evaluate a range of RC models on our evaluation sets, which reveals large performance gaps on generated examples compared to the original data. Moreover, symbolic perturbations enable fine-grained analysis of the strengths and limitations of models. Last, augmenting the training data with examples generated by BPB helps close performance gaps, without any drop on the original data distribution.
Obtaining Faithful Interpretations from Compositional Neural Networks
May 02, 2020



Neural module networks (NMNs) are a popular approach for modeling compositionality: they achieve high accuracy when applied to problems in language and vision, while reflecting the compositional structure of the problem in the network architecture. However, prior work implicitly assumed that the structure of the network modules, describing the abstract reasoning process, provides a faithful explanation of the model's reasoning; that is, that all modules perform their intended behaviour. In this work, we propose and conduct a systematic evaluation of the intermediate outputs of NMNs on NLVR2 and DROP, two datasets which require composing multiple reasoning steps. We find that the intermediate outputs differ from the expected output, illustrating that the network structure does not provide a faithful explanation of model behaviour. To remedy that, we train the model with auxiliary supervision and propose particular choices for module architecture that yield much better faithfulness, at a minimal cost to accuracy.
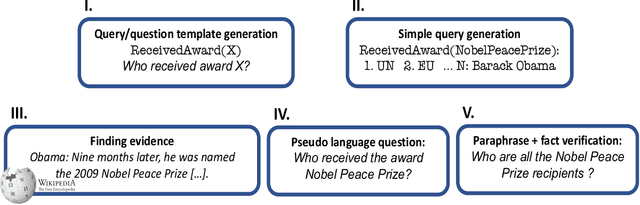
Break It Down: A Question Understanding Benchmark
Jan 31, 2020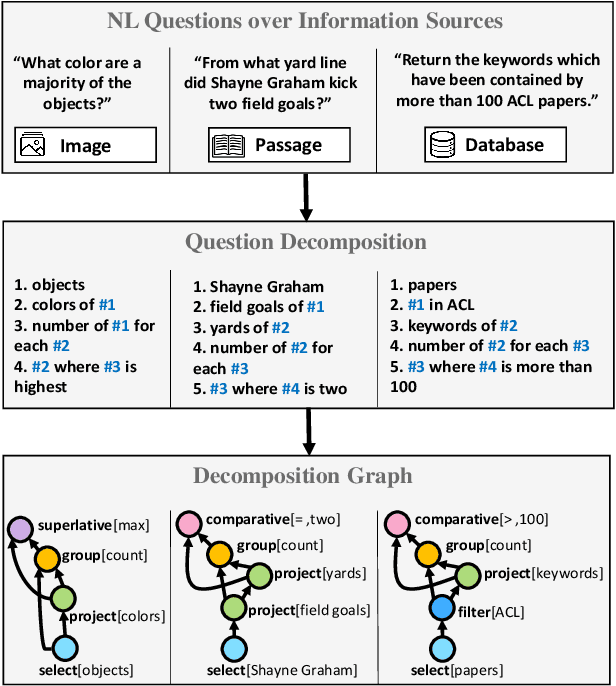
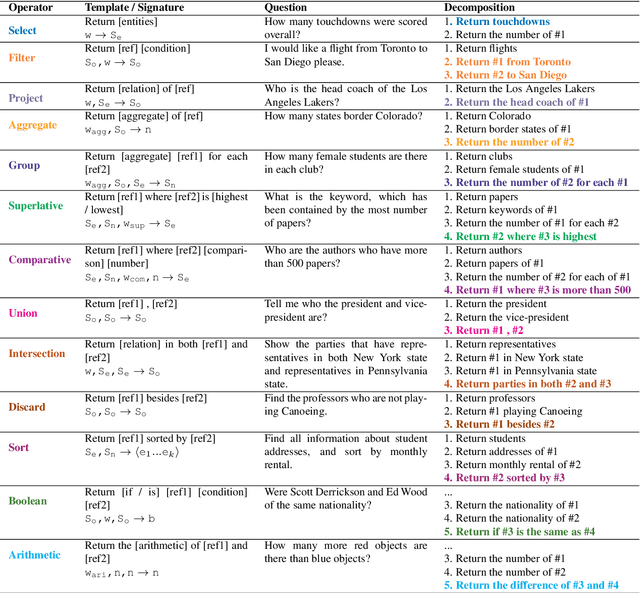
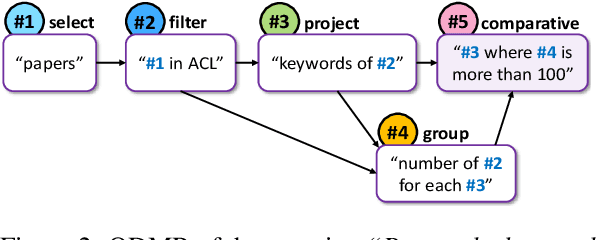

Understanding natural language questions entails the ability to break down a question into the requisite steps for computing its answer. In this work, we introduce a Question Decomposition Meaning Representation (QDMR) for questions. QDMR constitutes the ordered list of steps, expressed through natural language, that are necessary for answering a question. We develop a crowdsourcing pipeline, showing that quality QDMRs can be annotated at scale, and release the Break dataset, containing over 83K pairs of questions and their QDMRs. We demonstrate the utility of QDMR by showing that (a) it can be used to improve open-domain question answering on the HotpotQA dataset, (b) it can be deterministically converted to a pseudo-SQL formal language, which can alleviate annotation in semantic parsing applications. Last, we use Break to train a sequence-to-sequence model with copying that parses questions into QDMR structures, and show that it substantially outperforms several natural baselines.