 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Centric Evidence Ranking for Attribution and Fact Verification
Jan 29, 2026Attribution and fact verification are critical challenges in natural language processing for assessing information reliability. While automated systems and Large Language Models (LLMs) aim to retrieve and select concise evidence to support or refute claims, they often present users with either insufficient or overly redundant information, leading to inefficient and error-prone verification. To address this, we propose Evidence Ranking, a novel task that prioritizes presenting sufficient information as early as possible in a ranked list. This minimizes user reading effort while still making all available evidence accessible for sequential verification. We compare two approaches for the new ranking task: one-shot ranking and incremental ranking. We introduce a new evaluation framework, inspired by information retrieval metrics, and construct a unified benchmark by aggregating existing fact verification datasets. Extensive experiments with diverse models show that incremental ranking strategies better capture complementary evidence and that LLM-based methods outperform shallower baselines, while still facing challenges in balancing sufficiency and redundancy. Compared to evidence selection, we conduct a controlled user study and demonstrate that evidence ranking both reduces reading effort and improves verification. This work provides a foundational step toward more interpretable, efficient, and user-aligned information verification systems.
Break Out the Silverware -- Semantic Understanding of Stored Household Items
Dec 25, 2025``Bring me a plate.'' For domestic service robots, this simple command reveals a complex challenge: inferring where everyday items are stored, often out of sight in drawers, cabinets, or closets. Despite advances in vision and manipulation, robots still lack the commonsense reasoning needed to complete this task. We introduce the Stored Household Item Challenge, a benchmark task for evaluating service robots' cognitive capabilities: given a household scene and a queried item, predict its most likely storage location. Our benchmark includes two datasets: (1) a real-world evaluation set of 100 item-image pairs with human-annotated ground truth from participants' kitchens, and (2) a development set of 6,500 item-image pairs annotated with storage polygons over public kitchen images. These datasets support realistic modeling of household organization and enable comparative evaluation across agent architectures. To begin tackling this challenge, we introduce NOAM (Non-visible Object Allocation Model), a hybrid agent pipeline that combines structured scene understanding with large language model inference. NOAM converts visual input into natural language descriptions of spatial context and visible containers, then prompts a language model (e.g., GPT-4) to infer the most likely hidden storage location. This integrated vision-language agent exhibits emergent commonsense reasoning and is designed for modular deployment within broader robotic systems. We evaluate NOAM against baselines including random selection, vision-language pipelines (Grounding-DINO + SAM), leading multimodal models (e.g., Gemini, GPT-4o, Kosmos-2, LLaMA, Qwen), and human performance. NOAM significantly improves prediction accuracy and approaches human-level results, highlighting best practices for deploying cognitively capable agents in domestic environments.
