 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Tables from the Parametric Knowledge of Language Models
Jun 16, 2024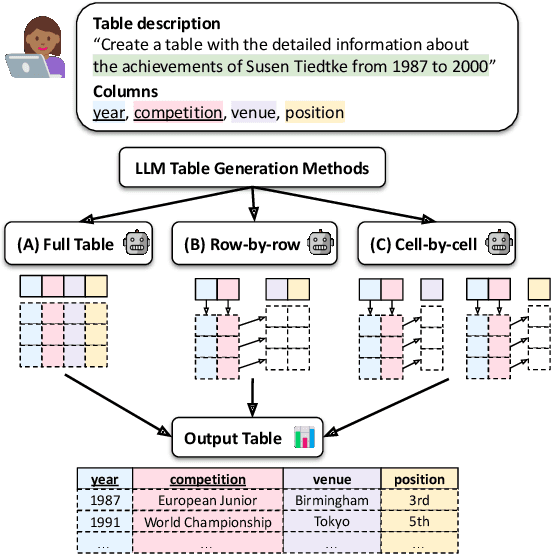
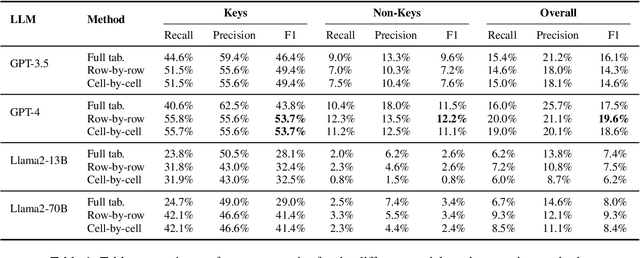
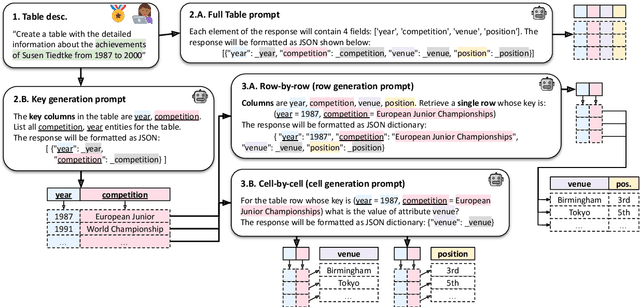
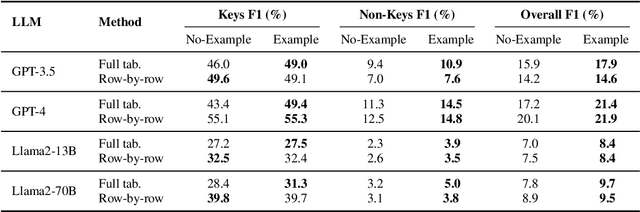
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
SubStrat: A Subset-Based Strategy for Faster AutoML
Jun 07, 2022



Automated machine learning (AutoML) frameworks have become important tools in the data scientists' arsenal, as they dramatically reduce the manual work devoted to the construction of ML pipelines. Such frameworks intelligently search among millions of possible ML pipelines - typically containing feature engineering, model selection and hyper parameters tuning steps - and finally output an optimal pipeline in terms of predictive accuracy. However, when the dataset is large, each individual configuration takes longer to execute, therefore the overall AutoML running times become increasingly high. To this end, we present SubStrat, an AutoML optimization strategy that tackles the data size, rather than configuration space. It wraps existing AutoML tools, and instead of executing them directly on the entire dataset, SubStrat uses a genetic-based algorithm to find a small yet representative data subset which preserves a particular characteristic of the full data. It then employs the AutoML tool on the small subset, and finally, it refines the resulted pipeline by executing a restricted, much shorter, AutoML process on the large dataset. Our experimental results, performed on two popular AutoML frameworks, Auto-Sklearn and TPOT, show that SubStrat reduces their running times by 79% (on average), with less than 2% average loss in the accuracy of the resulted ML pipeline.