 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Deep Learning Regression Tasks by Machine Learning Models
Jan 07, 2025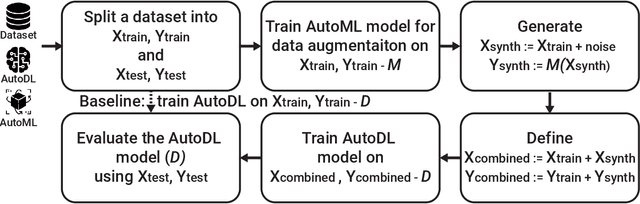
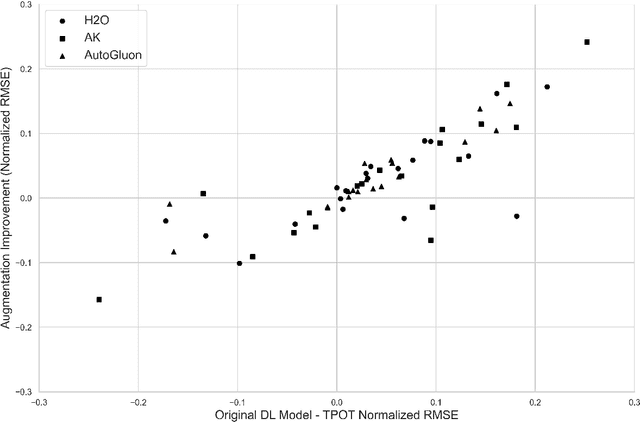
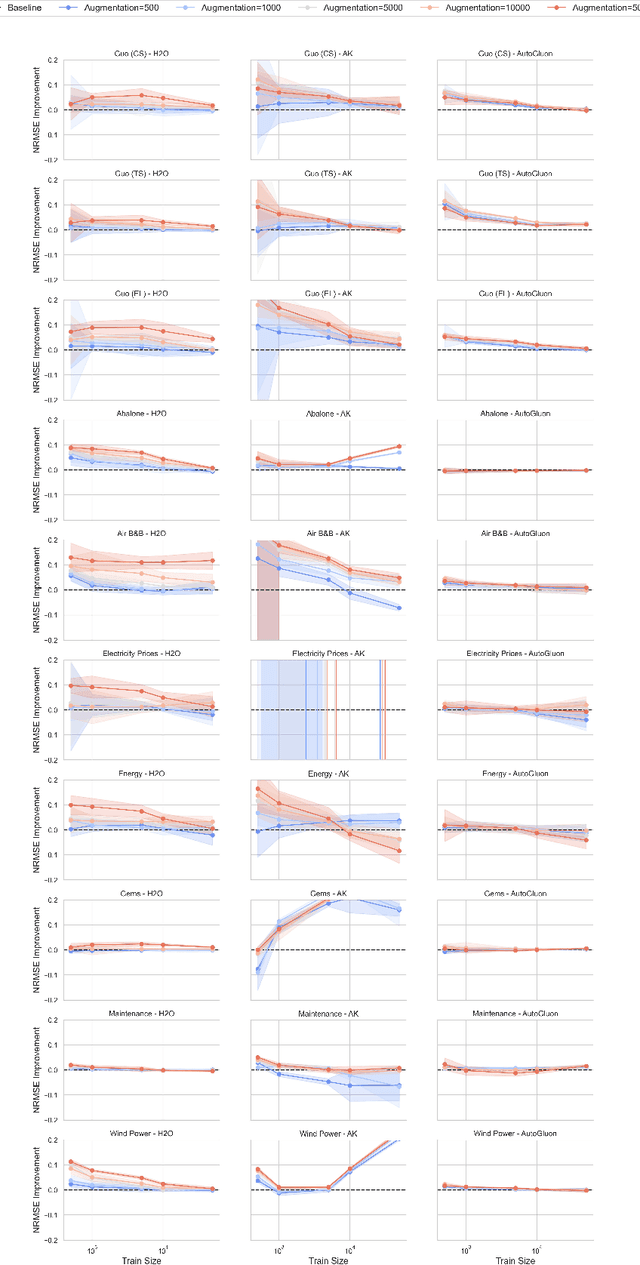
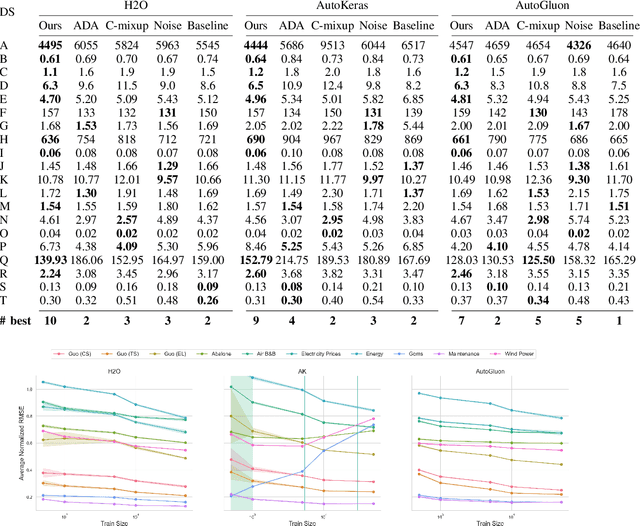
Deep learning (DL) models have gained prominence in domains such as computer vision and natural language processing but remain underutilized for regression tasks involving tabular data. In these cases, traditional machine learning (ML) models often outperform DL models. In this study, we propose and evaluate various data augmentation (DA) techniques to improve the performance of DL models for tabular data regression tasks. We compare the performance gain of Neural Networks by different DA strategies ranging from a naive method of duplicating existing observations and adding noise to a more sophisticated DA strategy that preserves the underlying statistical relationship in the data. Our analysis demonstrates that the advanced DA method significantly improves DL model performance across multiple datasets and regression tasks, resulting in an average performance increase of over 10\% compared to baseline models without augmentation. The efficacy of these DA strategies was rigorously validated across 30 distinct datasets, with multiple iterations and evaluations using three different automated deep learning (AutoDL) frameworks: AutoKeras, H2O, and AutoGluon. This study demonstrates that by leveraging advanced DA techniques, DL models can realize their full potential in regression tasks, thereby contributing to broader adoption and enhanced performance in practical applications.