NER Retriever: Zero-Shot Named Entity Retrieval with Type-Aware Embeddings
Sep 04, 2025We present NER Retriever, a zero-shot retrieval framework for ad-hoc Named Entity Retrieval, a variant of Named Entity Recognition (NER), where the types of interest are not provided in advance, and a user-defined type description is used to retrieve documents mentioning entities of that type. Instead of relying on fixed schemas or fine-tuned models, our method builds on internal representations of large language models (LLMs) to embed both entity mentions and user-provided open-ended type descriptions into a shared semantic space. We show that internal representations, specifically the value vectors from mid-layer transformer blocks, encode fine-grained type information more effectively than commonly used top-layer embeddings. To refine these representations, we train a lightweight contrastive projection network that aligns type-compatible entities while separating unrelated types. The resulting entity embeddings are compact, type-aware, and well-suited for nearest-neighbor search. Evaluated on three benchmarks, NER Retriever significantly outperforms both lexical and dense sentence-level retrieval baselines. Our findings provide empirical support for representation selection within LLMs and demonstrate a practical solution for scalable, schema-free entity retrieval. The NER Retriever Codebase is publicly available at https://github.com/ShacharOr100/ner_retriever
Data Augmentation for Deep Learning Regression Tasks by Machine Learning Models
Jan 07, 2025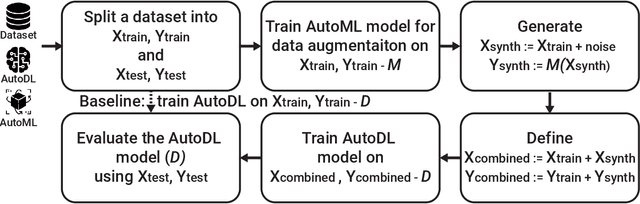
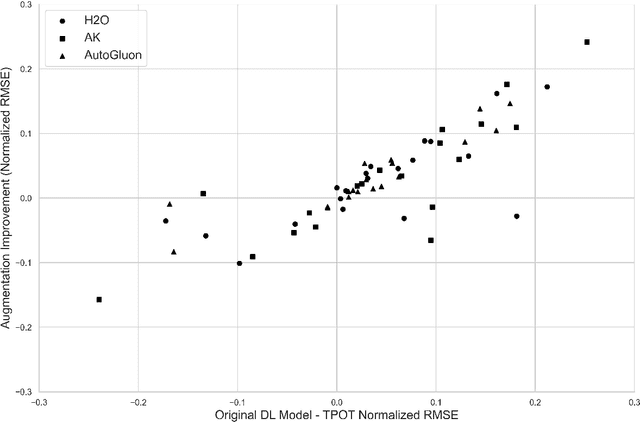
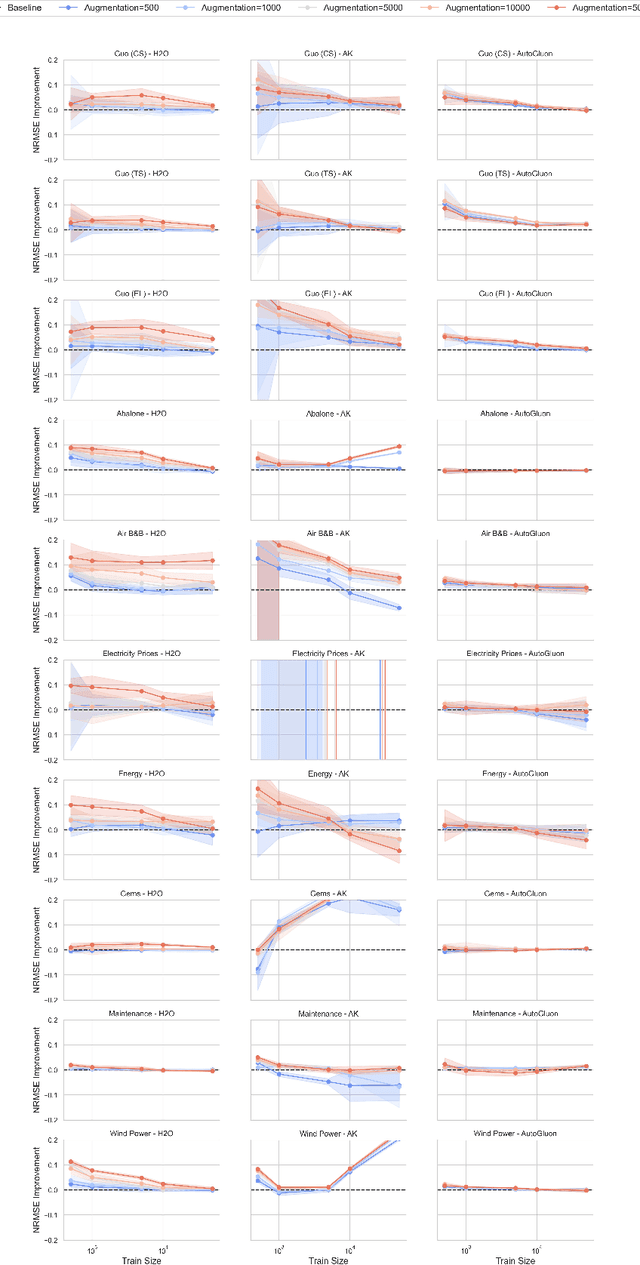
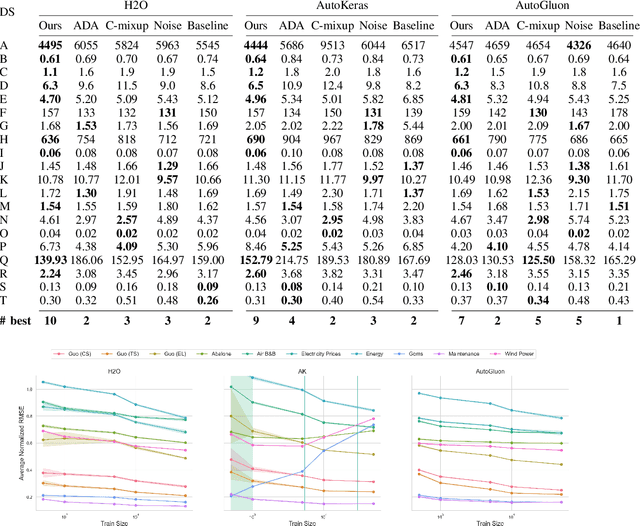
Deep learning (DL) models have gained prominence in domains such as computer vision and natural language processing but remain underutilized for regression tasks involving tabular data. In these cases, traditional machine learning (ML) models often outperform DL models. In this study, we propose and evaluate various data augmentation (DA) techniques to improve the performance of DL models for tabular data regression tasks. We compare the performance gain of Neural Networks by different DA strategies ranging from a naive method of duplicating existing observations and adding noise to a more sophisticated DA strategy that preserves the underlying statistical relationship in the data. Our analysis demonstrates that the advanced DA method significantly improves DL model performance across multiple datasets and regression tasks, resulting in an average performance increase of over 10\% compared to baseline models without augmentation. The efficacy of these DA strategies was rigorously validated across 30 distinct datasets, with multiple iterations and evaluations using three different automated deep learning (AutoDL) frameworks: AutoKeras, H2O, and AutoGluon. This study demonstrates that by leveraging advanced DA techniques, DL models can realize their full potential in regression tasks, thereby contributing to broader adoption and enhanced performance in practical applications.