Global Lightning-Ignited Wildfires Prediction and Climate Change Projections based on Explainable Machine Learning Models
Sep 16, 2024Wildfires pose a significant natural disaster risk to populations and contribute to accelerated climate change. As wildfires are also affected by climate change, extreme wildfires are becoming increasingly frequent. Although they occur less frequently globally than those sparked by human activities, lightning-ignited wildfires play a substantial role in carbon emissions and account for the majority of burned areas in certain regions. While existing computational models, especially those based on machine learning, aim to predict lightning-ignited wildfires, they are typically tailored to specific regions with unique characteristics, limiting their global applicability. In this study, we present machine learning models designed to characterize and predict lightning-ignited wildfires on a global scale. Our approach involves classifying lightning-ignited versus anthropogenic wildfires, and estimating with high accuracy the probability of lightning to ignite a fire based on a wide spectrum of factors such as meteorological conditions and vegetation. Utilizing these models, we analyze seasonal and spatial trends in lightning-ignited wildfires shedding light on the impact of climate change on this phenomenon. We analyze the influence of various features on the models using eXplainable Artificial Intelligence (XAI) frameworks. Our findings highlight significant global differences between anthropogenic and lightning-ignited wildfires. Moreover, we demonstrate that, even over a short time span of less than a decade, climate changes have steadily increased the global risk of lightning-ignited wildfires. This distinction underscores the imperative need for dedicated predictive models and fire weather indices tailored specifically to each type of wildfire.
A Comprehensive Benchmark of Machine and Deep Learning Across Diverse Tabular Datasets
Aug 27, 2024
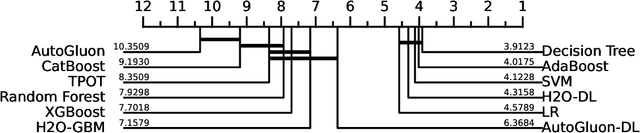

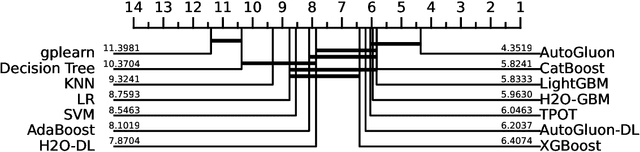
The analysis of tabular datasets is highly prevalent both in scientific research and real-world applications of Machine Learning (ML). Unlike many other ML tasks, Deep Learning (DL) models often do not outperform traditional methods in this area. Previous comparative benchmarks have shown that DL performance is frequently equivalent or even inferior to models such as Gradient Boosting Machines (GBMs). In this study, we introduce a comprehensive benchmark aimed at better characterizing the types of datasets where DL models excel. Although several important benchmarks for tabular datasets already exist, our contribution lies in the variety and depth of our comparison: we evaluate 111 datasets with 20 different models, including both regression and classification tasks. These datasets vary in scale and include both those with and without categorical variables. Importantly, our benchmark contains a sufficient number of datasets where DL models perform best, allowing for a thorough analysis of the conditions under which DL models excel. Building on the results of this benchmark, we train a model that predicts scenarios where DL models outperform alternative methods with 86.1% accuracy (AUC 0.78). We present insights derived from this characterization and compare these findings to previous benchmarks.
Symbolic Regression as Feature Engineering Method for Machine and Deep Learning Regression Tasks
Nov 10, 2023In the realm of machine and deep learning regression tasks, the role of effective feature engineering (FE) is pivotal in enhancing model performance. Traditional approaches of FE often rely on domain expertise to manually design features for machine learning models. In the context of deep learning models, the FE is embedded in the neural network's architecture, making it hard for interpretation. In this study, we propose to integrate symbolic regression (SR) as an FE process before a machine learning model to improve its performance. We show, through extensive experimentation on synthetic and real-world physics-related datasets, that the incorporation of SR-derived features significantly enhances the predictive capabilities of both machine and deep learning regression models with 34-86% root mean square error (RMSE) improvement in synthetic datasets and 4-11.5% improvement in real-world datasets. In addition, as a realistic use-case, we show the proposed method improves the machine learning performance in predicting superconducting critical temperatures based on Eliashberg theory by more than 20% in terms of RMSE. These results outline the potential of SR as an FE component in data-driven models.