Global Lightning-Ignited Wildfires Prediction and Climate Change Projections based on Explainable Machine Learning Models
Sep 16, 2024Wildfires pose a significant natural disaster risk to populations and contribute to accelerated climate change. As wildfires are also affected by climate change, extreme wildfires are becoming increasingly frequent. Although they occur less frequently globally than those sparked by human activities, lightning-ignited wildfires play a substantial role in carbon emissions and account for the majority of burned areas in certain regions. While existing computational models, especially those based on machine learning, aim to predict lightning-ignited wildfires, they are typically tailored to specific regions with unique characteristics, limiting their global applicability. In this study, we present machine learning models designed to characterize and predict lightning-ignited wildfires on a global scale. Our approach involves classifying lightning-ignited versus anthropogenic wildfires, and estimating with high accuracy the probability of lightning to ignite a fire based on a wide spectrum of factors such as meteorological conditions and vegetation. Utilizing these models, we analyze seasonal and spatial trends in lightning-ignited wildfires shedding light on the impact of climate change on this phenomenon. We analyze the influence of various features on the models using eXplainable Artificial Intelligence (XAI) frameworks. Our findings highlight significant global differences between anthropogenic and lightning-ignited wildfires. Moreover, we demonstrate that, even over a short time span of less than a decade, climate changes have steadily increased the global risk of lightning-ignited wildfires. This distinction underscores the imperative need for dedicated predictive models and fire weather indices tailored specifically to each type of wildfire.
A Comprehensive Benchmark of Machine and Deep Learning Across Diverse Tabular Datasets
Aug 27, 2024
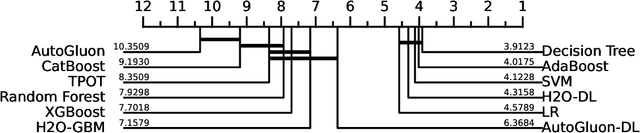

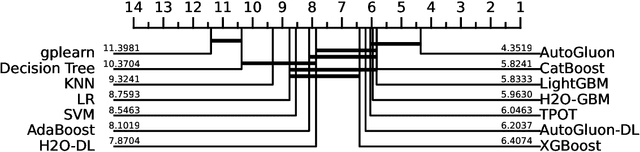
The analysis of tabular datasets is highly prevalent both in scientific research and real-world applications of Machine Learning (ML). Unlike many other ML tasks, Deep Learning (DL) models often do not outperform traditional methods in this area. Previous comparative benchmarks have shown that DL performance is frequently equivalent or even inferior to models such as Gradient Boosting Machines (GBMs). In this study, we introduce a comprehensive benchmark aimed at better characterizing the types of datasets where DL models excel. Although several important benchmarks for tabular datasets already exist, our contribution lies in the variety and depth of our comparison: we evaluate 111 datasets with 20 different models, including both regression and classification tasks. These datasets vary in scale and include both those with and without categorical variables. Importantly, our benchmark contains a sufficient number of datasets where DL models perform best, allowing for a thorough analysis of the conditions under which DL models excel. Building on the results of this benchmark, we train a model that predicts scenarios where DL models outperform alternative methods with 86.1% accuracy (AUC 0.78). We present insights derived from this characterization and compare these findings to previous benchmarks.
Generating Tables from the Parametric Knowledge of Language Models
Jun 16, 2024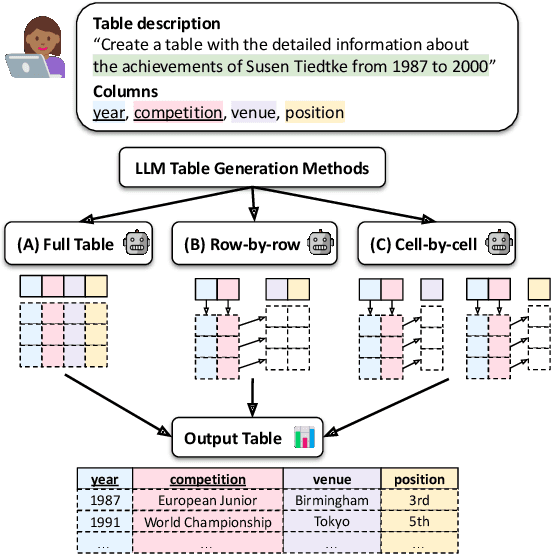
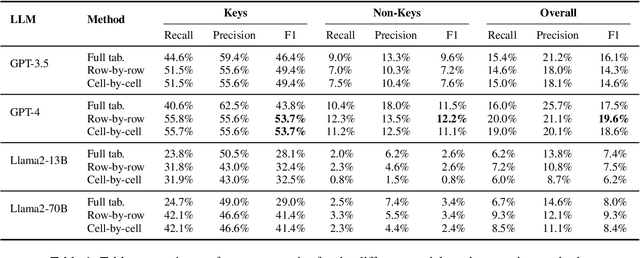
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
Embedded Hyperspectral Band Selection with Adaptive Optimization for Image Semantic Segmentation
Jan 21, 2024



Hyperspectral band selection plays a pivotal role in remote sensing and image analysis, aiming to identify the most informative spectral bands while minimizing computational overhead. In this paper, we introduce a pioneering approach for hyperspectral band selection that offers an embedded solution, making it well-suited for resource-constrained or real-time applications. Our proposed method, embedded Hyperspectral Band Selection (EHBS), excels in selecting the best bands without the need for prior processing, seamlessly integrating with the downstream task model. This is achieved through the adaptation of the Stochastic Gates (STG) algorithm, originally designed for feature selection, for hyperspectral band selection in the context of image semantic segmentation and the integration of a dynamic optimizer, DoG, which removes the need for the required tuning the learning rate. To assess the performance of our method, we introduce a novel metric for evaluating band selection methods across different target numbers of selected bands quantified by the Area Under the Curve (AUC). We conduct experiments on two distinct semantic-segmentation hyperspectral benchmark datasets, demonstrating its superiority in terms of its resulting accuracy and its ease of use compared to many common and state-of-the-art methods. Furthermore, our contributions extend beyond the realm of hyperspectral band selection. The adaptability of our approach to other tasks, especially those involving grouped features, opens up promising avenues for broader applications within the realm of deep learning, such as feature selection for feature groups. The demonstrated success on the tested datasets and the potential for application to a variety of tasks underscore the value of our method as a substantial addition to the field of computer vision.
Symbolic Regression as Feature Engineering Method for Machine and Deep Learning Regression Tasks
Nov 10, 2023In the realm of machine and deep learning regression tasks, the role of effective feature engineering (FE) is pivotal in enhancing model performance. Traditional approaches of FE often rely on domain expertise to manually design features for machine learning models. In the context of deep learning models, the FE is embedded in the neural network's architecture, making it hard for interpretation. In this study, we propose to integrate symbolic regression (SR) as an FE process before a machine learning model to improve its performance. We show, through extensive experimentation on synthetic and real-world physics-related datasets, that the incorporation of SR-derived features significantly enhances the predictive capabilities of both machine and deep learning regression models with 34-86% root mean square error (RMSE) improvement in synthetic datasets and 4-11.5% improvement in real-world datasets. In addition, as a realistic use-case, we show the proposed method improves the machine learning performance in predicting superconducting critical temperatures based on Eliashberg theory by more than 20% in terms of RMSE. These results outline the potential of SR as an FE component in data-driven models.
Acquiring Lexical Paraphrases from a Single Corpus
Dec 25, 2003

This paper studies the potential of identifying lexical paraphrases within a single corpus, focusing on the extraction of verb paraphrases. Most previous approaches detect individual paraphrase instances within a pair (or set) of comparable corpora, each of them containing roughly the same information, and rely on the substantial level of correspondence of such corpora. We present a novel method that successfully detects isolated paraphrase instances within a single corpus without relying on any a-priori structure and information. A comparison suggests that an instance-based approach may be combined with a vector based approach in order to assess better the paraphrase likelihood for many verb pairs.